文章目录
官方代码 https://github.com/mibastro/VPE
0. 准备
- 数据集
在README.md文件里给出了数据集的地址,下载下来解压即可。
也可以百度云下载
链接:https://pan.baidu.com/s/1-4E-ixSuhpQ9r-LX3DAZGA
提取码:f1xw
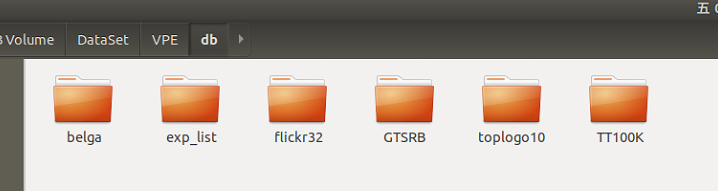
然后修改修改code/config.json文件中的路径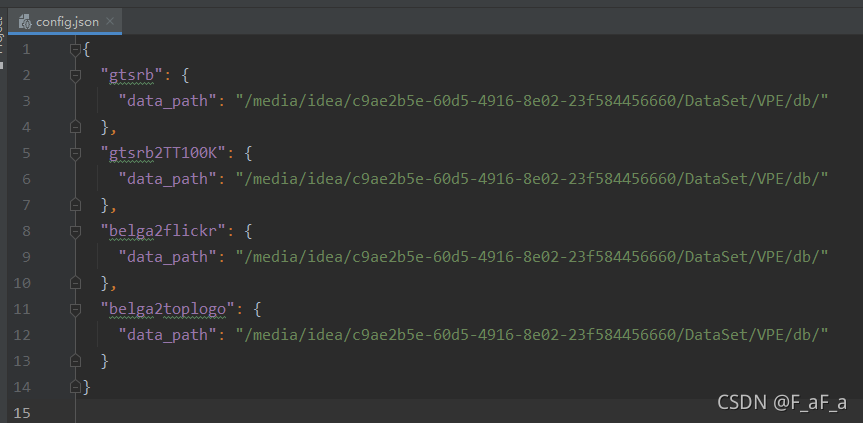
-
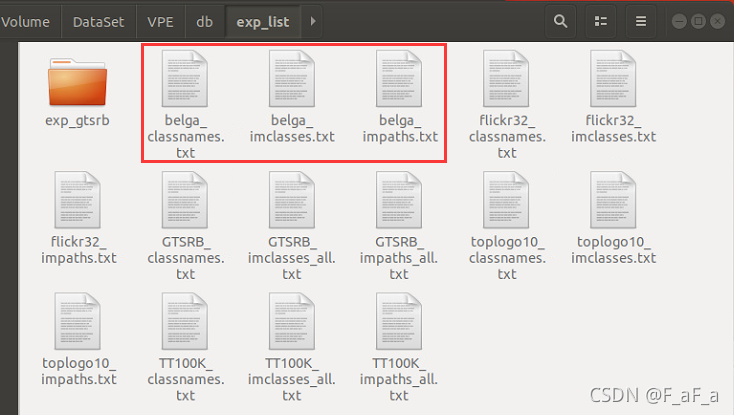
数据集下面有个
exp_list文件夹,下面存放了每个数据集的图片标签、图片路径和图片类名。以belga为例,分别为belge_classnames.txt图片类名belge_impaths.txt图片路径belge_imclasses.txt图片标签
-
将code/loader/belga2flickr.py line4如果报错可以修改环境,参考自如何解决:module ‘scipy.misc’ has no attribute ‘imread’
-
code/main_train_val_test.py的前81行主要是导包和日志文件的准备
1. 数据
pytorch准备数据两部曲:
- 创建自己的
Dataset类 - 用类创建数据集对象
- 给
torch.utils.data.DataLoader传Dataset类创建的对象,设置batch_size等
先根据设置的参数,选择合适的Dataset类和数据库所在的路径。虽然变量名为data_loader,本质为pytorch里的Dataset.
然后在line87-line89创建对应训练、测试和验证的Dataset类对象.
在line91-93创建对应训练、测试和验证的DataLoader类对象.
2. 模型
在line97根据参数建立模型:def get_model(name, n_classes=None):,用于生成VAEIdsia类的参数为:
nc=3模型的输入数据为3通道input_size=64模型的输入数据为64*64latent_variable_size=300模型将输入数据encoder成300维的向量cnn_chn=[100, 150, 250]三个卷积层的前2个参数:- 第1层 3 -> 100通道
- 第2层 100 -> 150通道
- 第3层 150 -> 250通道
param1=[200, 300, 200]、param2=None、param3=[150, 150, 150]分别为三个stn也就是spatial transformer network,用于在卷积之前对图片进行空间变换。
def get_model(name, n_classes=None):
model = _get_model_instance(name)
if name is 'vaeIdsiaStn':
model = model(nc=3, input_size=64, latent_variable_size=300, cnn_chn=[100, 150, 250], param1=[200, 300, 200],
param2=None, param3=[150, 150, 150]) # idsianet cnn_chn=[100,150,250] latent = 300
print('Use vae+Idsianet (stn1 + stn3) with random initialization!')
if name is 'vaeIdsia':
model = model(nc=3, input_size=64, latent_variable_size=300, cnn_chn=[100, 150, 250], param1=None, param2=None,
param3=None) # idsianet cnn_chn=[100,150,250] latent = 300
print('Use vae+Idsianet (without stns) with random initialization!')
return model
code/models/vaeIdsiaStn.py下的VAEIdsia模型的forward函数包括三个函数
- encoder函数将shape为
128, 3, 64, 64的x编码成- 均值
mu:shape为(128,300) - l o g ( 标 准 差 2 ) log(标准差^2) log(标准差2)
logvar:shape为(128,300) - 空间变换后的图片
xstn:shape为(128,3,64,64)
- 均值
- reparametrize函数函数 需要
encoder函数产生的均值mu和 l o g ( 标 准 差 2 ) log(标准差^2) log(标准差2)logvar来生成正态分,然后从中随机采样,返回的zshape为(128,300) - decoder函数将
reparametrize函数的特征转换为图片,shape为([128, 3, 64, 64])
3.训练
在main函数里进行args.epochs次循环,对模型进行训练、验证和测试,并保存最好的模型。
for e in range(1, args.epochs + 1):
val_trigger = False
train(e)
temp_acc_val = validation(e, best_acc_val)
if temp_acc_val > best_acc_val:
best_acc_val = temp_acc_val
val_trigger = True # force test function to save log when validation performance is updated
best_acc = test(e, best_acc, val_trigger)
由于train、validation、test函数大同小异,所以详细讲下train函数
模型训练
for i, (input, target, template) in enumerate(trainloader):
# input.shape->(128,3,64,64)
# target.shape->(128,1)
# template.shape->(128,3,64,64)
optimizer.zero_grad()
target = torch.squeeze(target) # target.shape->(128)
input, template = input.cuda(async=True), template.cuda(async=True)
# 恢复的图片, 均值,log(标准差的平方),空间变换后的x
recon, mu, logvar, input_stn = net(input)
# ([128, 3, 64, 64]) (128,300) (128,300) (128,3,64,64)
loss = loss_function(recon, template, mu, logvar) # 计算损失
print('Epoch:%d Batch:%d/%d loss:%08f' % (e, i, batch_iter, loss / input.numel()))
# 写入文件
f_loss = open(os.path.join(result_path, "log_loss.txt"), 'a')
f_loss.write('Epoch:%d Batch:%d/%d loss:%08f\n' % (e, i, batch_iter, loss / input.numel()))
f_loss.close()
# 损失函数&优化器
loss.backward()
optimizer.step()
损失函数
损失函数定义在line107,包括两个部分:
-
KL散度KLD,关于两个正态分布的KL散度可以看两个高斯分布之间的KL散度,也就是 K L ( N ( μ , σ ) ∥ N ( 0 , 1 ) ) = 1 2 ( − log σ 2 + μ 2 + σ 2 − 1 ) K L(N(\mu, \sigma) \| N(0,1))=\frac{1}{2}\left(-\log \sigma^{2}+\mu^{2}+\sigma^{2}-1\right) KL(N(μ,σ)∥N(0,1))=21(−logσ2+μ2+σ2−1)
优化器
模型使用的Adam优化器
optimizer = optim.Adam(net.parameters(), lr=args.lr) # 1e-4
4.score_NN函数计算模型准确度
这个模型主要在validation和test的时候调用,计算模型在跨数据集上的预测准确度。