request.Request类
如果想要在请求的时候添加一个请求头(增加请求头的原因是,如果不加请求头,那么在我们爬取得时候,可能会被限制),那么就必须使用request.Request类来实现,比如要增加一个User-Agent,
url='https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=' headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0' } req=request.Request(url,headers=headers) resp=request.urlopen(req) print(resp.read())
这样就可以爬取下来这个网站所有得信息:
拉勾网得反爬虫设计的非常好,在我们现在打开的页面:
我们刚刚爬取得只是这个页面得信息,里面得职位信息是没有得,这些职位信息在另外得一个jsp里,通过调用得形式在这个页面显示出来
我们获取职位信息得网址
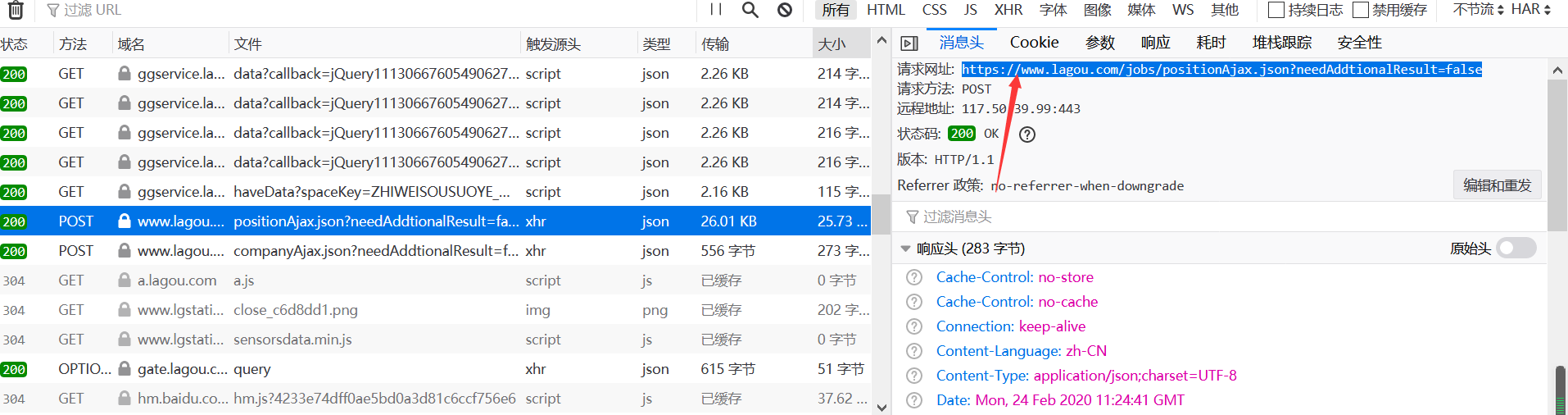

请求方法为POST;
url='https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false' headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0' } data ={ 'first':'true', 'pn':1, 'kd':'python' } req=request.Request(url,headers=headers,data=data,method='POST') resp=request.urlopen(req) print(resp.read())
结果为:

报错得原因是data也需要urlencode来传,同时也要是bytes得形式(encode('utf-8'))
还需要对请求头再次进行伪装,此时得请求头为:
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Referer': 'https://www.lagou.com/jobs/list_%E8%BF%90%E7%BB%B4?city=%E6%88%90%E9%83%BD&cl=false&fromSearch=true&labelWords=&suginput=',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
所以请求头就是在网站里右键,点击查看元素,然后选择网络,选择User-Agent和Referer里面得网址
url='https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Referer': 'https://www.lagou.com/jobs/list_%E8%BF%90%E7%BB%B4?city=%E6%88%90%E9%83%BD&cl=false&fromSearch=true&labelWords=&suginput=',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
data ={ 'first':'true', 'pn':1, 'kd':'python' }
req=request.Request(url,headers=headers,data=parse.urlencode(data).encode('utf-8'),method='POST')
resp=request.urlopen(req)
print(resp.read().decode('utf-8'))
这时会出现“您的操作太频繁,请稍后重试”的提示,是因为网站已经发现了有人正在爬取而进行的提示。
我们在代码中添加与post和相关的cookie来请求
例如:爬取成都与运维相关的工作
import requests import time import json def main(): url_start = "https://www.lagou.com/jobs/list_运维?city=%E6%88%90%E9%83%BD&cl=false&fromSearch=true&labelWords=&suginput=" url_parse = "https://www.lagou.com/jobs/positionAjax.json?city=成都&needAddtionalResult=false" headers = { 'Accept': 'application/json, text/javascript, */*; q=0.01', 'Referer': 'https://www.lagou.com/jobs/list_%E8%BF%90%E7%BB%B4?city=%E6%88%90%E9%83%BD&cl=false&fromSearch=true&labelWords=&suginput=', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36' } for x in range(1, 5): data = { 'first': 'true', 'pn': str(x), 'kd': '运维' } s = requests.Session() s.get(url_start, headers=headers, timeout=3) # 请求首页获取cookies cookie = s.cookies # 为此次获取的cookies response = s.post(url_parse, data=data, headers=headers, cookies=cookie, timeout=3) # 获取此次文本 time.sleep(5) response.encoding = response.apparent_encoding text = json.loads(response.text) info = text["content"]["positionResult"]["result"] for i in info: print(i["companyFullName"]) companyFullName = i["companyFullName"] print(i["positionName"]) positionName = i["positionName"] print(i["salary"]) salary = i["salary"] print(i["companySize"]) companySize = i["companySize"] print(i["skillLables"]) skillLables = i["skillLables"] print(i["createTime"]) createTime = i["createTime"] print(i["district"]) district = i["district"] print(i["stationname"]) stationname = i["stationname"] if __name__ == '__main__': main()
