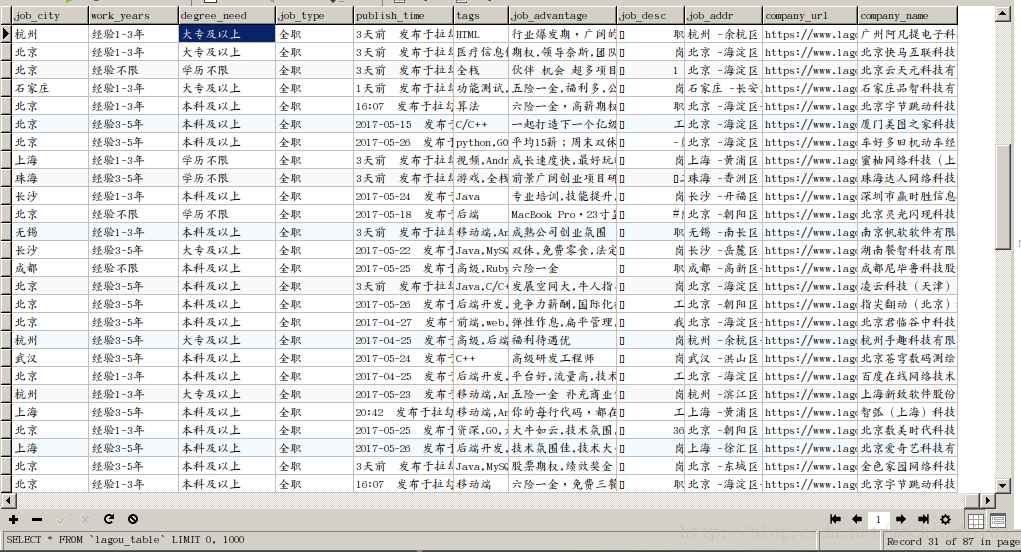
今天使用scrapy实现了一个爬取拉勾网上的职位信息字段,并保存到数据库的爬虫,先看下效果:
导出json格式如下:

创建Spider
之前在创建spider的时候,都是使用有genspider默认创建的spider类型,可以通过下面命令查看当前scrapy支持哪些类型的spider

下面创建crawl类型的spider
scrapy genspider -t crawl lagou www.lagou.com
LinkExtractor和Rule的使用
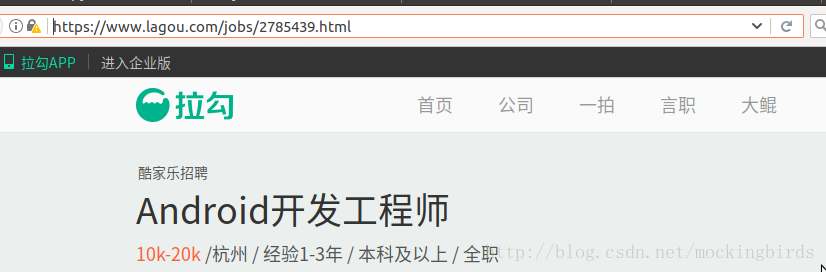
可以看到,对于职位详情的页面,是下面这样的链接
https://www.lagou.com/jobs/2785439.html另外,通过下面两种方式也可以进入职位详情页面:
https://www.lagou.com/gongsi/j9891.html
https://www.lagou.com/zhaopin/Java/?labelWords=labelLagouSpider
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class LagouSpider(CrawlSpider):
name = 'lagou'
allowed_domains = ['www.lagou.com']
start_urls = ['https://www.lagou.com/']
rules = (
#https://www.lagou.com/gongsi/j9891.html follow表示深度解析,即当前页面的所有子页面
Rule(LinkExtractor(allow=r'gongsi/j\d.html',), follow=True),
#https://www.lagou.com/zhaopin/Java/?labelWords=label
Rule(LinkExtractor(allow=r'zhaopin/.*',), follow=True),
#https://www.lagou.com/jobs/2785439.html 如果当前url是jobs/\d+.html格式的,则回调parse_item进行具体的解析动作
Rule(LinkExtractor(allow=r'jobs/\d+.html'), callback='parse_item', follow=True),
)
def parse_item(self, response):
#解析拉勾网职位
i = {}
return i定义职位信息LagouJobItem
在items.py中创建LagouJobItem
class LagouJobItem(scrapy.Item):
url = scrapy.Field()
title = scrapy.Field()
url_obj_id = scrapy.Field()
salary = scrapy.Field()
job_city = scrapy.Field()
work_years = scrapy.Field()
degree_need = scrapy.Field()
job_type = scrapy.Field()
publish_time = scrapy.Field()
tags = scrapy.Field()
job_advantage = scrapy.Field()
job_desc = scrapy.Field()
job_addr = scrapy.Field()
company_url = scrapy.Field()
company_name = scrapy.Field()
craw_time = scrapy.Field()
craw_update_time = scrapy.Field()定义LagouJobItemLoader
另外在items.py中定义LagouJobItemLoader
from scrapy.contrib.loader import ItemLoader
from scrapy.loader.processors import MapCompose, TakeFirst
class LagouJobItemLoader(ItemLoader):
default_output_processor = TakeFirst()
pass各个字段的获取
title的获取
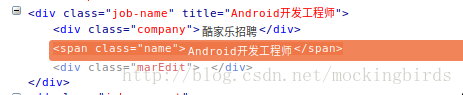
由于class=’job-name’在当前页面只存在一个,所以可以通过下面方式获取
scrapy shell https://www.lagou.com/jobs/2785439.html
response.css(".job-name span::text").extract()[0]
获取薪资
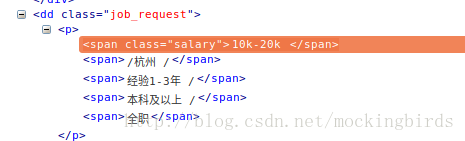
response.css(".job_request .salary ::text").extract()[0]获取工作城市
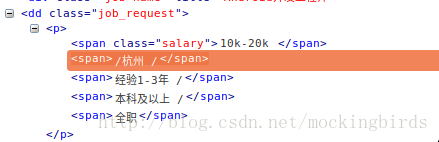
response.xpath('//dd[@class="job_request"]/p/span[2]/text()').extract()[0]获取职位标签
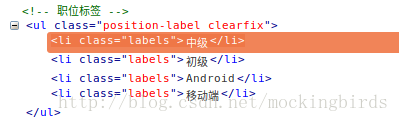
response.css('.position-label li::text').extract()获取发布时间

response.css('.publish_time::text').extract()[0]获取职位诱惑

response.css('.job-advantage p::text').extract()[0]职位要求

response.css('.job_bt div').extract()[0]工作地址

response.css('.work_addr').extract()[0]公司名称和url
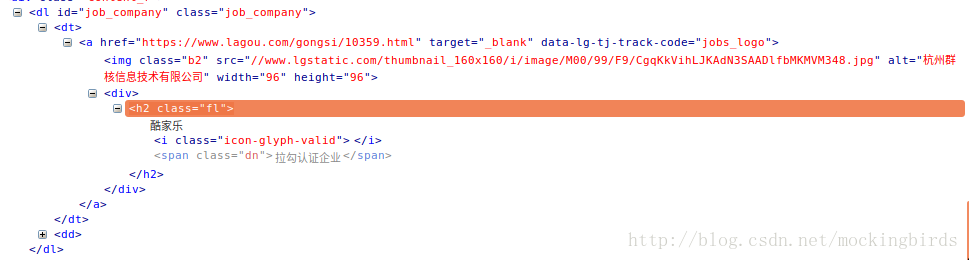
# 公司名称
response.css('.job_company img::attr(alt)').extract()[0]
# 公司url
response.css('.job_company a::attr(href)').extract()[0]
解析字段放入LagouJobItemLoader
def parse_item(self, response):
#解析拉勾网职位
lagouItemLoader = LagouJobItemLoader(item=LagouJobItem(), response=response)
lagouItemLoader.add_css('title', '.job-name span::text')
lagouItemLoader.add_value('url', response.url)
lagouItemLoader.add_value('url_obj_id', get_md5(response.url))
lagouItemLoader.add_css('salary', '.job_request .salary ::text')
lagouItemLoader.add_xpath('job_city', '//dd[@class="job_request"]/p/span[2]/text()')
lagouItemLoader.add_xpath('work_years', '//dd[@class="job_request"]/p/span[3]/text()')
lagouItemLoader.add_xpath('degree_need', '//dd[@class="job_request"]/p/span[4]/text()')
lagouItemLoader.add_xpath('job_type', '//dd[@class="job_request"]/p/span[5]/text()')
lagouItemLoader.add_css('tags', '.position-label li::text')
lagouItemLoader.add_css('publish_time', '.publish_time::text')
lagouItemLoader.add_css('job_advantage', '.job-advantage p::text')
lagouItemLoader.add_css('job_desc', '.job_bt div')
lagouItemLoader.add_css('job_addr', '.work_addr')
lagouItemLoader.add_css('company_url', '#job_company a::attr(href)')
lagouItemLoader.add_css('company_name', '#job_company img::attr(alt)')
lagouItemLoader.add_value('craw_time', datetime.datetime.now().date())
lagouJobItem = lagouItemLoader.load_item()
return lagouJobItem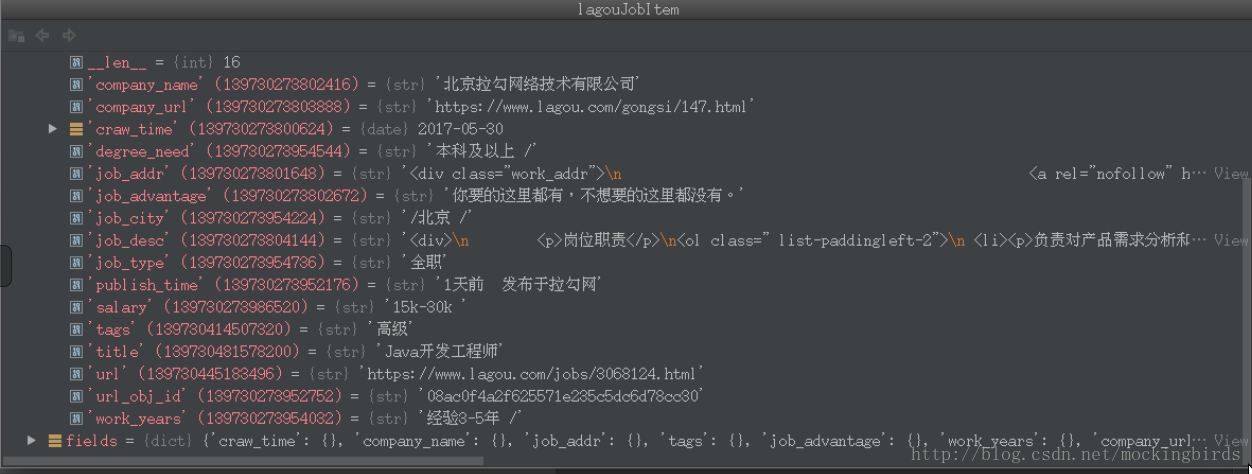
可以看到,已经正确获取到当前职位的的字段信息了
但是可以看到,上面的字段包括‘job_city’,’job_desc’,’job_addr’还包含一些标签需要处理,下面需要添加input_processor做处理
添加MyTwistedPipeline存储数据
from twisted.enterprise import adbapi
import MySQLdb.cursors
import MySQLdb
class MyTwistedPipeline(object):
def __init__(self, dbpool):
# 在执行完from_settings之后,将dbpool初始化
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):
dbparams = dict(
host=settings["MYSQL_HOST"],
port=settings["MYSQL_PORT"],
user=settings["MYSQL_USER"],
passwd=settings["MYSQL_PWD"],
db=settings["MYSQL_DB"],
charset=settings["MYSQL_CHARSET"],
use_unicode=settings["MYSQL_USER_UNICODE"],
cursorclass=MySQLdb.cursors.DictCursor,
)
# 这里通过adbapi构造一个dbpool,并传入MyTwistedPipeline的构造方法
dbpool = adbapi.ConnectionPool("MySQLdb", **dbparams)
return cls(dbpool)
def process_item(self, item, spider):
# 使用twisted异步插入数据到mysql
query = self.dbpool.runInteraction(self.insert_data, item)
query.addErrback(self.handle_error)
def handle_error(self,failure):
# 处理异步插入异常
print(failure)
def insert_data(self, cursor, item):
# 执行具体的插入
# 根据不同的item 构建不同的sql语句并插入到mysql中
insert_sql, params = item.get_insert_sql()
print(insert_sql, params)
cursor.execute(insert_sql, params)别忘了在settings.py中配置MyTwistedPipeline
ITEM_PIPELINES = {
'zhihu.pipelines.MyTwistedPipeline': 1,
}在input_processor中处理字段值
from scrapy.loader.processors import MapCompose, TakeFirst, Join
from w3lib.html import remove_tags
# 移除'/广州 / 经验3-5年 / 本科及以上 /'中的/
def replace_splash(value):
return value.replace("/", "")
# 工作地址的处理 ‘广州 - 天河区 - 天河城 - 体育中心103号维多利广场B塔32F 查看地图’
def handle_jobaddr(value):
addr_list = value.split("\n")
addr_list = [item.strip() for item in addr_list if item.strip() != "查看地图"]
return "".join(addr_list)
class LagouJobItem(scrapy.Item):
url = scrapy.Field()
title = scrapy.Field()
url_obj_id = scrapy.Field()
salary = scrapy.Field()
job_city = scrapy.Field(
input_processor=MapCompose(replace_splash)
)
work_years = scrapy.Field(
input_processor=MapCompose(replace_splash)
)
degree_need = scrapy.Field(
input_processor=MapCompose(replace_splash)
)
job_type = scrapy.Field()
publish_time = scrapy.Field()
tags = scrapy.Field(
input_processor=Join(',')
)
job_advantage = scrapy.Field()
job_desc = scrapy.Field(
# 移除html标签
input_processor=MapCompose(remove_tags)
)
job_addr = scrapy.Field(
input_processor=MapCompose(remove_tags, handle_jobaddr)
)
company_url = scrapy.Field()
company_name = scrapy.Field()
craw_time = scrapy.Field()
craw_update_time = scrapy.Field()
#重写get_insert_sql方法,该方法会在MyTwistedPipeline中调用,执行存储操作,ON DUPLICATE KEY UPDATE 表示如果主键冲突,则不进行插入操作,执行更新职位描述操作
def get_insert_sql(self):
insert_sql = """
insert into lagou_table(url, url_obj_id, title, salary, job_city,
work_years, degree_need, job_type, publish_time, tags, job_advantage,
job_desc, job_addr, company_url, company_name
) values (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s) ON DUPLICATE KEY UPDATE job_desc=VALUES(job_desc)
"""
params = (
self['url'], self['url_obj_id'], self['title'], self['salary'] , self['job_city'],
self['work_years'], self['degree_need'], self['job_type'], self['publish_time'],
self['tags'], self['job_advantage'],self['job_desc'], self['job_addr'],
self['company_url'], self['company_name']
)
return insert_sql, params添加RandomUserAgentMiddleware
另外,当爬取拉钩网的信息稍微一会,就会出现被forbidden的情况,可以使用RandomUserAgentMiddleware保证使用随机代理
这里,使用的是fake_useragent,没有的话,需要先pip install
sudo pip3 install fake-useragent在middlewares.py中创建RandomUserAgentMiddleware类
在settings.py中添加RANDOM_UA_TYPE设置选项
RANDOM_UA_TYPE = 'random' #表示随机设置user-agentfrom fake_useragent import UserAgent
class RandomUserAgentMiddleware(object):
def __init__(self, crawler):
super(RandomUserAgentMiddleware, self).__init__()
self.ua = UserAgent()
self.ua_type = crawler.settings.get('RANDOM_UA_TYPE', 'random')
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def process_request(self, request, spider):
def get_ua():
'''Gets random UA based on the type setting (random, firefox…)'''
return getattr(self.ua, self.ua_type)
request.headers.setdefault('User-Agent', get_ua())在settings.py中配置RandomUserAgentMiddleware
DOWNLOADER_MIDDLEWARES = {
'zhihu.middlewares.RandomUserAgentMiddleware': 400,
}
此时运行结果如下: