后面我还对爬取的数据做了分析—拉勾网Python职位分析。
- 拉勾网反爬虫做的比较严,请求头多添加几个参数才能不被网站识别。
- 我们找到真正的请求网址,发现返回的是一个JSON串,解析这个JSON串即可,而且注意是POST传值,通过改变Form Data中pn的值来控制翻页。
需要的一些知识点
- AJAX:Asynchronous JavaScript and XML(异步的 JavaScript 和 XML)。它不是新的编程语言,而是一种使用现有标准的新方法。它采用的是AJAX异步请求。通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新。因此就可以在不重新加载整个网页的情况下,对网页的某部分进行更新,从而实现数据的动态载入。
- XHR:XMLHttpRequest 对象用于和服务器交换数据。
分析网页
打开拉勾网主页之后,我们在搜索框中输入关键字Python,以用来查找和Python相关的职位。在搜索结果的页面中,我们按照以下顺序操作:
- 右键检查
- 打开审查元素后默认打开的是Elements
- 我们切换到Network标签,刷新一下网页会出现各种条目的请求
- 因为该网站是异步请求,所以打开Network中的XHR,针对JSON中的数据进行分析。
我们点击页面中的页数,比如第2页,我们可以在右边看到一个POST请求,这个请求里面包含了真实的URL(浏览器上的URL并没有职位数据,查看源代码就可以发现这一点)、POST请求的请求头Headers、POST请求提交的表单Form Data(这里面包含了页面信息pn、搜索的职位信息kd)。
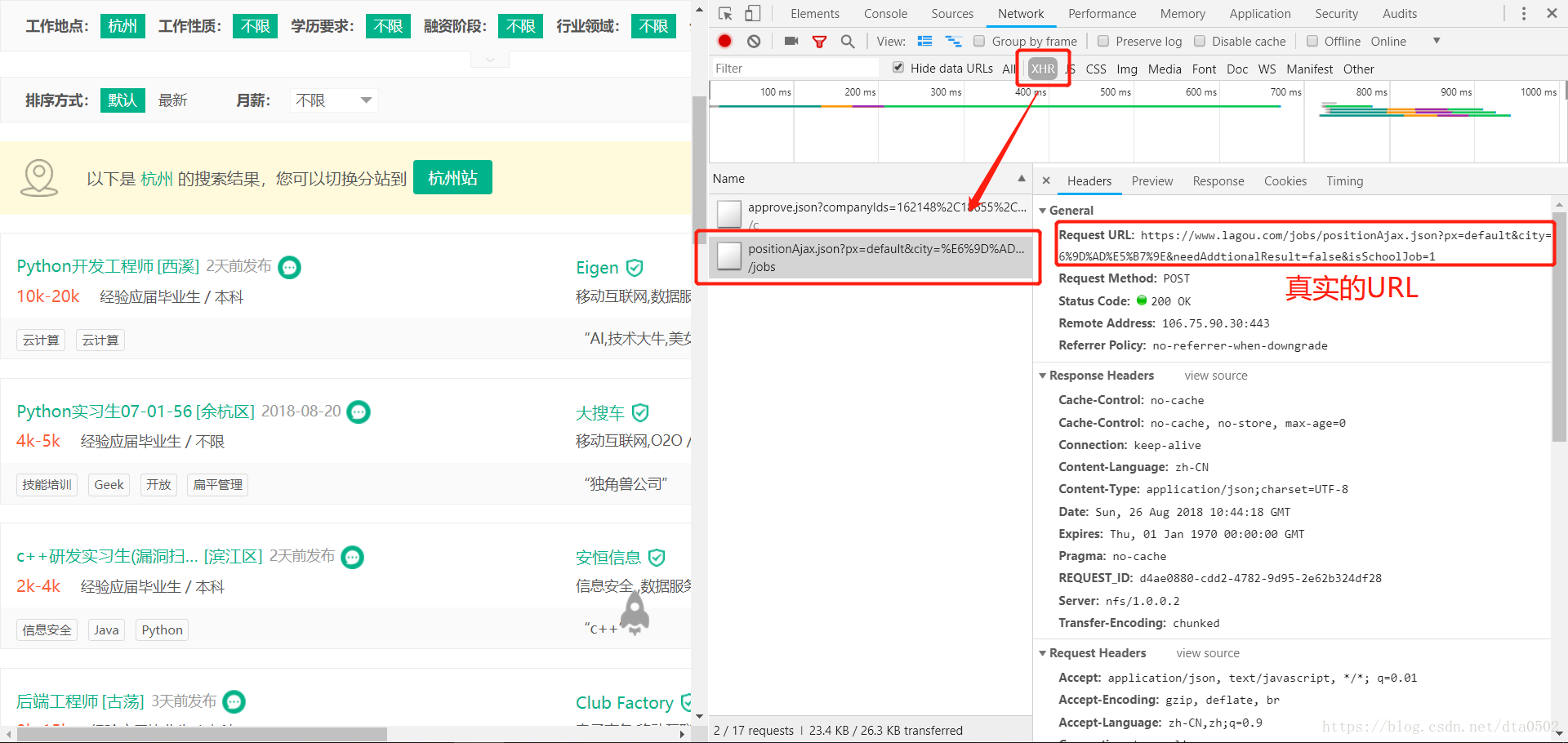
真实的URL
下面是真实的URL:
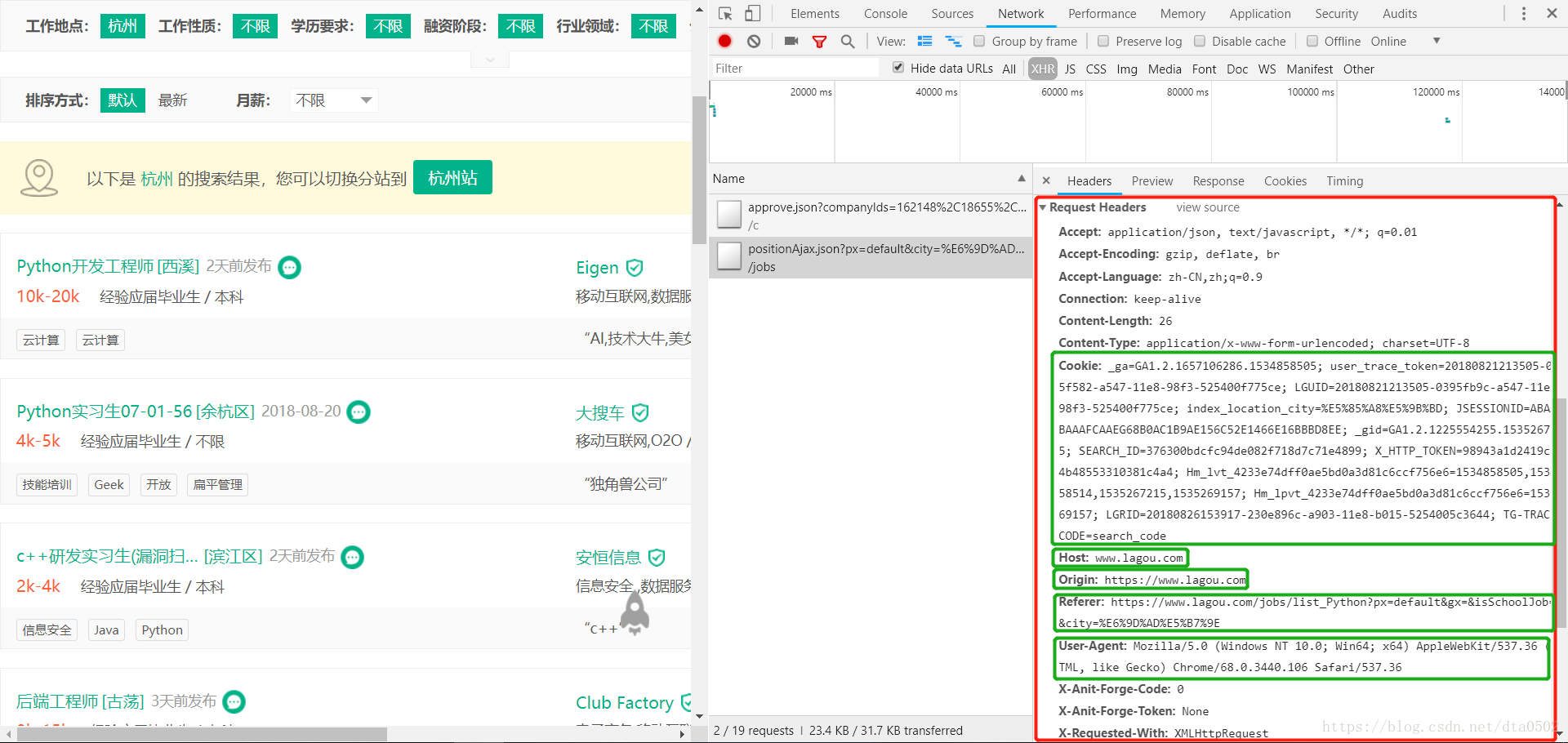
请求头信息
下面是我们需要构造的请求头Headers信息,如果这里没有构造好的话,容易被网站识别为爬虫,从而拒绝访问请求。
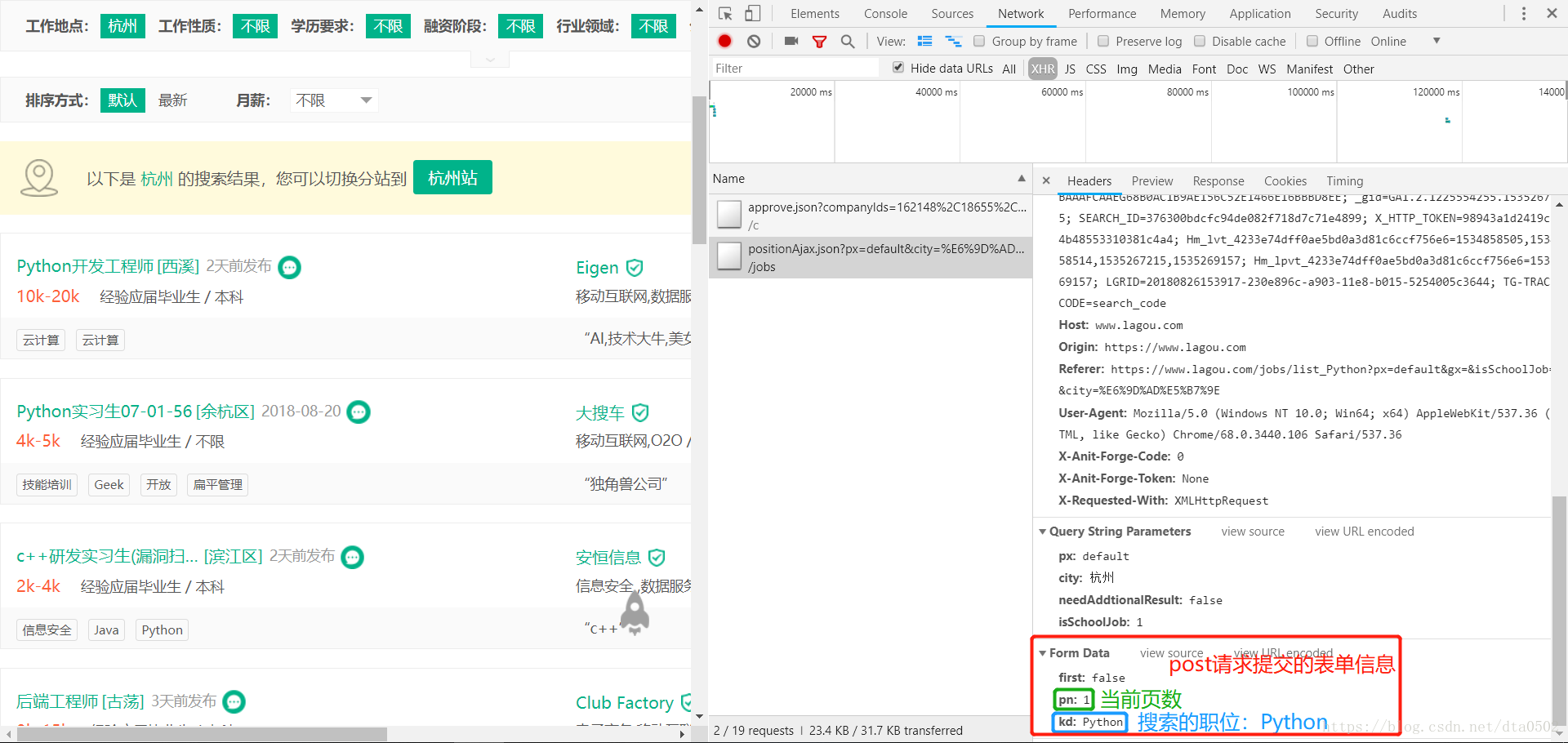
表单信息
下面是我们发送POST请求时需要包含的表单信息Form Data。
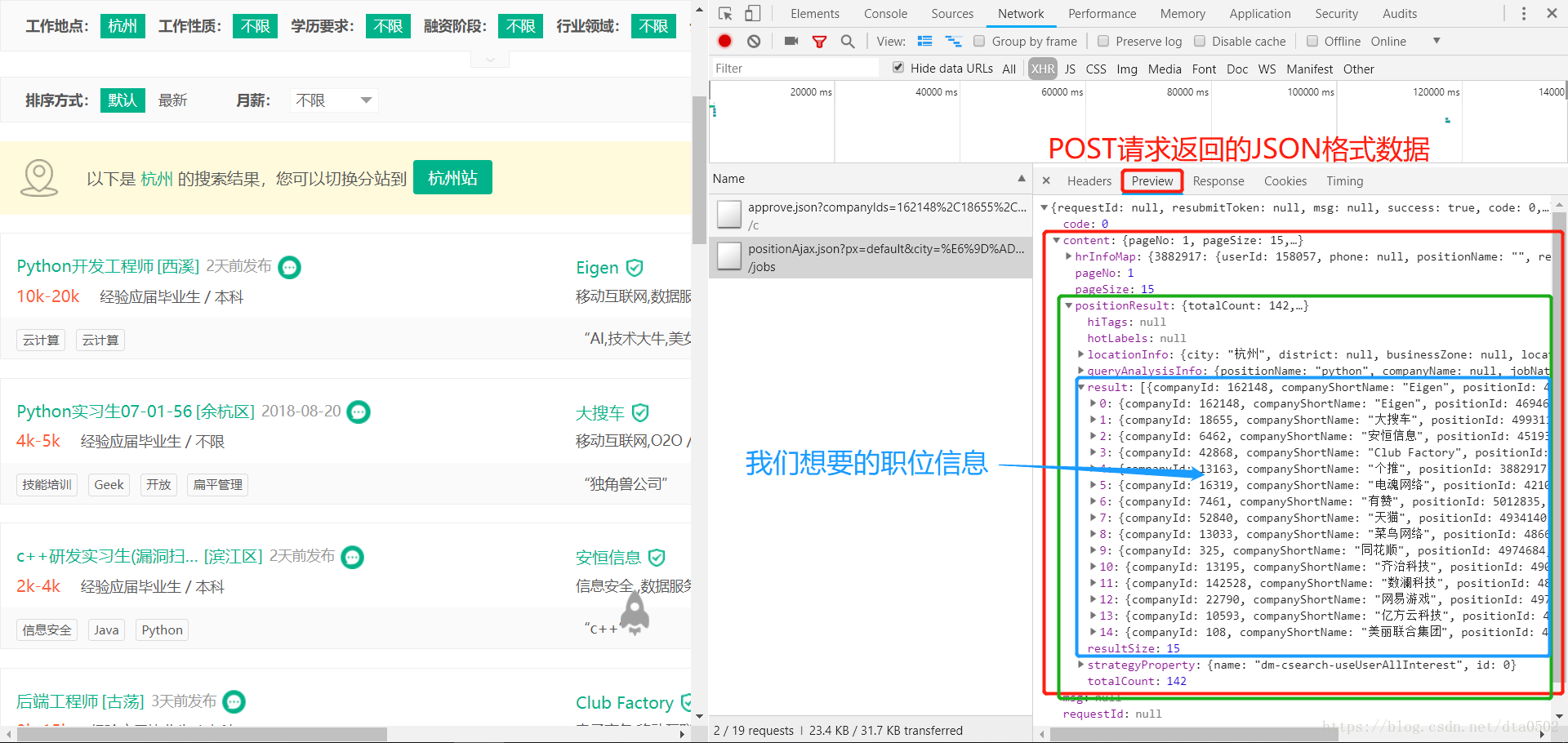
返回的JSON数据
我们可以发现需要的职位信息在content –> positionResult –> result下,其中包含了工作地点、公司名、职位等信息。 我们只需要保存这个数据就可以了。
至此我们分析完毕网页,下面可以开始爬取过程了。
单个页面的爬取
import requests
from fake_useragent import UserAgent
from lxml import etree
import csv
import json
import time
import pandas as pd构造请求头、表单
下面是构造请求头(headers)。
Host = "www.lagou.com"
Origin = "https://www.lagou.com"
Referer = "https://www.lagou.com/jobs/list_Python?px=default&gx=&isSchoolJob=1&city=%E6%9D%AD%E5%B7%9E"
ua = UserAgent()headers = {
'User-Agent':ua.random,
'Host':Host,
'Origin':Origin,
'Referer':Referer
}下面是构造表单(Form Data)。
data= {
'first': False,
'pn': "1",
'kd': 'Python'
}下面是真实的URL地址。
url = "https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E6%9D%AD%E5%B7%9E&needAddtionalResult=false&isSchoolJob=1"requests获取网页
response = requests.post(url = url,headers = headers,data = data)response.status_code200
页面解析
result = response.json()position = result['content']['positionResult']['result']df = pd.DataFrame(position)
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 15 entries, 0 to 14
Data columns (total 46 columns):
adWord 15 non-null int64
appShow 15 non-null int64
approve 15 non-null int64
businessZones 7 non-null object
city 15 non-null object
companyFullName 15 non-null object
companyId 15 non-null int64
companyLabelList 15 non-null object
companyLogo 15 non-null object
companyShortName 15 non-null object
companySize 15 non-null object
createTime 15 non-null object
deliver 15 non-null int64
district 15 non-null object
education 15 non-null object
explain 0 non-null object
financeStage 15 non-null object
firstType 15 non-null object
formatCreateTime 15 non-null object
gradeDescription 0 non-null object
hitags 4 non-null object
imState 15 non-null object
industryField 15 non-null object
industryLables 15 non-null object
isSchoolJob 15 non-null int64
jobNature 15 non-null object
lastLogin 15 non-null int64
latitude 15 non-null object
linestaion 6 non-null object
longitude 15 non-null object
pcShow 15 non-null int64
plus 0 non-null object
positionAdvantage 15 non-null object
positionId 15 non-null int64
positionLables 15 non-null object
positionName 15 non-null object
promotionScoreExplain 0 non-null object
publisherId 15 non-null int64
resumeProcessDay 15 non-null int64
resumeProcessRate 15 non-null int64
salary 15 non-null object
score 15 non-null int64
secondType 15 non-null object
stationname 6 non-null object
subwayline 6 non-null object
workYear 15 non-null object
dtypes: int64(13), object(33)
memory usage: 5.5+ KB
type(result)dict
全部页面的爬取
一共有10个页面,这里全部爬取。
第一次尝试
代码如下:
for page in range(1,11):
data['pn'] = str(page)
response = requests.post(url,headers = headers,data = data)
result = response.json()
print(result)
position = result['content']['positionResult']['result']
df = pd.DataFrame(position)
if page == 1:
total_df = df
else:
total_df = pd.concat([total_df,df],axis = 0)出现这样的错误:
{'success': False, 'msg': '您操作太频繁,请稍后再访问', 'clientIp': '121.248.50.24'}可能是触发了网站的反爬虫机制,下面需要改进一下。
改进版本
主要加入了一个延迟,降低抓取的速度。
if result['success']:
position = result['content']['positionResult']['result']
time.sleep(1) # 获取正常的情况下延时1s请求一次
return position
else:
print("您操作太频繁,请稍后再访问")
time.sleep(10) # 出现异常时,间隔10s后再获取
position = getPosition(url,headers,data,page) #递归获取
return position下面是爬取职位信息函数,其中包括爬取失败后的递归爬取,保证数据的完整!
def getPosition(url,headers,data,page):
data['pn'] = str(page)
response = requests.post(url,headers = headers,data = data)
result = response.json()
if result['success']:
position = result['content']['positionResult']['result']
time.sleep(1) # 获取正常的情况下延时1s请求一次
return position
else:
print("您操作太频繁,请稍后再访问")
time.sleep(10) # 出现异常时,间隔10s后再获取
position = getPosition(url,headers,data,page) #递归获取
return position下面是页面爬取过程,这里调用了前面的getPosition函数,最后将爬取到的职位信息合并为一个Pandas DataFrame变量,方便后面保存。
for page in range(1,11):
position = getPosition(url,headers,data,page)
df = pd.DataFrame(position)
if page == 1:
total_df = df
else:
total_df = pd.concat([total_df,df],axis = 0)您操作太频繁,请稍后再访问
您操作太频繁,请稍后再访问
您操作太频繁,请稍后再访问
您操作太频繁,请稍后再访问
您操作太频繁,请稍后再访问
您操作太频繁,请稍后再访问
total_df.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 142 entries, 0 to 6
Data columns (total 46 columns):
adWord 142 non-null int64
appShow 142 non-null int64
approve 142 non-null int64
businessZones 86 non-null object
city 142 non-null object
companyFullName 142 non-null object
companyId 142 non-null int64
companyLabelList 142 non-null object
companyLogo 142 non-null object
companyShortName 142 non-null object
companySize 142 non-null object
createTime 142 non-null object
deliver 142 non-null int64
district 141 non-null object
education 142 non-null object
explain 0 non-null object
financeStage 142 non-null object
firstType 142 non-null object
formatCreateTime 142 non-null object
gradeDescription 0 non-null object
hitags 14 non-null object
imState 142 non-null object
industryField 142 non-null object
industryLables 142 non-null object
isSchoolJob 142 non-null int64
jobNature 142 non-null object
lastLogin 142 non-null int64
latitude 142 non-null object
linestaion 50 non-null object
longitude 142 non-null object
pcShow 142 non-null int64
plus 0 non-null object
positionAdvantage 142 non-null object
positionId 142 non-null int64
positionLables 142 non-null object
positionName 142 non-null object
promotionScoreExplain 0 non-null object
publisherId 142 non-null int64
resumeProcessDay 142 non-null int64
resumeProcessRate 142 non-null int64
salary 142 non-null object
score 142 non-null int64
secondType 142 non-null object
stationname 50 non-null object
subwayline 50 non-null object
workYear 142 non-null object
dtypes: int64(13), object(33)
memory usage: 52.1+ KB
下面是输出为csv文件。
total_df.to_csv('Python-School-Hangzhou.csv', sep = ',', header = True, index = False)后面我还对爬取的数据做了分析—拉勾网Python职位分析。