全站爬取拉勾网职位信息
一、环境
- window7
- scrapy
- MySQL
二、简介
scrapy的全站爬取方式crawlspider跟其通用爬取方式spider实现上有一定的区别,两者都有各自的优势,选择用哪种方式取决于你对数据的需求和网站形式。
数据维度:职位链接、链接MD5压缩、岗位 、最低工资、最高工资、工作城市、最低工作经验、最高工作经验、学历要求、职位类型、发布时间、公司标签、职位诱惑、职位描述、工作地点、公司名字、爬取时间、爬取更新时间
三、网页分析与编程实现
1、crawlspider项目创建
1)创建项目
在命令行中输入:scrapy startproject 项目名字
2)创建crawlspider模板
根据提示进入项目文件目录,输入:scrapy genspider -t crawl example example.com crawlspider模块如下图:
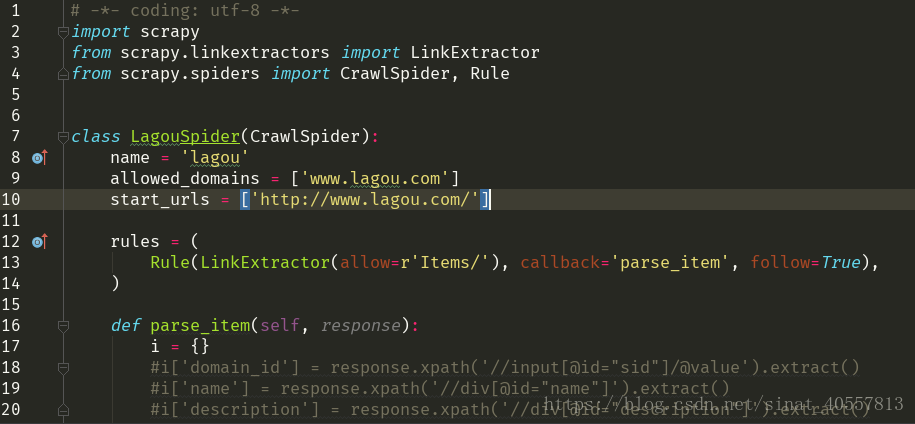
若需要另行创建环境,需要用到virtualenv模块,配置过程省略,在命令行中输入:mkvirtualenv virtualenv_name 创建新环境
当然如果需要指定python版本的环境,输入:mkvirtualenv --python=python2/3.exe 的路径

到这里crawlspider项目创建完毕
2、crawlspider爬取规则
其实crawlspider的爬取比通用的spider爬取更简便,从上图的模板可以看到,一个rules参数其实就是负责在全站的url中挖掘出有价值的url,也就是拥有我们想要的数据的url;其中的LinkExtractor方法是负责提取页面上的全部url,可根据我们设定的条件筛选出我们需要的url,callback参数是指定对筛选出的url的请求的响应函数,而follow参数的意思是是否需要对筛选出的url进行深度爬取,

所以一般的crawlspider程序只需要设置好rules和对url的解析函数就可以了,程序启动的入口是调用start_urls进行爬取;LinkExtractor方法中的allow参数值看起来并不完整,其实它是默认与allowed_domains连接起来的,如果一个网站的url并不是简单的https://www.xxx.com/....模式,我们可以挑选出多个含有有效信息的url模式写入allowed_domains列表中,如['www.xxx.com' , 'www.sss.com',...]
3、爬取拉勾遇到的问题
拉勾不需要登录也可以进行全站爬取,不过容易被服务器识别为爬虫,一旦被识别为爬虫访问,网站采取将请求url重定向到登录界面的措施。为了防止请求被重定向,一开始向请求头添加必要的参数,如UserAgent和cookie值,发现有效果,成功爬取的时间变长,但考虑到cookie值是会失效的,所以重写了start_requests,目的是在程序启动后获取最新的cookie值,然后保存到本地,这样拉勾的爬取就更持久了。但程序对于长期爬取的话还是有缺陷,需要改进的就是设置个cookie池,定期的更新cookie,这样爬虫就会更稳定,cookie池以后会更新。
4、程序
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy import Request
from WorkSpider.items import JobItemLoader , LagouJobItem
from selenium import webdriver
import pickle
import logging
class LagouSpider(CrawlSpider):
name = 'lagou'
allowed_domains = ['www.lagou.com']
start_urls = ['https://www.lagou.com']
login_url = 'https://passport.lagou.com/login/login.html?ts=1528881331568&serviceId=lagou&service=https%253A%252F%252Fwww.lagou.com%252F&action=login&signature=5DE87E91BC0439DCC4E2D15A46FC554A'
custom_settings = {
'COOKIES_ENABLED' : True ,
'DOWNLOAD_DELAY' : 2 ,
'DEFAULT_REQUEST_HEADERS' : {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'Cookie' : '_ga=GA1.2.2101592953.1527060802; user_trace_token=20180523153320-90e5f5e4-5e5b-11e8-93bb-525400f775ce; LGUID=20180523153320-90e5fa11-5e5b-11e8-93bb-525400f775ce; index_location_city=%E6%B7%B1%E5%9C%B3; LG_LOGIN_USER_ID=ccf98768efc6e6be1edcc2c0ddf9265270ffa115c3794eb082c1b0828a381e48; JSESSIONID=ABAAABAABEEAAJA3EE7E1BEE55959823F347951B5D021E7; _gid=GA1.2.944134256.1528799460; _gat=1; LGSID=20180612183058-b1e641e0-6e2b-11e8-9479-5254005c3644; PRE_UTM=; PRE_HOST=cn.bing.com; PRE_SITE=https%3A%2F%2Fcn.bing.com%2F; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; LGRID=20180612183058-b1e6447a-6e2b-11e8-9479-5254005c3644; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1527836743,1527837392,1527909793,1528799460; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1528799460' ,
'Host' : 'www.lagou.com' ,
# 'Origin' : 'https://www.lagou.com' ,
# 'Referer' : 'https://www.lagou.com/',
'Upgrade-Insecure-Requests:' : 1 ,
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36' ,
}
}
rules = (
Rule(LinkExtractor(allow=r'zhaopin/.*') , follow = True) ,
Rule(LinkExtractor(allow=r'gongsi/j\d+.html') , follow= True) ,
# Rule(LinkExtractor(allow=r'jobs/list_python爬虫.*'), follow=True) ,
Rule(LinkExtractor(allow=r'jobs/\d+.html') , callback= 'parse_job', follow=True),
)
def start_requests(self):
browser = webdriver.Chrome(executable_path= "D:/chromedriver/chromedriver.exe")
browser.get(self.login_url)
browser.find_element_by_css_selector("div:nth-child(2) > form > div:nth-child(1) > input").send_keys(
USER)
browser.find_element_by_css_selector("div:nth-child(2) > form > div:nth-child(2) > input").send_keys(
PASSWORD)
browser.find_element_by_css_selector(
"div:nth-child(2) > form > div.input_item.btn_group.clearfix > input").click()
import time
time.sleep(10)
cookies = browser.get_cookies()
cookie_dict = {}
for cookie in cookies:
cookie_dict[cookie['name']] = cookie['value']
with open('cookies_dict.lagou' , 'wb') as wf:
pickle.dump(cookie_dict , wf)
logging.info('--------lagou cookies---------')
print(cookie_dict)
return [scrapy.Request(self.start_urls[0] , cookies= cookie_dict)] #若不加return [] ,则报错:大意是内容不可迭代
def parse_job(self, response):
#解析拉勾网的职位
item_loader = JobItemLoader(item= LagouJobItem() , response= response)
item_loader.add_value('url' , response.url)
item_loader.add_value('url_object_id', response.url)
item_loader.add_css('title' , '.job-name::attr(title)')
item_loader.add_css('salary_highest', '.job_request span.salary::text')
item_loader.add_css('salary_lowest', '.job_request span.salary::text')
item_loader.add_css('job_city', '.job_request span:nth-child(2)::text')
item_loader.add_css('work_years_highest', '.job_request span:nth-child(3)::text')
item_loader.add_css('work_years_lowest', '.job_request span:nth-child(3)::text')
item_loader.add_css('degree_need', '.job_request span:nth-child(4)::text')
item_loader.add_css('job_type', '.job_request span:nth-child(5)::text')
item_loader.add_css('pulish_time', '.publish_time::text')
item_loader.add_css('tags', '.position-label li::text')
item_loader.add_css('job_advantage', '.job-advantage p::text')
item_loader.add_css('job_describe', '.job_bt p::text')
item_loader.add_css('job_addr', '.work_addr a::text')
item_loader.add_css('company_name', '.job_company img::attr(alt)')
itemloader = item_loader.load_item()
return itemloader5、爬取结果
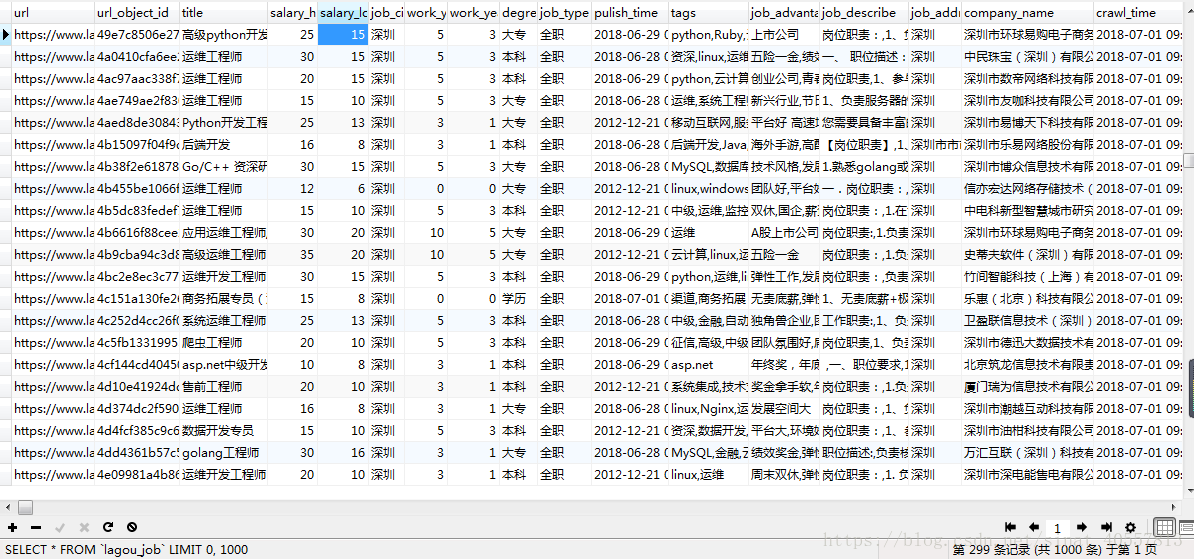
职位链接:url 最低工作经验 : work_years_lowest 职位诱惑 : job_advantage
链接MD5压缩:url_object_id 最高工作经验 : work_years_highest 职位描述 : job_describe
岗位:title 学历要求 : degree_need 工作地点 : job_addr
最低工资:salary_lowest 职位类型 : job_type 公司名字 : company_name
最高工资:salary_highest 发布时间 : pulish_time 爬取时间 : crawl_time
工作城市:job_cit 公司标签 : tags 爬取更新时间:crawl_update_time