HSME: Hypersphere Manifold Embedding for Visible Thermal Person Re-Identificatio
本文最大的亮点是将人脸识别中设计的Sphere softmax loss函数迁移到ReID中,即SphereReID。
目前的问题:
目前的方法多采用分类和度量学习相结合的方法来训练模型,以获得具有鉴别性和鲁棒性的特征表示。然而,这种方式忽略了分类子空间和特征嵌入子空间之间的相关性。
基于此,提出了一种具有分类和识别约束的端到端双流超球面流形嵌入网络(HSMEnet)。同时,我们设计了一个获得去相关特征的两阶段训练方案,我们将去相关的HSME称为D-HSME。
网络框架及loss:
1.HSME network:
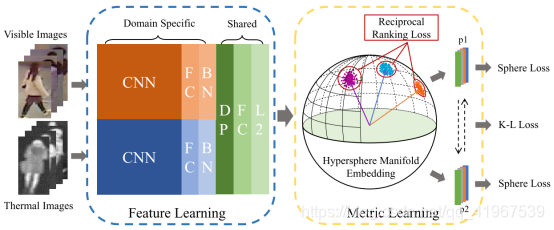
它包括两个部分:特征学习部分用于提取可共享的特征表征,度量学习部分用于匹配。分别输入RGB图和热图,经过CNN,FC,BN层分别提取特征,绿色部分的共享共享将之前提取的特征转换为嵌入空间,L2归一化后,共享特征映射到超球面流形上,其中,在度量学习中,两样本间的差异仅取决于角度。然后利用identity loss 和 ranking loss对模型进行约束,使其具有识别性。此外,还采用 KL散度来衡量两个领域预测的匹配性。p1和p2是两个域图像的预测概率。最后,通过单矢量分解(SVD)方法对Sphere Softmax最大值权矩阵进行了修正,获得了low level的特征。我们将特征相关的HSME网络称为D-HSME网络。
2.Feature Learning:
有specific layer 和shared layer组成,其中specific layer分别提取visible和thermal图像的特征,两个支路的网络结构大致相似,且backbone为alexNet,参数单独优化,输出给shared layer,权值共享,进一步提取特征,转换为共享嵌入空间。
3. Metric Learning Part:
将深度特征表示映射到超球面流形上,训练模型学习超球面上的分类和识别问题。这样,深层特征对匹配问题具有更强的诊断性和鲁棒性。这部分是HSME的关键,包括超球面流形嵌入(Hypersphere Manifold Embedding)、loss函数(Reciprocal Ranking Loss、Intra-modality constraint)和特征去相关(Feature Decorrelation)三个方面:
3.1Hypersphere Manifold Embedding
本文使用Sphere Softmax将样本的深度特征映射到超球上,使模型能够学习该超球的判别表示。在这个超球面上,两个样本之间的距离可以通过它们的特征向量的角度来确定,这对于后面的度量学习过程是必要的。其中,Sphere Softmax loss:
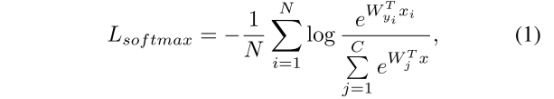
其中,N是样本数量,C是类别数量,W是分类器的权值矩阵,xi是样本的特征向量,yi是样本的标签。WT yi表示第j类的未归一化概率。
这个公式就是最经典的计算每一个样本在某一别类的概率,Softmax可以有效区分类间差异,但是对于类内的分布没有很好的约束,因此监督效果不够。
本文最大的亮点就是经典softmax loss的一个变种,该softmax是从人脸领域中的coco loss迁移过来的:
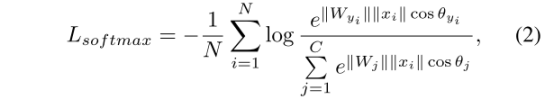
其实,2式是1式的一种变种:即神经元的权重向量的模和特征向量的模相乘,再乘以两个向量夹角的余弦值,这是简单的向量点积的基本定义公式:
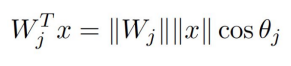
目的是不把特征映射在普通的欧式空间,而是映射到球面上:
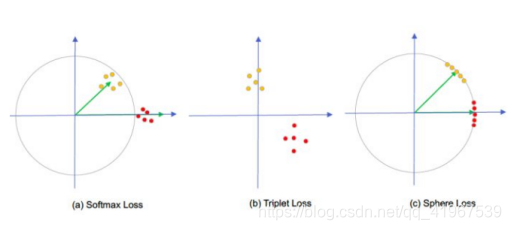
图a是原始的Softmax损失,绿色是分别是类别1和类别2的分类层神经元,分别输出属于类别1和类别2的score,黄点和红点分别是落在空间中的不同类别的样本。可以看到,原始的Softmax在空间的分布比较随意。而z1=z2就是两个类别的临界面,约束类别1的样本的score满足z1>z2,类别2的样本的score满足z2>z1即可正确进行分类,但是实际上特征分布并不够理想。
图b是行人重识别度量学习中常用的Triplet Loss的分布,Triplet Loss要满足正样本对见的距离比负样本对之间的距离更小,并小于一个设定的阈值,Triplet Loss使用的是相对约束,对于特征的绝对分布没有添加现实的约束,所以还经常将Triplet Loss和Softmax Loss结合起来,效果也会进一步提升:
图c则是本文的Sphere Loss,将特征映射到一个高维球面上, 将原文中公式2拆开来看:
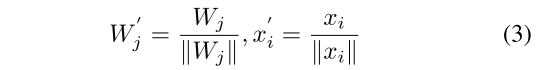
当我们用w’j和x’j代替wj和xj时,概率公式为:
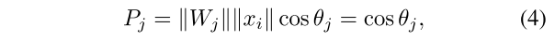
最终得到的sphere softmax loss为(其中,s为scale factor,规定训练过程中的margin,本文s=5):
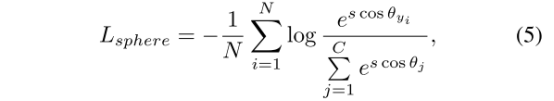
将权重向量和特征向量都进行归一化消除模的影响,并引入一个温度参数s,控制softmax的温度(即曲线的波动程度)。这样做以后,如下图所示:
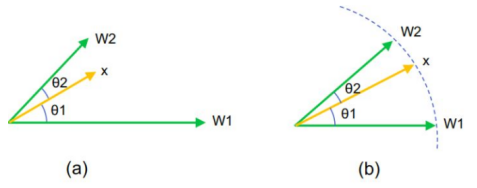
图a原始的softmax是比较点积,对于样本x,如果|W1||x|cosθ1>|W2||x|cosθ2,则分到第1类,反之分到第2类,分类结果不仅和角度有关,还和向量的模有关。
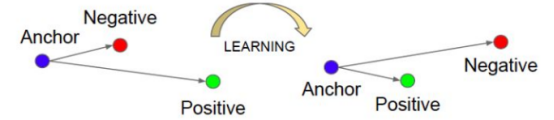
而图b中归一化以后,只需要比较两个角度的大小,如果cosθ1> cosθ2,则分到第1类,反之分到第2类,只由角度决定,清晰简单多来,全部映射到一个超球面上了。即下图为3D 超球展示:黑色箭头为anchor,即为上图的x:

同时,本文还加入了KL散度,来测量两个领域预测p1和p2的相似度:
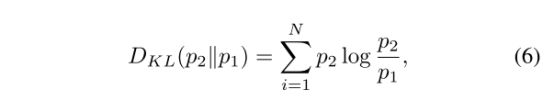
总loss函数为:
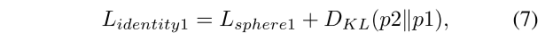
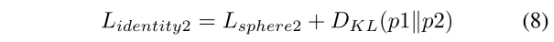
3.2Reciprocal Ranking Loss、Intra-modality constraint
针对同模态和跨模态之间的特征差异,如下图,其中T为thermal image ,V为visible image,i,j为同一ID,i,k为不同ID:
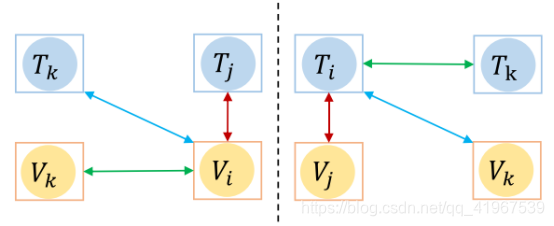
我们可以在3.2图中看到,同一模态内不同的ID距离大于不同模态内的同一ID的距离,即:
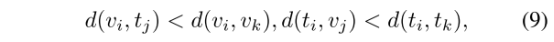
而我们希望上图中绿线大于红线,即设计了reciprocal ranking loss,其中ρ为预先设定的margin :
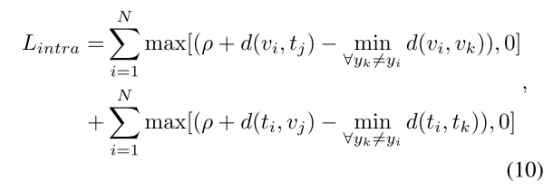
同理,跨模态不同ID的距离应该大于跨模态同一ID的距离,即:
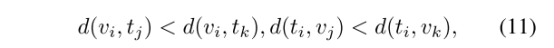
我们希望上图中红线比蓝线短,跨模态的不同ID的距离应尽可能大于跨模态相同ID的距离:
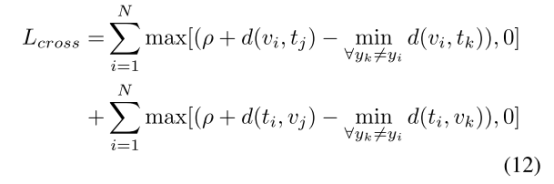
总loss:
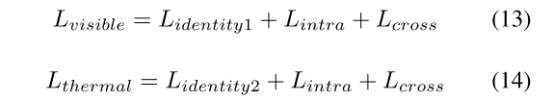
3.3Feature Decorrelation
如果Sphere Softmax的权值向量高度相关,则所学习的特征模型的识别性可能不够,容易出现过拟合问题。由两步进行去相关:
3.3.1.用截断的正态分布函数随机化球面软最大权矩阵。然后对模型进行训练,直到收敛。
3.3.2.可以用两个酉矩阵和一个奇异矩阵代替权重w进行训练,直至收敛:
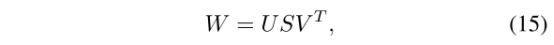
所有训练阶段结束后,权值矩阵由高相关状态转换为低相关状态:
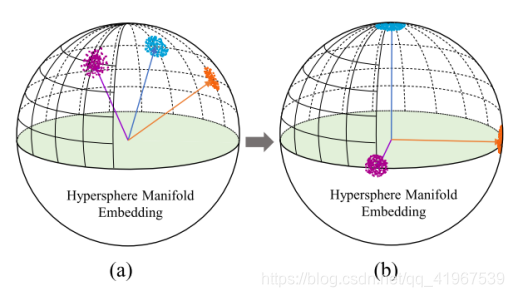
从上图可以看到(a)超球面上的原始权矩阵,(b)正交权矩阵。将权值矩阵转化为正交性时,不同权值向量周围的样本分布比原样本更大
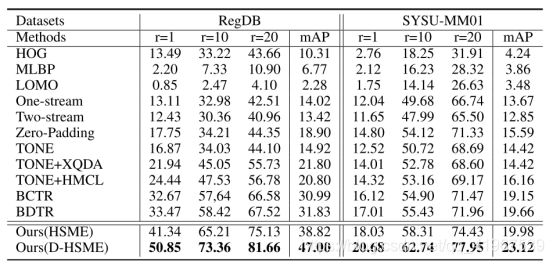
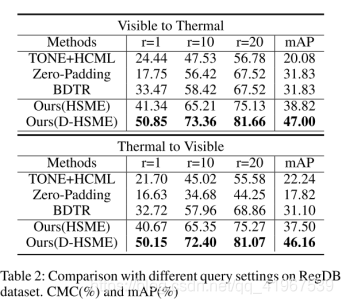
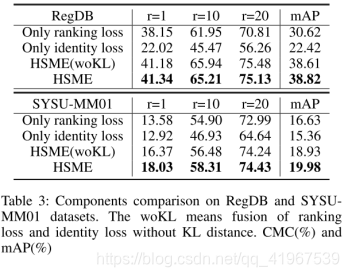
实验:
数据集采用RegDB和SYSU-MM01,评价标准采用CMC和mAP: