看到一篇觉得还不错的博客,简单的试了一下:https://blog.csdn.net/d1240673769/article/details/75176451
这是一家专为拥有3至10年工作经验的资深互联网从业者,提供工作机会的招聘网站。
本文主要通过Python爬取拉勾网的职位信息,取得的信息能够为今后对某个职业的进行进一步的数据分析。
那么我们这里主要用到了三个Python模块:
urllib.request
urllib.parse
json在开始正式编写代码之前,首先要了解到搜索职位信息传递了些什么。
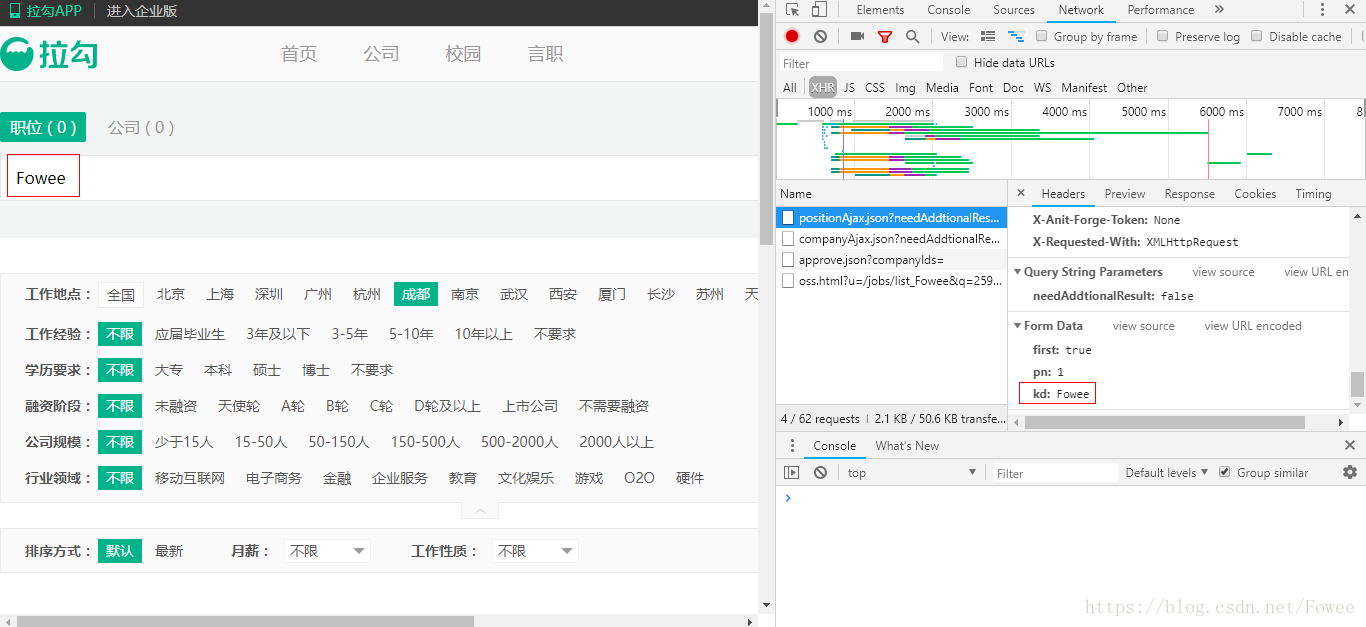
比如在搜索 ‘Fowee’ 时,这里其实是通过 post 方法去请求相应的数据,返回的结果存在 json 中
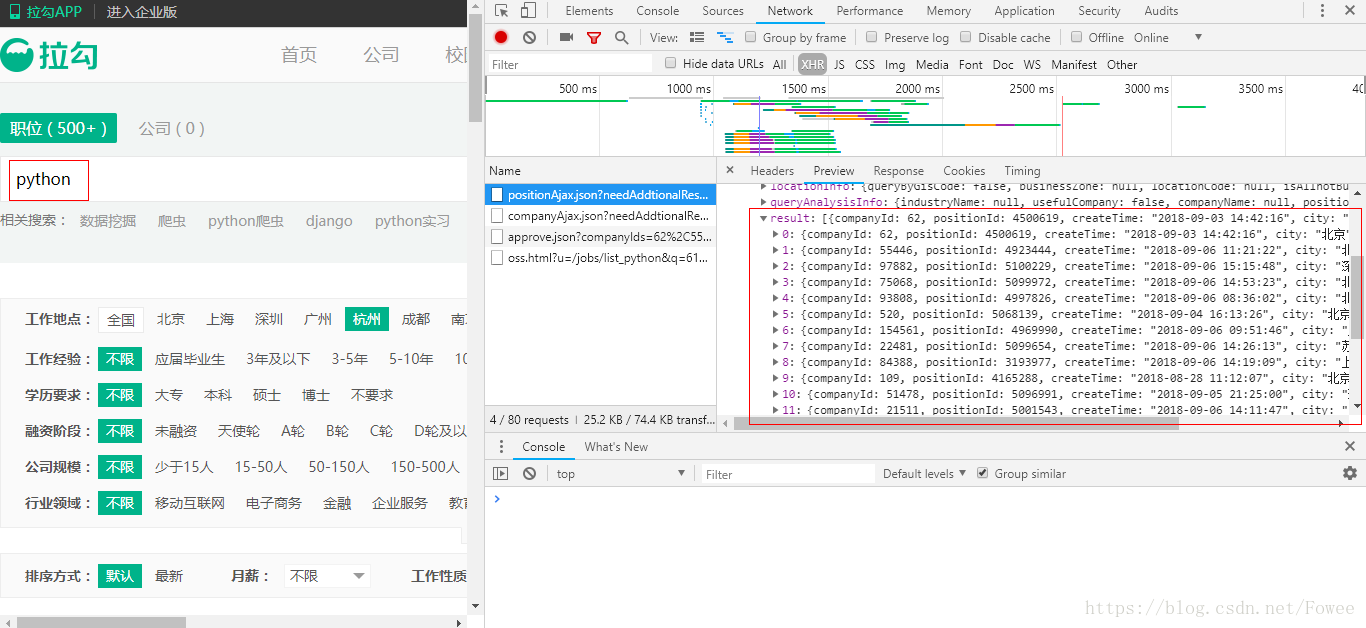
当然没有 'Fowee' 这个职位,那么这里的查询改成了 'Python'
这里我我们在知道它沟通的数据之后,自然要模拟浏览器去请求数据
我们去模拟如下所示的请求头
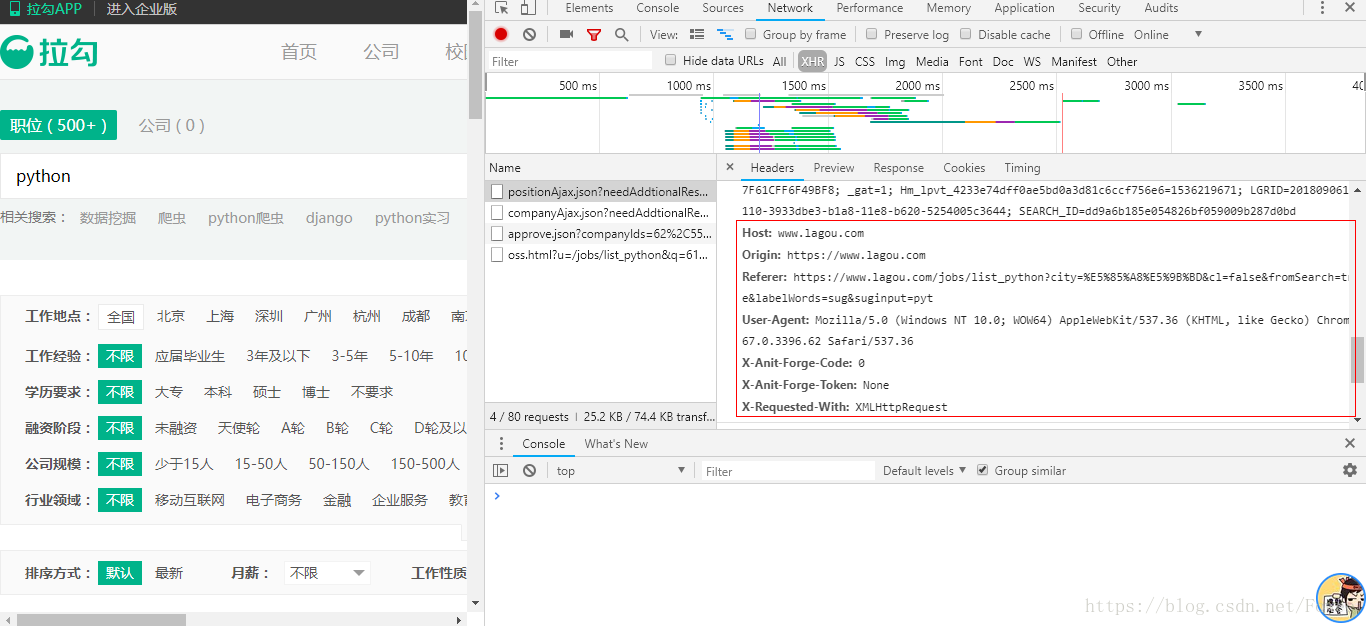
有了模拟浏览器这个概念,就可以进行后面的代码编写了。
import urllib.request
import urllib.parse
import json
def open_url(url,page_num,keywords):
try:
#设置post请求参数
page_data=urllib.parse.urlencode([
('pn',page_num),
('kd',keywords)
])
#设置headers
page_headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36',
'Connection':'keep-alive',
'Host':'www.lagou.com',
'Origin':'https://www.lagou.com',
'Cookie':'JSESSIONID=ABAAABAABEEAAJA8F28C00A88DC4D771796BB5C6FFA2DDA; user_trace_token=20170715131136-d58c1f22f6434e9992fc0b35819a572b; LGUID=20170715131136-13c54b92-691c-11e7-893a-525400f775ce; index_location_city=%E5%8C%97%E4%BA%AC; _gat=1; TG-TRACK-CODE=index_search; _gid=GA1.2.496231841.1500095497; _ga=GA1.2.1592435732.1500095497; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1500095497; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1500104021; LGSID=20170715143221-5b993c04-6927-11e7-a985-5254005c3644; LGRID=20170715153341-ec8dbfd2-692f-11e7-a989-5254005c3644; SEARCH_ID=d27de6042bdf4d508cf9b39616a98a0d',
'Accept':'application/json, text/javascript, */*; q=0.01',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Referer':'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E6%8C%96%E6%8E%98?labelWords=&fromSearch=true&suginput=',
'X-Anit-Forge-Token':'None',
'X-Requested-With':'XMLHttpRequest'
}
#打开网页
req=urllib.request.Request(url,headers=page_headers)
content=urllib.request.urlopen(req,data=page_data.encode('utf-8')).read().decode('utf-8')
return content
except Exception as e:
print(str(e))
#获取招聘职位信息,并从json中解析出来
def get_position(url,page_num):
try:
page_content=open_url(url,page_num,keywords)
data=json.loads(page_content)
content=data.get('content')
result=[('positionId','职位ID'),('positionName','职位名称'),('salary','薪资'),('createTime','发布时间'),('workYear','工作经验'),('education','学历'),('positionLables','职位标签'),('jobNature','职位类型'),('firstType','职位大类'),('secondType','职位细类'),('positionAdvantage','职位优势'),('city','城市'),('district','行政区'),('businessZones','商圈'),('publisherId','发布人ID'),('companyId','公司ID'),('companyFullName','公司名'),('companyShortName','公司简称'),('companyLabelList','公司标签'),('companySize','公司规模'),('financeStage','融资阶段'),('industryField','企业领域'),('industryLables','企业标签')]
positionResult=content.get('positionResult').get('result')
if(len(positionResult)>0):
for position in positionResult:
position_file = keywords + '.txt'
with open(position_file,'a') as fh:
fh.write("---------------------------\n")
for r in result:
with open(position_file,'a') as fh:
fh.write(str(r[1])+":"+str(position.get(r[0]))+"\n")
return len(positionResult)
except Exception as e:
print(str(e))
#爬取拉勾网招聘职位信息
if __name__=="__main__":
#爬取起始页
url='https://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false'
#设置查询的关键词
keywords = input("输入需要爬取的职位:")
page_num=1
while True:
print("正在爬取第"+str(page_num)+"页......")
result_len=get_position(url,page_num)
if(result_len>0):
page_num+=1
else:
break
print("爬取完成")代码大部分来自:https://blog.csdn.net/d1240673769/article/details/75176451
上面使用while True和break结合,根据json中result的值是否为空来判断当前要是否是最后一页,也可以根据json文件中pageSize和totalCount两个字段的值得出总的页面数。
运行程序:
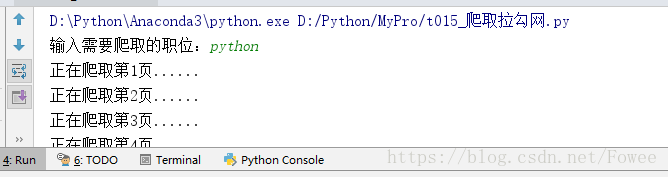
我们就能得到如下结果:
