拉勾网
import time
from selenium import webdriver
from lxml import etree
import re
from pymongo import MongoClient
class LaGou:
def __init__(self):
self.url = "https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput="
self.driver = webdriver.Chrome()
self.positions = []
self.client = MongoClient()
self.collection = self.client['spider']['job']
def run(self):
self.driver.get(self.url)
while True:
page_source = self.driver.page_source
self.parse_list_source(page_source)
next = self.driver.find_element_by_class_name('pager_next ')
if "pager_next pager_next_disabled" not in next.get_attribute('class'):
self.driver.execute_script("arguments[0].click();", next)
else:
break
def parse_list_source(self, page_source):
html = etree.HTML(page_source)
position_detail_urls = html.xpath("//a[@class='position_link']/@href")
for position_detail_url in position_detail_urls:
self.parse_detail_source(position_detail_url)
def parse_detail_source(self, position_detail_url):
self.driver.execute_script("window.open('{}')".format(position_detail_url))
self.driver.switch_to.window(self.driver.window_handles[1])
html = etree.HTML(self.driver.page_source)
company = html.xpath('//h4[@class="company"]/text()')[0]
name = html.xpath("//h1[@class='name']/text()")[0]
salary = html.xpath("//dd[@class='job_request']//span")[0].xpath(".//text()")[0]
address = html.xpath("//dd[@class='job_request']//span")[1].xpath(".//text()")[0]
address = re.sub(r"[/' ']", '', address).strip()
experience = html.xpath("//dd[@class='job_request']//span")[2].xpath(".//text()")[0]
experience = re.sub(r"[/' ']", '', experience).strip()
education = html.xpath("//dd[@class='job_request']//span")[3].xpath(".//text()")[0]
education = re.sub(r"[/' ']", '', education).strip()
category = html.xpath("//dd[@class='job_request']//span")[4].xpath(".//text()")[0]
category = re.sub(r"[/' ']", '', category).strip()
job_detail = ''.join(html.xpath("//div[@class='job-detail']//text()"))
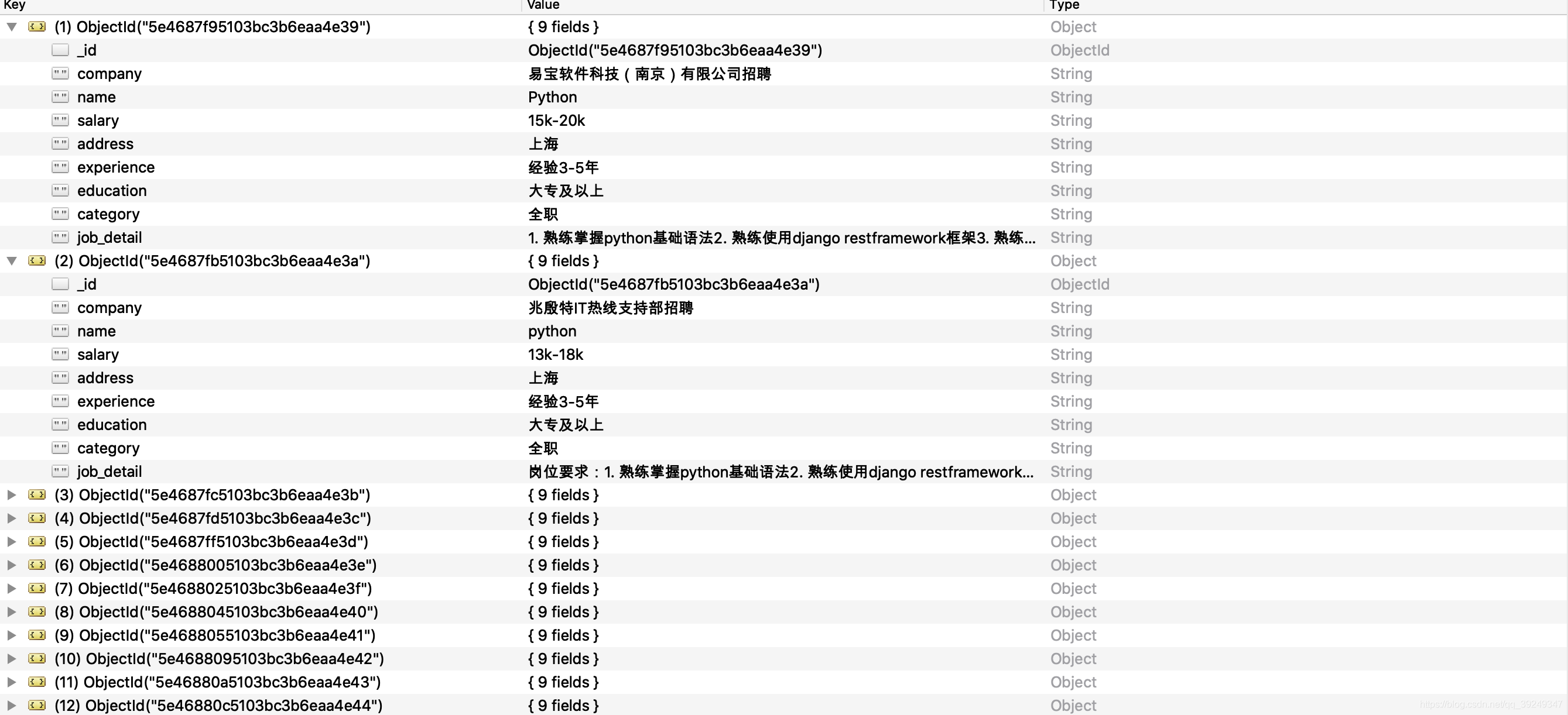
position = {}
position['company'] = company
position['name'] = name
position['salary'] = salary
position['address'] = address
position['experience'] = experience
position['education'] = education
position['category'] = category
position['job_detail'] = job_detail
self.positions.append(position)
self.collection.insert_one(position)
print(position)
print('*' * 30)
self.driver.close()
self.driver.switch_to.window(self.driver.window_handles[0])
L = LaGou()
L.run()
