本篇文章将实现:
爬取下来职位名称、各项待遇、工作地点等等与职位相关的信息,存储于MySQL中,并根据这些数据进行分析。
学习过程中主要遇到如下问题:
1.如何寻找待爬取网页的关键url?
拉勾网为AJax技术生成的动态网页(通过不断刷新网页时XRH中的内容不断增加可以确定),它的关键url不是地址栏中的url,而是被重定位的。在F12NETWORK 中的XHR中可以发现JSON格式的网页数据。
注意1:在Headers中的Request Methond项:POST
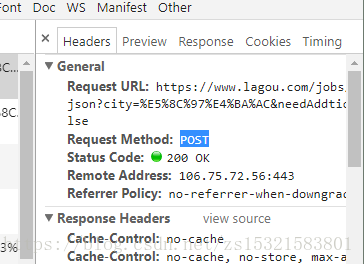
HTTP请求概述:HTTP协议又被称为超文本传输协议,它的的设计目的是保证客户机与服务器之间的通信。HTTP 的工作方式是客户端与服务器之间的请求-应答协议。在客户端和服务器之间进行请求-响应时,有两个最基本的请求方式:GET 和 POST。 其中,GET请求表示从指定的资源请求数据,POST请求表示向指定的资源提交要被处理的数据。
请求方式(request method)对于爬取的影响:
若方式为GET(请求从指定资源获取数据),则其爬取结果就是response的结果;
若方式为POST(向请求资源提交要被处理的数据),则response中的内容为资源+headers中的from data。
比较:
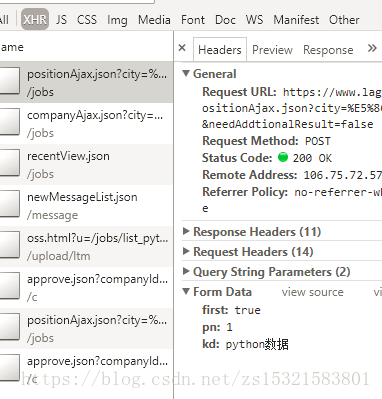
POST方式的关键url为:Request URL&first=true&pn=1&kd=python数据
GET方式关键url为:Request URL
注意2:
应用开发者工具编写爬虫时,当用到其中的标签时,尽量用复制粘贴的方式,如果手动输入的话,容易出现错误。
注意3:过长的语句可以用\换行隔开,避免pythonPEP8报错。但是换行后不需要缩进。如果不删除缩进,实际打印出来
会多几个空格。
代码:
# coding:utf-8
import pymysql
import requests
import json
# connect to mysql
db = pymysql.connect(
# who am i?
user='zhang',
passwd='135246',
# where am i going?
host='localhost',
port=3306,
db='d1',
# 沟通语言知晓中文
charset='utf8mb4'
)
# 游标方法,一行行遍历操作
cur = db.cursor()
cur.execute('DROP TABLE IF EXISTS positions')
sql = '''CREATE TABLE positions(
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT NOT NULL,
positionId INT,
companyId INT,
businessZones VARCHAR(50),
companyFullName VARCHAR(50),
positionName VARCHAR(50),
education VARCHAR(20),
city VARCHAR(10),
financeStage VARCHAR(10),
salary VARCHAR(30),
workYear VARCHAR(20),
companySize VARCHAR(20),
industryField VARCHAR(50),
positionAdvantage VARCHAR(50),
companyLabelList VARCHAR(100)
)'''
cur.execute(sql)
# requests method:post- key_url:url&Form Data
url = 'https://www.lagou.com/jobs/positi' \
'onAjax.json?gj=%E4%B8%8D%E8%A6%81%E6%B1%82&px=default&city=%E5%8C%97%E4%BA%AC&needAddtionalResult=f' \
'alse&first=true&kd=数据分析&pn='
# pretend to be requested by a browser
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440'
'.84 Safari/537.36',
'Cookie': 'WEBTJ-ID=20180810100822-1652197840c100a-029440c5302f0a-182e1503-1049088-1652197840d143; _ga='
'GA1.2.670840432.1533866903; user_trace_token=20180810100730-22f656ac-9c42-11e8-a37b-5254005c36'
'44; LGUID=20180810100730-22f65b2a-9c42-11e8-a37b-5254005c3644; _gid=GA1.2.526852831.1533866904'
'; X_HTTP_TOKEN=d070f83bda7a70bba1e1ef8ee6b4ba26; LG_LOGIN_USER_ID=d72cfcdbde90a28a95f1044b7d8a7'
'44dcfb42409658e6e25; _putrc=D2BD4BBBFC876630; JSESSIONID=ABAAABAAADEAAFIA8ED9113F6383B84D8B401D'
'FC23A7DBE; login=true; unick=%E5%BC%A0%E7%88%BD; showExpriedIndex=1; showExpriedCompanyHome=1; '
'showExpriedMyPublish=1; hasDeliver=0; index_location_city=%E5%8C%97%E4%BA%AC; TG-TRACK-CODE=ind'
'ex_search; LGSID=20180810175520-7e49bc97-9c83-11e8-ba35-525400f775ce; PRE_UTM=m_cf_cpt_baidu_p'
'c; PRE_HOST=www.baidu.com; PRE_SITE=https%3A%2F%2Fwww.baidu.com%2Fs%3Fwd%3D%25E6%258B%2589%25E5'
'%258B%25BE%25E7%25BD%2591%26rsv_spt%3D1%26rsv_iqid%3D0xe9ebd39800021157%26issp%3D1%26f%3D8%26'
'rsv_bp%3D1%26rsv_idx%3D2%26ie%3Dutf-8%26rqlang%3Dcn%26tn%3Dbaiduhome_pg%26rsv_enter%3D1%26oq%3D'
'mysql%252520%2525E6%25259F%2525A5%2525E7%25259C%25258B%2525E6%252595%2525B0%2525E6%25258D%2525A'
'E%2525E5%2525BA%252593%2525E4%2525B8%2525AD%2525E6%252589%252580%2525E6%25259C%252589%2525E8%252'
'5A1%2525A8%26rsv_t%3D1bedVPNE9gH1di3V%252FWaqQR%252B11XvIl5iWSqVb8qsZDX5TtB4UywNuNnZoXUjJep1AxI'
'wo%26inputT%3D1671%26rsv_pq%3Dfc0fbc8d0002c381%26rsv_sug3%3D52%26rsv_sug1%3D50%26rsv_sug7%3D100%'
'26rsv_sug2%3D0%26rsv_sug4%3D1671%26rsv_sug%3D2; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Flp%2Fhtm'
'l%2Fcommon.html%3Futm_source%3Dm_cf_cpt_baidu_pc; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=153386'
'6903,1533867013,1533880825,1533894973; gate_login_token=209c14a3f4aadce449845e93046007ac9964763'
'f53b37b37; LGRID=20180810175537-887f49d0-9c83-11e8-ba35-525400f775ce; Hm_lpvt_4233e74dff0ae5bd0'
'a3d81c6ccf756e6=1533894990; SEARCH_ID=99052d0a10c6449b8b4e6f0739092a81',
'Referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?px=default&gj=%E4%B8%8D%E'
'8%A6%81%E6%B1%82&city=%E5%8C%97%E4%BA%AC'}
# from the outermost layer to loop iterate
for page in range(1, 10):
# dynamic netpage generated by Ajax usually been responded by json file
# json file should be put in json parser to be parsed e.m json.loads(json_file)
# hxml/xml/lxml file can be put in to BeautifulSoup TO BE PARSED!
content = json.loads(requests.get(url + str(page), headers=headers).text)
# look for the wanted infomation in json file to find out where they are
company_info_list = content.get('content').get('positionResult').get('result')
for company_info in company_info_list:
positionId = company_info.get('positionId')
companyId = company_info.get('companyId')
# transform a string list to a long string seperated by ','
businessZones = ','.join(company_info.get('businessZones')) if company_info.get(
'businessZones') else "无" # 工作地址
companyFullName = company_info.get('companyFullName') # 公司名称
positionName = company_info.get("positionName") # 岗位名称
education = company_info.get('education') # 学历要求
city = company_info.get('city') # 城市
financeStage = company_info.get('financeStage') # 公司状况(上市公司,A\B\C\D轮)
salary = company_info.get('salary') # 薪资
workYear = company_info.get("workYear") # 工作年限
companySize = company_info.get("companySize") # 公司人数规模
industryField = company_info.get("industryField") # 行业类型
positionAdvantage = company_info.get("positionAdvantage") # 公司文化
companyLabelList = ','.join(company_info.get('companyLabelList')) if company_info.get('companyLabelList') \
else '无' # 公司福利
# the {} represented the refered string should be quoted as '{}' in format reference:'xxx'.format()
sql_insert = '''INSERT INTO positions(positionId, companyId, businessZones, companyFullName, positionName,
education, city, financeStage, salary, workYear, companySize, industryField, positionAdvantage,
companyLabelList)
VALUES({0}, {1}, '{2}', '{3}', '{4}', '{5}', '{6}', '{7}', '{8}', '{9}', '{10}', '{11}', '{12}'
, '{13}')'''.format(positionId, companyId, businessZones, companyFullName, positionName, education,
city, financeStage, salary, workYear, companySize, industryField,
positionAdvantage, companyLabelList)
cur.execute(sql_insert)
db.commit()
db.close()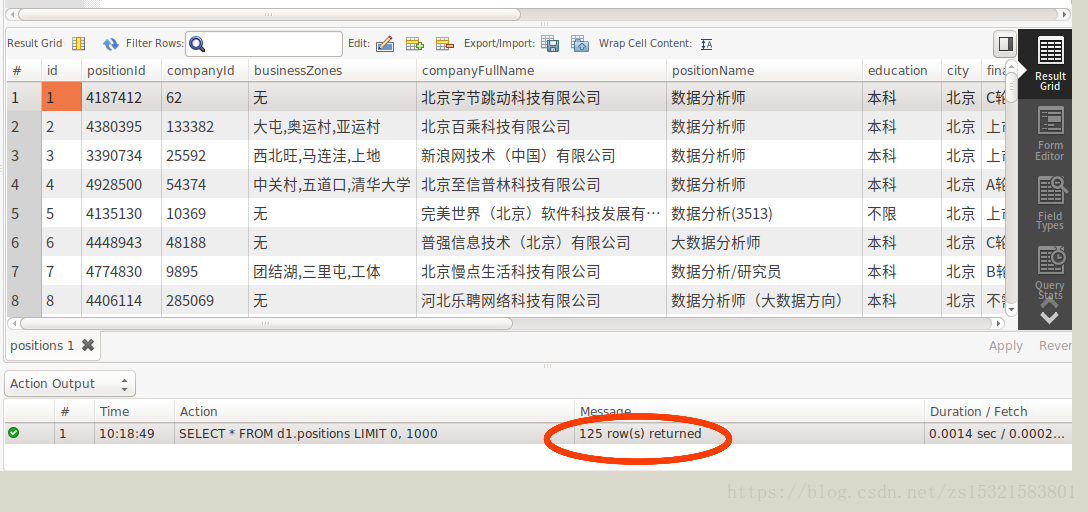
在mysql workbench 中将数据表导出为positions.csv:
数据分析:
首先要明确的是分析目标:
单特征分析:
1.公司位置统计分析,辅助我租房位置的决策
2.学历要求统计分析,看看北京地区数据分析岗位对学历的要求情况
3.融资阶段统计分析,吸金水平和对融资的要求。
4.该岗位薪资水平
5.公司规模统计
6.该岗位的行业分布
联合特征分析:
1.薪资水平与学历要求、公司规模、行业的联系
参考文章:爬取拉勾网数据
MySQL无法重启问题解决Warning: World-writable config file ‘/etc/my.cnf’ is ignored