前言:拉勾网是一家专为拥有3至10年工作经验的资深互联网从业者,提供工作机会的招聘网站。拉勾网数据爬取是一个蛮经典的爬虫案例 ,由于被频繁被爬取的原因 ,网站经过不断更新 ,加入了一些反爬技术 。例如:参数的加密 、AJAX异步加载JSON数据 。对于入门爬虫的新手来说 ,还是有一些挑战困难 。我在刚入门python爬虫时也对它束手无策,总是提醒说访问频繁,后来学会selenium模拟人工操作,第一次拿到拉勾的职位信息,但是它的速度太慢,也不能算是真正的网络爬虫,后来学会了resquests库模拟客户端,今天就来写一下吧,希望能够帮助到你!
一、使用selenium获取拉勾网职位信息
有需要的话可以看一下: selenium+lxml爬取(查询)拉勾网职位信息 ,但是我今天的重点是requests,所以其他的就不重述了,直接开始吧,需要登机的赶快了!
二、使用requests获取拉勾网职位信息
1、我们先来分析数据的加载方式吧
搜索职位信息后,我发现它是AJAX异步加载JSON数据 ,怎么快速的找到它传输数据的接口呢?
通常都是最大的一个文件,如图:
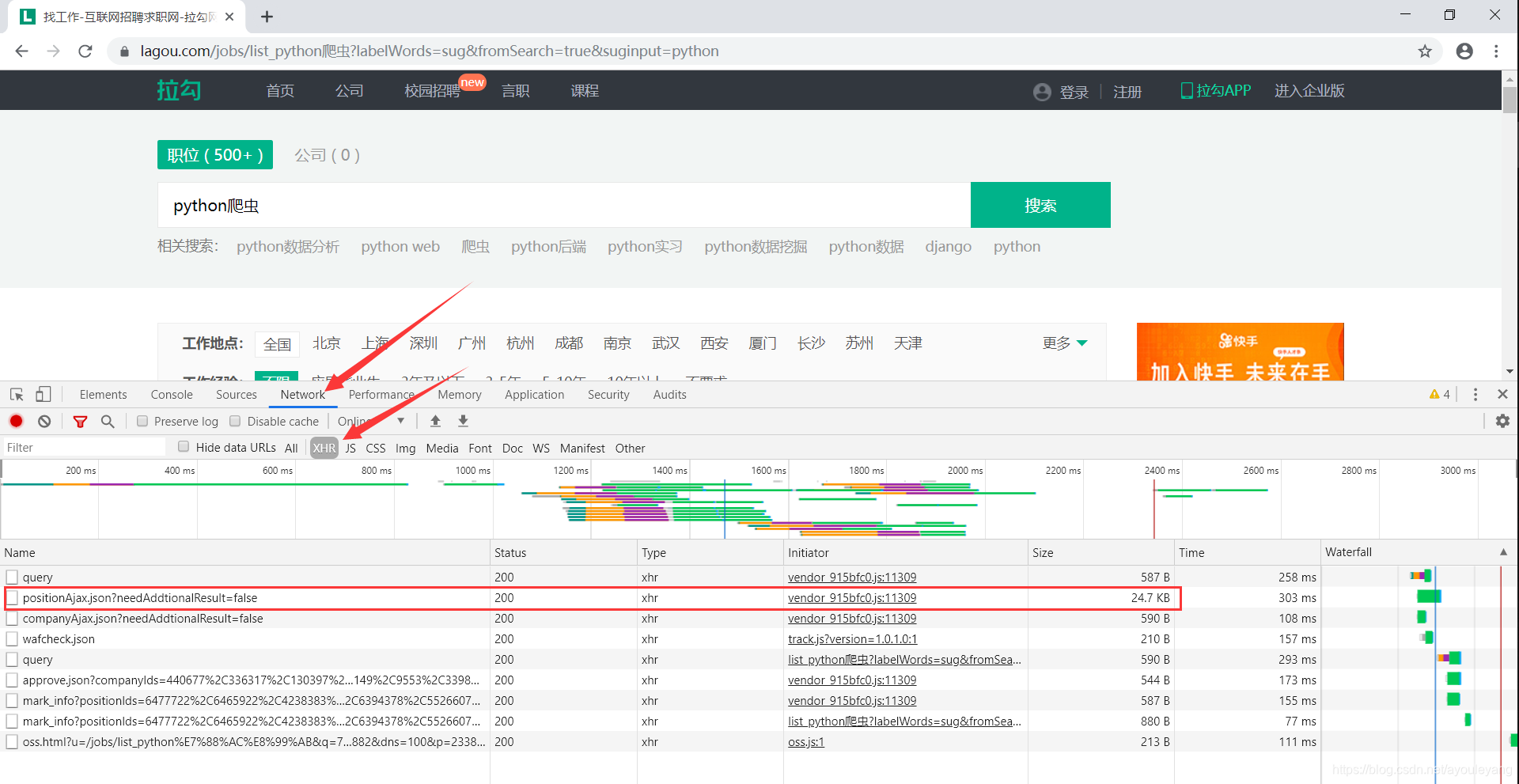
检验一下:
1)点击它——> 右击 ——> copy ——> copy link address,粘贴在浏览器打开
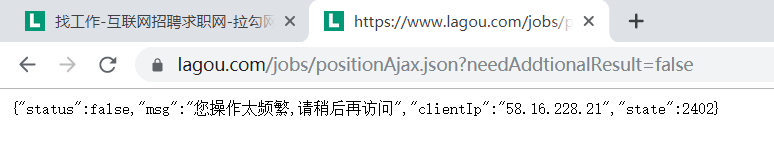
操作太频繁? 不对不对,换一个方法检验emmm… …
2)点击文件后——>点击Response——>Ctrl+F(查找)
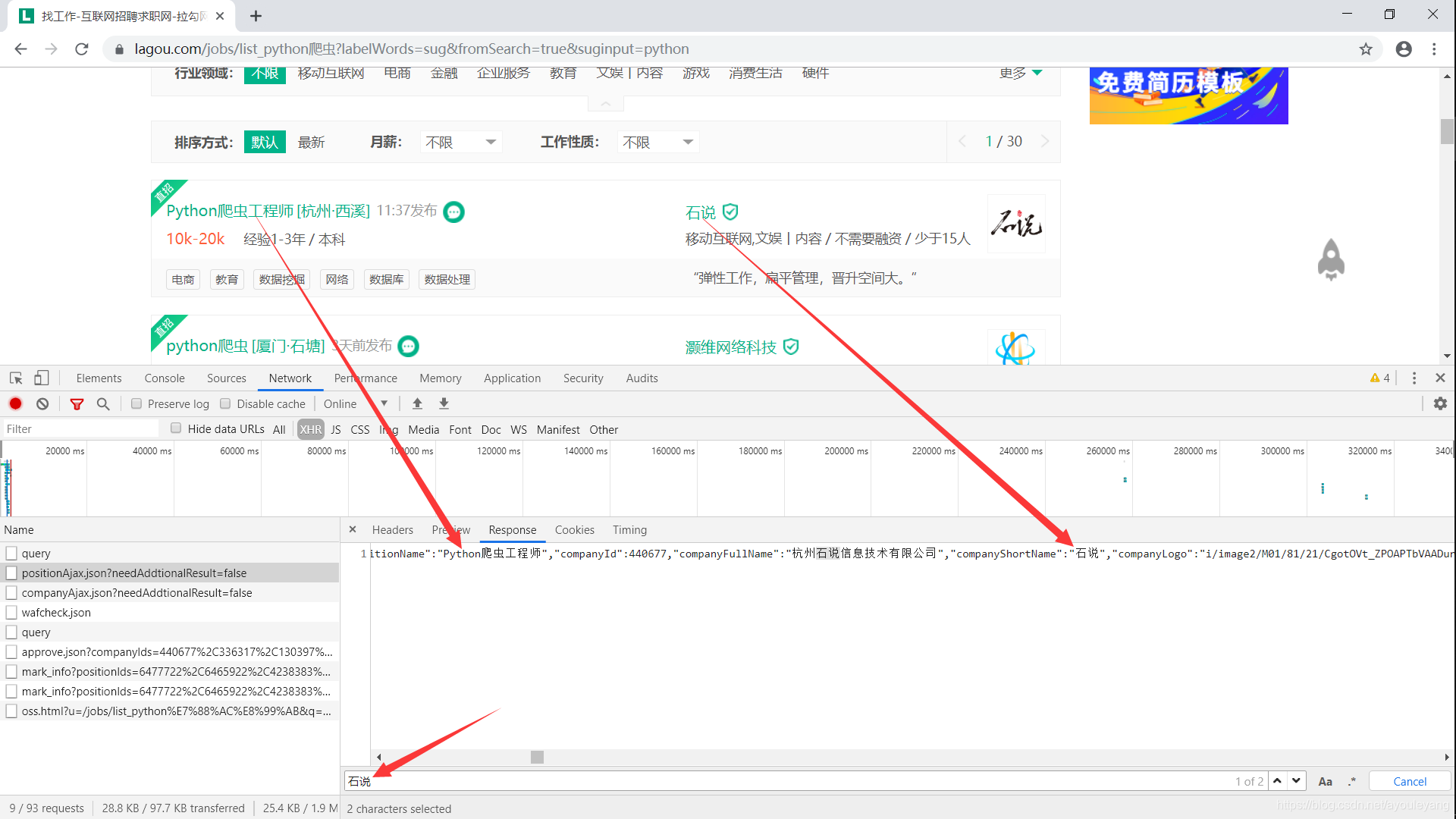
没有错吧?就是这样了,可以在其中找到我们需要的数据。
但是。。。。。
你换几个不同的职位试试,是不是发现他们传输通道都是一样的,神奇吧!!!
https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false
所以,它就要派上用场
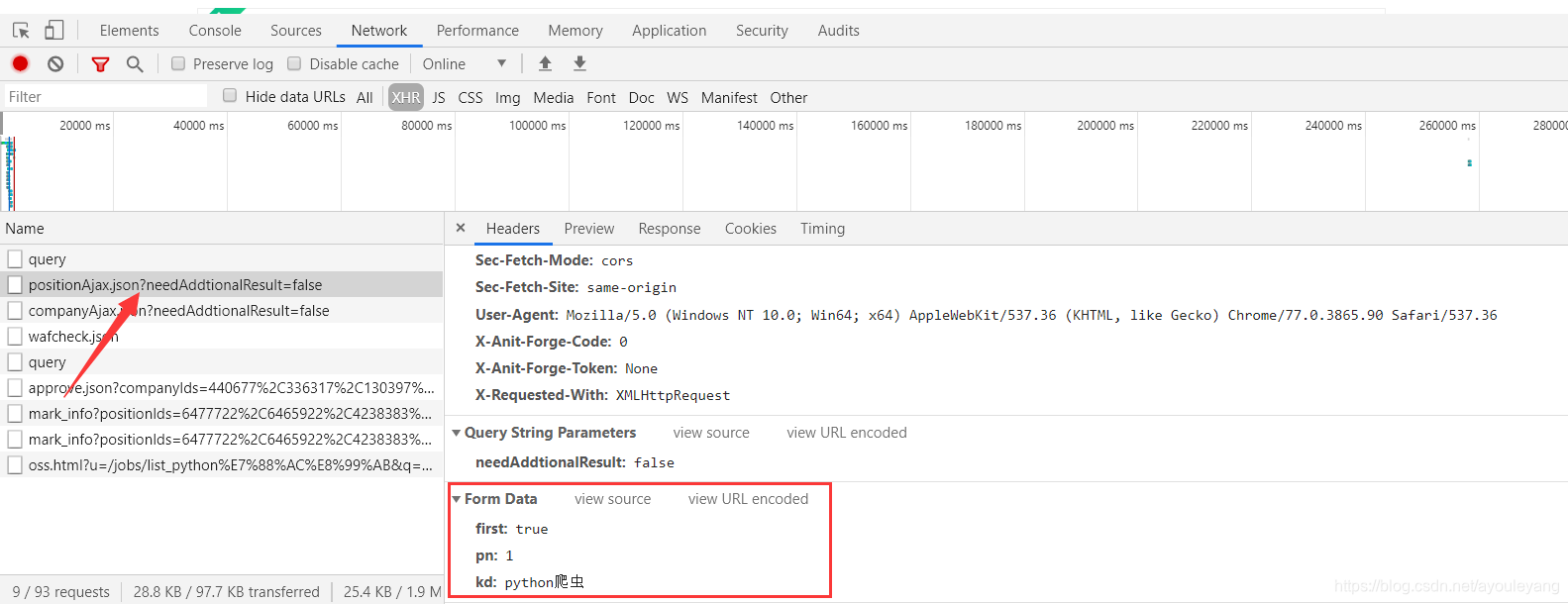
必须使用字典型,first是是否第一次访问,kd是你搜索的关键词,pn是当前页
data = {
'first': 'true',
'kd': 'python爬虫',
'pn': 1
}
敲黑板了,重点来了,注意听好了,cookie值!!!
拉勾网的cookie值只能使用一次,打开会就不能使用了,所以Ctrl+C,Ctrl+V就傻眼了吧,给你们举个例子吧
今天天气挺好的,买张票出去浪一下。我用身份证买了一张飞机票,登机并飞到了目的地,就想回来了。却被拦住,叫我重新买票,emmmm… …我只能重新买票了,在这里每张票就只能用一次。。。。。。。
cookie就是用来记录用户信息的,拉勾网的cookie就只能使用一次,就像机票一样,所以我必须要先办一张票再去乘机,来看一下我申请办理的流程
import requests
url = 'https://www.lagou.com/jobs/list_python%E7%88%AC%E8%99%AB?labelWords=&fromSearch=true&suginput='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_python%E7%88%AC%E8%99%AB?labelWords=&fromSearch=true&suginput='
}
session = requests.session()
session.get(url=url,headers=headers)
cookies = session.cookies
print(cookies.get_dict())
办理结果:
{'X_HTTP_TOKEN': '42daf4b72327b2816606070751bf5e71415983ed09', 'user_trace_token': '20191010191426-793b7a60-5904-45fe-a34f-c3ff2060d004', 'JSESSIONID': 'ABAAABAAAGGABCB4FEE572F2160195C0B9FC99073B52F0D', 'SEARCH_ID': '1232fb6acb564c4fa031b7ea7bb218c4'}
机票办好了,登机飞翔吧
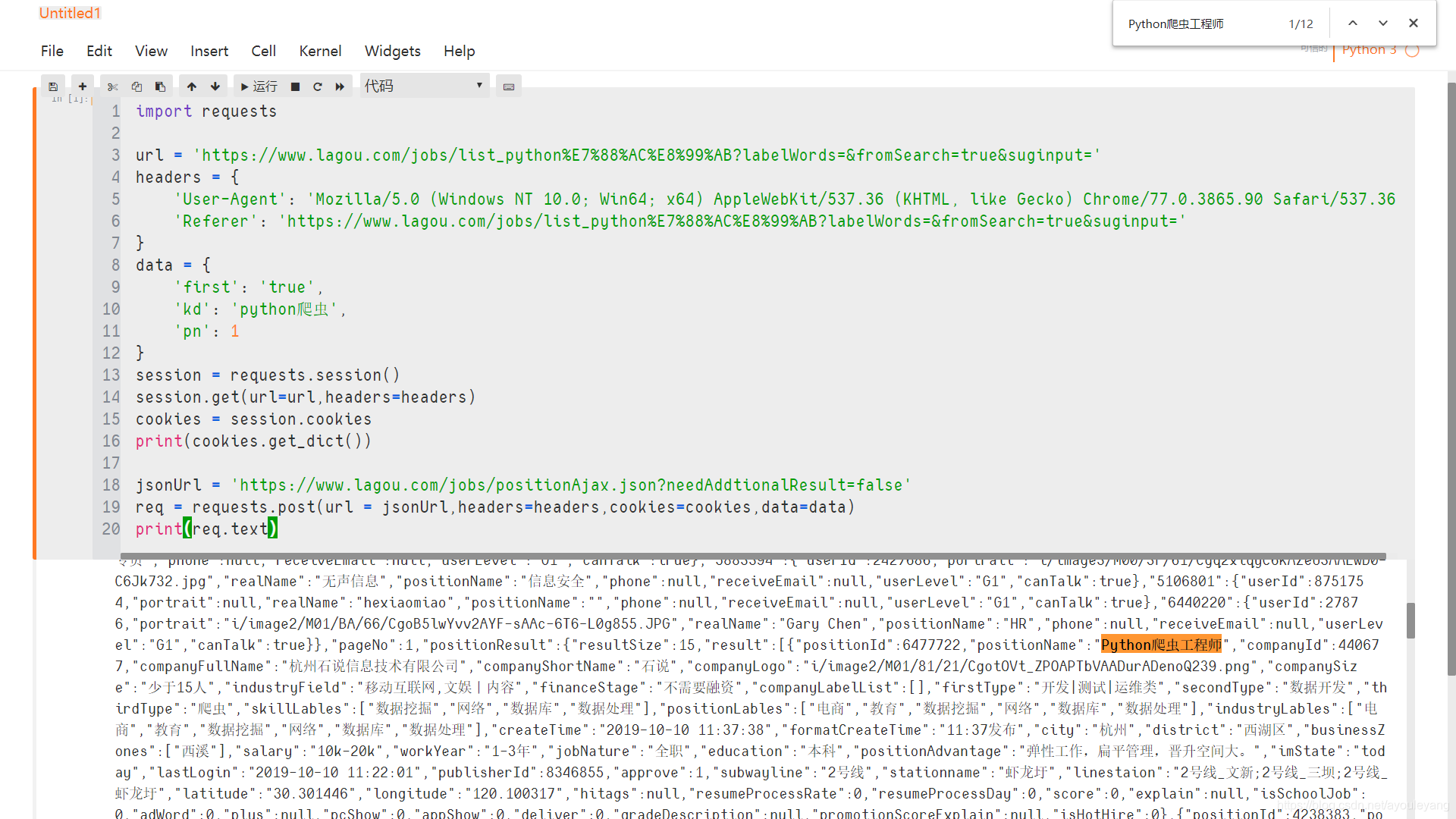
我太难了,必须开美颜。。。。
在浏览器上搜索"json在线解析",如https://www.json.cn/ ,把需要美化结果放进去来给她来个超级大美颜
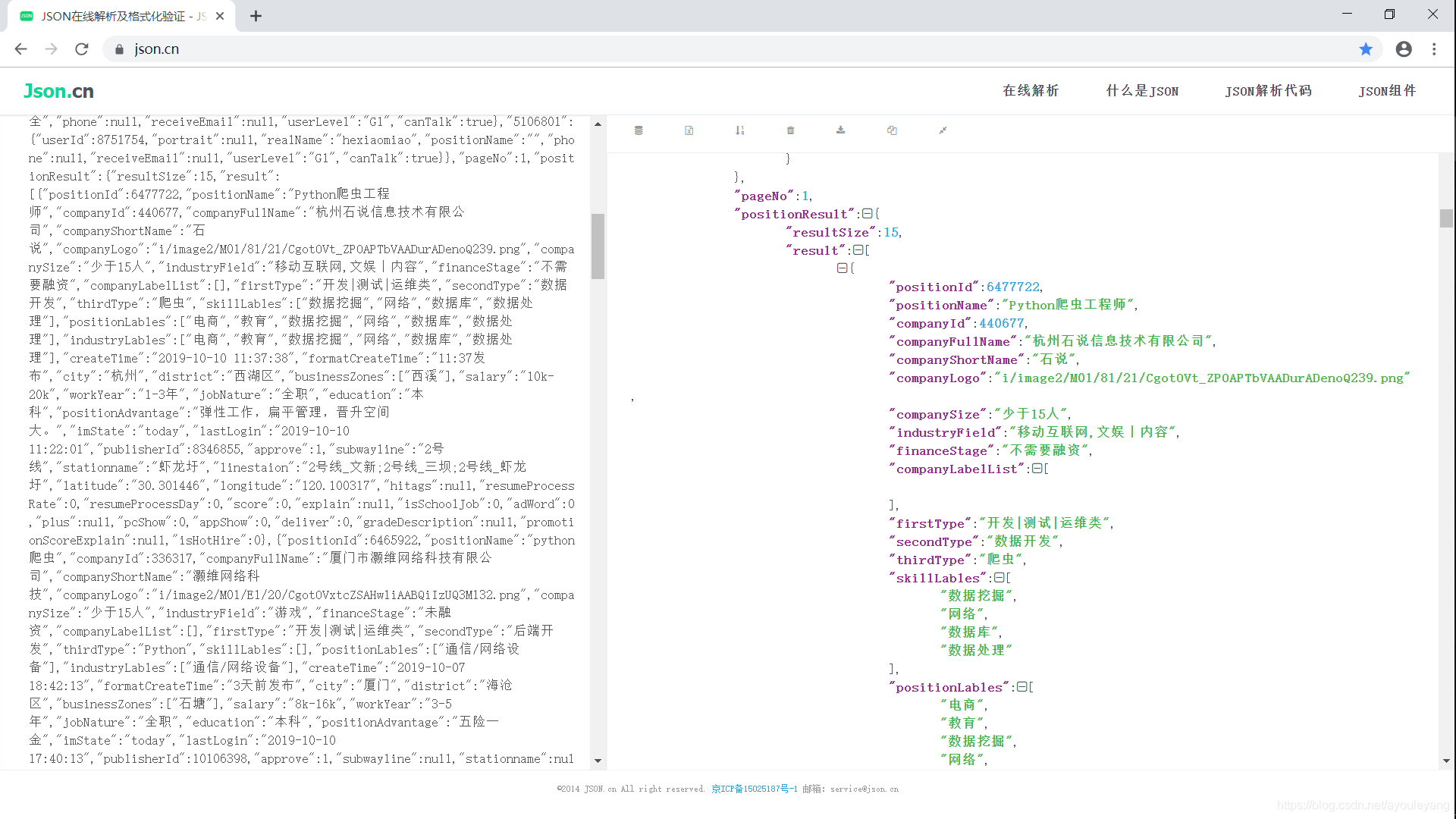
这样就优美很多了,嘻嘻
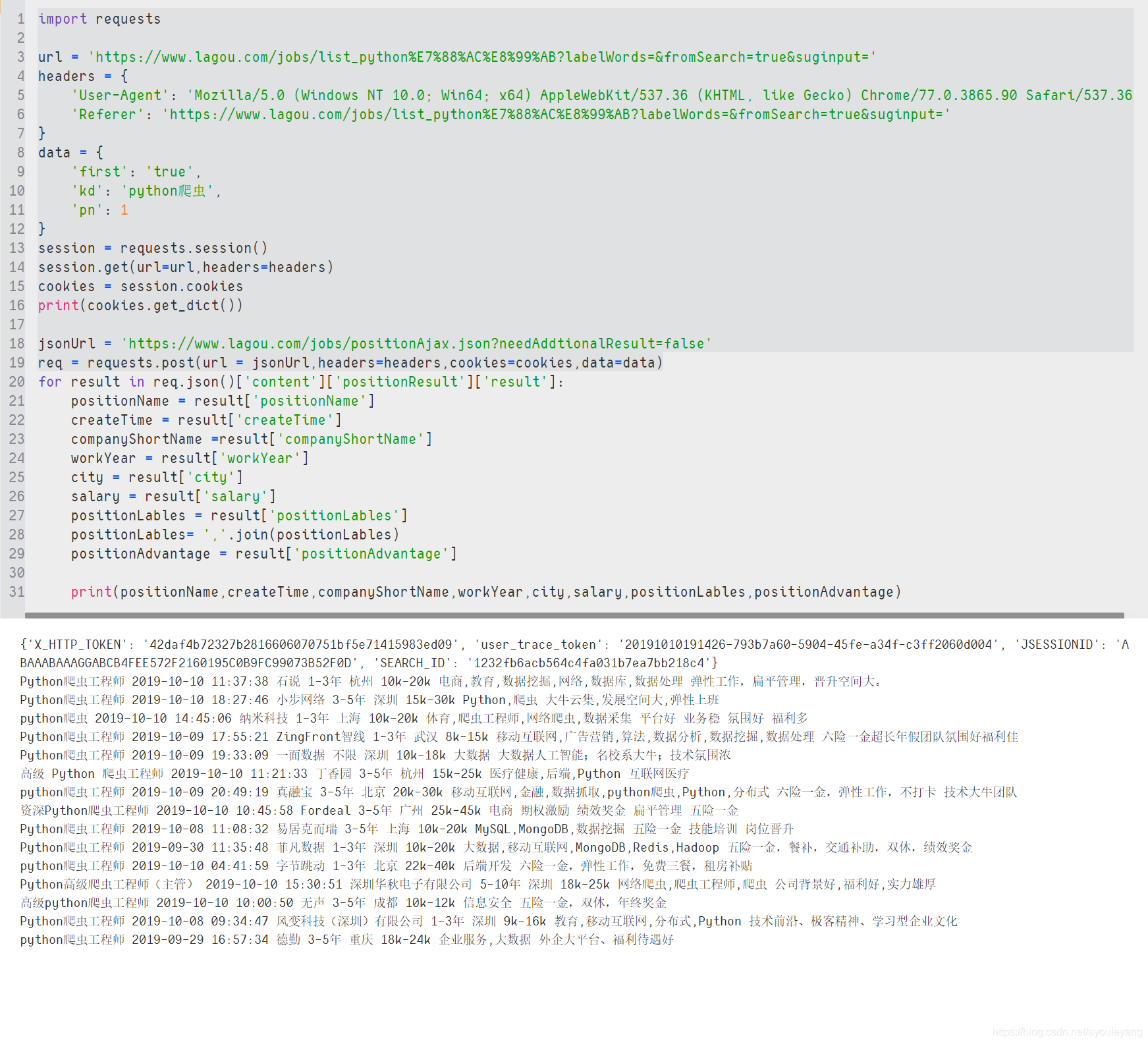
最后给它们都找个位置做下看风景吧。
源代码贴上一下:
import requests
url = 'https://www.lagou.com/jobs/list_python%E7%88%AC%E8%99%AB?labelWords=&fromSearch=true&suginput='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_python%E7%88%AC%E8%99%AB?labelWords=&fromSearch=true&suginput='
}
data = {
'first': 'true',
'kd': 'python爬虫',
'pn': 1
}
session = requests.session()
session.get(url=url,headers=headers)
cookies = session.cookies
print(cookies.get_dict())
jsonUrl = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
req = requests.post(url = jsonUrl,headers=headers,cookies=cookies,data=data)
for result in req.json()['content']['positionResult']['result']:
positionName = result['positionName']
createTime = result['createTime']
companyShortName =result['companyShortName']
workYear = result['workYear']
city = result['city']
salary = result['salary']
positionLables = result['positionLables']
positionLables= ','.join(positionLables)
positionAdvantage = result['positionAdvantage']
print(positionName,createTime,companyShortName,workYear,city,salary,positionLables,positionAdvantage)
祝你旅途愉快!!!
