文章地址:https://www.aclweb.org/anthology/D15-1181.pdf
文章标题:Multi-Perspective Sentence Similarity Modeling with Convolutional Neural Networks(基于卷积神经网络的多视角句子相似度建模)EMNLP2015
Abstract
句子相似度建模由于语言表达的模糊性和可变性而变得复杂。为了应对这些挑战,我们提出了一个使用多种视角比较句子的模型。我们首先使用卷积神经网络对每个句子进行建模,该网络提取多层次的粒度特征,并使用多种类型的池化。然后,我们使用多个相似性度量来比较我们在几个粒度上的句子表示。我们将我们的模型应用于三个任务,包括Microsoft Research的释义识别任务和两个SemEval语义文本相似任务。我们在所有任务上都获得了出色的性能,在不使用外部资源(如WordNet或解析器)的情况下,可以与当前的技术水平相媲美或超越。
一、Introduction
检测两篇文章的语义关联是语言处理任务中的一个基本问题,如剽窃检测、查询排序和问题回答。本文研究了句子相似度度量问题:给定一个查询句S1和一个比较句S2,任务是用一个分数sim(S1, S2)来计算它们之间的相似度。这个相似度评分可以在一个系统中使用,该系统通过将两个句子与一个阈值进行比较来确定它们是否属于释义。
由于语言表达的可变性和标注训练数据的数量有限,句子相似性的测量具有挑战性。这使得在NLP中很难像传统方法那样使用稀疏的、手工制作的特性。近年来,人们利用神经网络获得了句子相似度方面的成功(Tai et al., 2015;Yin and Sch¨utze, 2015)。我们的方法也是基于神经网络:我们提出了一个模块化的功能架构,包含两个组件,句子建模和相似度测量。
在句子建模中,我们使用了卷积神经网络,它具有多个粒度和窗口大小的卷积滤波器,然后是多种类型的池化。我们实验了两种类型的词嵌入和词性标记嵌入(第4节)。为了进行相似性度量,我们使用多个距离函数比较句子表示的局部区域对:余弦距离、欧几里得距离和元素间的差异(第5节)。
我们展示了在两个半时代语义关联任务上的最新性能(Agirre等,2012;Marelli et al.,2014),以及在微软研究释义(MSRP)识别任务上的高度竞争性能(Dolan et al., 2004)。在SemEval-2014任务中,我们匹配了Tai等人(2015)最先进的依赖树长短时记忆(LSTM)神经网络,但没有使用解析器或部分语音标记。在MSRP任务上,我们的性能优于Yin和Sch¨utze(2015)最新提出的卷积神经网络模型,且该模型没有经过任何预训练。此外,我们进行了消融实验,以显示我们的建模决策对所有三个数据集的贡献,显示了我们在句子建模和结构化相似性度量中使用多角度的明显好处。
二、Related Work
以往对句子相似度建模的研究多集中在特征工程方面。已经发现了几种有用的稀疏特征类型,包括:(1)基于字符串的,包括单词和字符级别上的n克重叠特征(Wan et al., 2006)和基于机器翻译评估指标的特征(Madnani et al., 2012);(2)以知识为基础,利用外部词汇资源,如WordNet (Fellbaum, 1998; Fern and Stevenson, 2008);(3)基于句法的,如对两句之间的依存句法差异进行建模(Das和Smith, 2009);(4)基于语料库,利用潜在语义分析等分布模型获取特征 (Hassan, 2011; Guo and Diab, 2012)。
几种性能良好的方法使用了系统组合 (Das and Smith, 2009; Madnani et al., 2012)或多任务学习。Xu等人(2014)开发了一个特征丰富的多实例学习模型,该模型可以联合学习单词和句子对之间的释义关系。
最近的工作已经从手工制作的特性转向使用分布式表示和神经网络架构进行建模。Collobert和Weston(2008)在多任务设置中使用了卷积神经网络,他们的模型被联合训练用于多个具有共享权值的NLP任务。Kalchbrenner等人(2014)提出了一种用于句子建模的卷积神经网络,该网络使用动态k-max池来更好地处理不同大小的模型输入。Kim(2014)对Collobert和Weston(2008)的convolutional neural network architecture提出了几项修改,包括使用fixed和learned word vector以及改变convolution filters的窗口大小。
在MSRP任务中,Socher等人(2011)使用递归神经网络对每个句子进行建模,递归地计算句子在二值化语法中的成分表示。Ji和Eisenstein(2013)利用矩阵分解技术获得句子表示,并将其与精细调整的稀疏特征相结合,使用SVM分类器进行相似度预测。Socher等人以及Ji和Eisenstein都结合了稀疏特性来提高性能,而我们在这篇文章中没有用到。
Hu等人(2014)使用了卷积神经网络,该网络将层次化的句子建模与逐层组合和池化相结合。当他们直接对整个句子表示进行比较时,我们开发了一个结构化的相似性度量层来比较局部区域。各种其他的神经网络模型已经被提出用于相似任务(Weston et al., 2011;黄等人,2013;Andrew et al., 2013;布罗姆利等人,1993年)。
最近,Tai等人(2015)和Zhu等人(2015)同时提出了一种基于树的LSTM神经网络结构用于句子建模。与它们不同的是,我们不使用语法分析器,但是我们的性能在相似性任务上与Tai等人(2015)相匹配。这个结果很有吸引力,因为对于低资源语言或专门领域,很难获得高质量的解析器。Yin和Sch¨utze(2015)同时开发了一种用于释义识别的卷积神经网络架构,我们在实验中对其进行了比较。他们最好的成绩依赖于一个无监督的训练前步骤,我们不需要匹配他们的表现。
我们的模型架构在几个方面与以前的工作不同。我们利用输入句子的多角度,以最大限度地利用信息,并对句子表示的特定区域进行结构化比较。现在我们对模型进行了详细的描述,并在实验评估中与上述相关工作进行了比较。
三、Model Overview
由于语言表达的模糊性和可变性,文本相似性建模变得复杂。我们针对这些现象设计了一个模型,利用多种类型的输入通过多种类型的卷积和池化处理。我们的相似体系结构同样使用多个相似函数。

图一:模型的概述。两个输入的句子(在底部)由相同的神经网络并行处理,输出句子表示。通过结构化相似度量层对句子表示进行比较。然后将相似度特征传递给一个全连接层来计算相似度评分(top)。
综上所述,我们的模型(如图1所示)由两个主要组件组成:
- 1、用于将句子转换为表示形式进行相似性度量的句子模型;我们使用卷积神经网络结构与多种类型的卷积和池化,以捕获不同粒度的信息在输入。
- 2、使用多个相似性度量的相似性度量层,比较句子模型中句子表示的局部区域。
我们的模型有一个**“暹罗(Siamese)”结构**(Bromley et al., 1993),两个子网分别并行处理一个句子。子网络共享所有的权值,并由相似度度量层连接,然后由一个完全连接的层进行相似度评分输出。
重要的是,对于感兴趣的语言,我们不需要像WordNet或语法分析器这样的资源;我们只使用可选的词性标记和预先训练的词嵌入。与之前工作的主要区别在于我们在局部区域上使用了多种类型的卷积、池化和结构化相似性度量。我们在稍后的实验中表明,我们的大部分性能来自于对输入语句的多个“透视图”的使用。
我们在第4节描述了我们的句子模型,在第5节描述了我们的相似性度量层。
四、Sentence Modeling
在本节中,我们将描述用于对每个句子建模的卷积神经网络。我们使用了两种定义在输入的不同角度上的卷积滤波器(第4.1节),也使用了多种类型的池(第4.2节)。
我们的输入是标记流,它可以解释为一个时间序列,其中附近的单词可能是相关的。
4.1 Convolution on Multiple Perspectives(多视角卷积)
我们将卷积滤波器F定义为<ws, wF, bF, hF>,其中ws为滑动窗宽,wf为滤波器的权向量,bF为偏置,hF为激活函数(tanh等非线性函数)。当过滤器F应用于序列sent时,计算wF与sent的长度为ws的每个可能的词嵌入窗口之间的内积,然后添加偏差并应用激活函数。
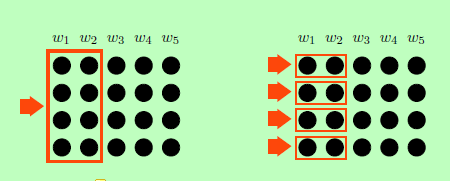
图二:左:一个整体过滤器匹配整个单词向量(这里,ws = 2)。
右:每个维度的过滤器与单词embeddings的每个维度独立匹配。
这个滤波器可以看作是执行“时间”卷积,因为它与单词序列的区域相匹配。由于这些过滤器考虑到每个单词在每个位置的整体嵌入,我们称它们为整体过滤器,参见图2的左半部分。
此外,我们通过为单词embeddings的每个维度k构建每个维度的过滤器F[k]来在更细的粒度上定位信息。参见图2的右半部分。每个维的过滤器类似于“空间卷积”过滤器,只是我们将每个过滤器限制为一个预定义的维。我们为输入词嵌入的每个维度包含单独的每维过滤器。
我们在这两种方式中都使用了词嵌入,这使得我们可以提取更多的信息,从而实现更丰富的句子建模。虽然我们通常不期望神经词嵌入的单个维度对人类是可解释的,但是我们的模型仍然可以利用由不同维度捕获的不同信息。此外,如果我们在学习过程中更新单词embeddings,可以进一步鼓励不同的维度来捕获不同的信息。
我们将卷积层定义为一组具有相同类型(整体或每维)、激活函数和宽度ws的卷积过滤器。模型选择层中过滤器的类型、宽度、激活函数和数量,并学习每个过滤器(wF和bF)的权重。
4.2 Multiple Pooling Types(多个池化类型)
卷积滤波器F的输出向量outF通常被转换成一个标量,以供模型使用。例如,“max-pooling”在outF的条目上应用一个max操作,并返回最大值。在本文中,我们尝试了另外两种类型的池:“最小池化”和“均值池化”。

图三:每个构建块由多个独立的池化层和宽度为ws1的卷积层组成。左:blockA操作整个词嵌入向量。右:blockB对单词向量的各个维度进行操作,以捕获更细粒度的信息。
一个组,表示组(ws, pooling, send),是一个对象,它包含一个宽度为ws的卷积层,使用pooling函数池,并对发送的语句进行操作。我们将一个构建块定义为一组组。我们使用两种类型的构建块,blockA和blockB,如图3所示。我们将blockA定义为
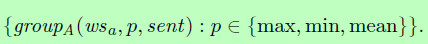
也就是说,blockA的一个实例有三个卷积层,分别对应三个池函数;都有相同的窗口大小的wsa。另一种选择是在相同的过滤器上使用多种类型的池(Rennie et al., 2014);相反,我们为不同的池类型使用独立的过滤器集。我们对所有的卷积层使用A类型的块。
我们将blockB定义为:

即块b包含两组宽度为wsb的卷积层,一组为最大池,一组为最小池。每一组包含一个Dim维度卷积滤波器卷积层。也就是说,我们使用B类型的块来处理字向量的各个维上的卷积层。
我们使用这些多种类型的池来从每种类型的过滤器中提取不同类型的信息。
4.3 MultipleWindow Sizes(多个窗口大小)

图四:一个句子的示例神经网络架构,包含3个blockA实例(3种池化类型)和2个blockB实例(2种类型),窗口大小不同,ws = 1,2和ws = 1;blockA操作整个字向量,而blockB包含独立操作单个维度的过滤器。
与传统的基于n-gram的模型类似,我们在构建块中使用多个窗口大小ws,以便了解不同长度的特性。例如,在图4中,我们使用了四个构建块,每个窗口大小为ws=1或2,用于自己的卷积层。为了保留句子中的原始信息,我们还在句子中包含了词嵌入的整个矩阵,它本质上对应于ws = 1。
宽度ws表示一个过滤器匹配多少个单词,因此使用更大的ws值对应于在输入句子中匹配更长的n-gram。ws值的范围和blockA和blockB的过滤器数量numFilter是根据验证数据调整的经验选择。
五、Similarity Measurement Layer
在本节中,我们将描述模型的第二部分,相似性度量层。
给定两个输入句子,我们的模型的第一部分并行计算每个句子的表示。比较它们的一种直接方法是将句子表示压平成两个向量,然后使用标准度量,如余弦相似性。然而,这可能不是最优的,因为不同的扁平句子表示区域来自不同的底层来源(例如,不同宽度的组、池的类型、词向量的维等)。扁平化可能会丢弃计算相似度的有用的组成信息。因此,我们对句子表示的特定区域进行结构化比较。
一个重要的考虑是如何识别合适的局部区域进行比较,以便我们能够最好地利用句子表示中的成分信息。有许多可能的方法来对局部比较区域进行分组。这样做,我们考虑以下四个方面:1)是否来自同一个块;2)是否来自窗口大小相同的卷积层;3)是否来自同一池化层;4)是否从相同的滤波器底层卷积层。我们着重于比较至少具有这两种情况的地区。
为了具体说明这一点,我们提供了以下两种算法来识别有意义的局部区域。虽然有其他类似的区域也具备上述条件,但出于对学习效率的考虑,我们并没有对它们进行全部探索;我们发现我们考虑的子集在实践中表现得很好。
5.1 Similarity Comparison Units(相似性比较单元)
我们定义了两个比较单元来比较句子表示中的两个局部区域:
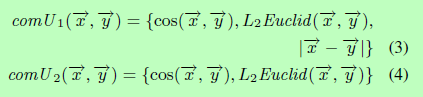
余弦距离(cos)是根据两个向量之间的夹角来度量它们之间的距离,而L2欧氏距离(L2Euclid)和元素间的绝对差(element-wise absolute difference)是度量大小差的。
5.2 Comparison over Local Regions(局部区域比较)

算法1和2展示了在我们的模型中两种句子表示的比较。算法1只对blockA的输出有效,而算法2同时对blockA和blockB有效,只对来自相同池类型和相同块类型输出的区域有效,但卷积层的过滤器和窗口大小不同。
给出两个句子S1和S2,我们将blockA和blockB的最大窗口大小ws设置为n,输出特征在最终的矢量fea中积累。
5.3 One Simplified Example(一个简化的例子)

图五:仅使用blockA的两个句子表示的局部区域比较的简化示例。“横向比较”(算法1)用绿色实线表示,“纵向比较”(算法2)用红色虚线表示。每个句子表示使用窗口大小ws1和ws2,最大/最小/平均池和numFilterA = 3个过滤器。
我们提供了一个简化的工作示例来说明这两种算法如何仅比较blockA的输出。如果我们将句子表示法排列成图5所示的句子矩阵的形状,那么在算法1和2中,我们实际上是在两个方向上比较两个矩阵的局部区域:沿着行和列。
在图5中,max/min/mean组的每一列与同一池组中另一个句子的所有列进行比较。图中的红色虚线显示了这一点,在算法2的第2至9行中列出了这一点。注意,每个池组中的ws1和ws2列都应该使用红色虚线进行比较,但是为了清晰起见,我们在图中省略了这一点。
在水平方向上,每个大小相等的max/min/mean组被提取为一个向量,并与另一个句子对应的组进行比较。对所有行重复此过程,比较用绿色实线表示,如算法1所示。
5.4 Other Model Details(其他模型的细节)
(1)Output Fully-Connected Layer(输出全连接层)
在相似性度量层之上,我们在两个线性层之间叠加一个激活层,然后是一个logsoftmax层作为最后的输出层,输出相似度评分。
(2)Activation Layers(激活层)
我们使用按元素排序的tanh作为所有卷积滤波器和最后两层之间的激活层的激活函数。
六、Experiments and Results
略
七、Discussion and Conclusion
在SICK数据集上,尽管采用了非常不同的方法,依赖树LSTM (Tai et al., 2015)和我们的模型实现了可比较的性能。Tai等人使用句法解析树和门控机制将每个句子转换成一个向量,而我们使用大量灵活的特征提取器,以卷积滤波器的形式,然后比较我们相似性度量层中的特定特征子集。
我们的模型体系结构具有许多信息流路径,这是公认的复杂。虽然我们去掉了功能的手工工程,但是我们增加了大量的功能架构工程。在使用为我们在此考虑的任务提供的小型培训集时,这可能是必要的。我们推测,如果给定大量的训练数据,一个更简单、更深入的神经网络架构可能会优于我们的模型,但是我们把对这个方向的研究留给未来的工作。
综上所述,我们提出了一种基于卷积神经网络的句子相似度模型。我们改进了句子建模和相似性度量。我们的模型在三个数据集上获得了极具竞争力的性能。消融实验表明,我们在句子建模和句子表示局部区域的结构化相似性度量中都使用了多角度,从而提高了性能。未来的工作可以将这个模型扩展到相关的任务,包括问题回答和信息检索。
