一.概述
TextCNN(Convolutional Neural Networks for Sentence Classification) by Yoon Kim作为CNN在NLP文本分类任务上的经典之作,诞生于深度学习和卷积神经网络成为图像任务明星的2012年之后的2014年,让人不得不感慨时势的神奇。
TextCNN提出的目的在于,希望将CNN在图像领域中所取得的成就复制于自然语言处理NLP任务中,以后来人的眼光来看,这无疑是比较成功的,虽然现在仍然很多难点和遗憾。
在TextCNN之前,支持向量机SVM一家独大,模型称霸图像、文本等各种领域,直至2012年图像领域的AlexNet横空出世,撕开了笼罩在人工智能的神秘面纱,深度学习从此开始了它那辉煌的时代。2014年,TextCNN在文本领域的一声狂啸,发出了对文本分类SVM老大位置的挑战,虽然当时TextCNN模型效果没有完全超过SVM,但CNN的热潮,把它推得老高老高,成为NLP文本分类任务的经典模型。
TextCNN是一种采用卷积神经网络(CNN)提取文本n-gram特征,最大池化,全连接然后进行分类的一种新型模型。
为什么TextCNN强于传统的分类模型呢?
图像答约:人工神经网络,更具体地说,是深度网络,因为深度网络能够学习更复杂的特征。
文本答约: 我只有四层(输入、卷积、池化、输出),不算深度模型吧!
回答: 1. 可以算是了,因为NLP任务模型神经网络本来就不深。
2. 另一种说法 ,全局优化大于局部优化、分层优化。具体说来,传统机器学习的做法一般是构建选择文本特征、然后分类;而深度学习的做法是不需要手动构建特征,神经网络会自己构建、选择特征,然后分类,二者是端到端的训练,可以达到一种联动,全局优化,而不是像传统机器学习那样,构建好特征,然后训练的二步模式,局部最优。
只实现了CNN-rand,随机初始化词向量,训练中调整变化。
二.TextCNN网络
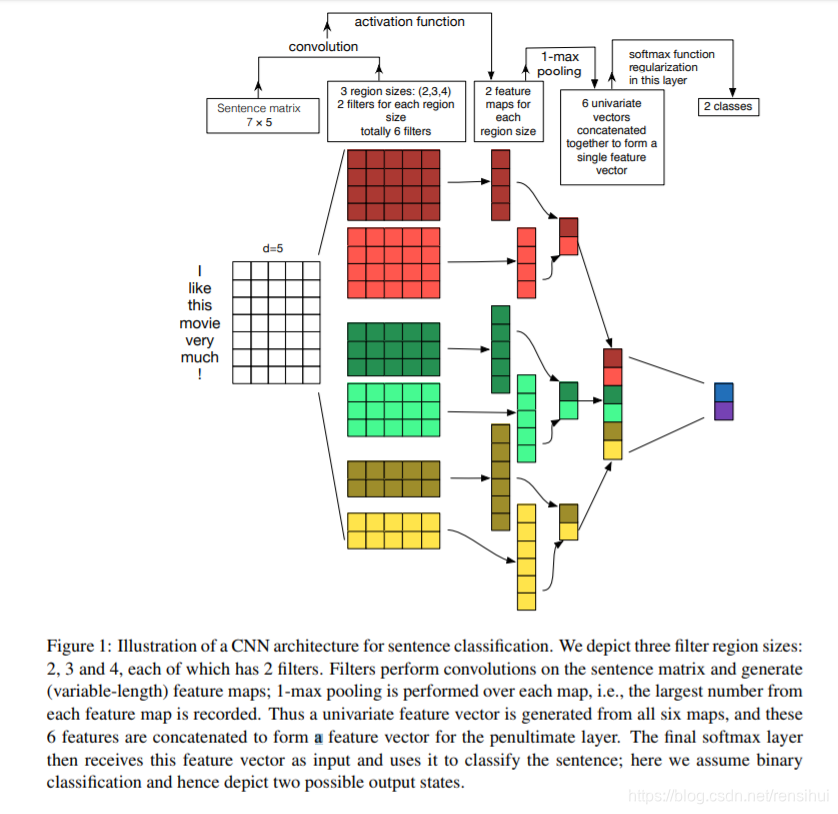
2.1 首先放Yoon Kim的TextCNN开山之作震楼:

从上图可以发现,TextCNN由输入层,卷积层,最大池化层,全连接层等四层构成;
1. 输入层: 一般由是onehot处理后的非负整数构成的向量,这里使用word2vec预训练好的词向量构建(或者随机初始化)。一般都会定义最大文本长度(25啊,50啊什么的),padding实现;
2. 卷积层: 上图中是双通道2*3=6个卷积核,卷积核大小为 卷积大小(n-gram) * 词向量维度(embed) = 2 * 300 = 600,一般卷积大小设2,3,4,5等。论文中实现的是a. CNN-rand(随机初始化词向量);b.CNN-static(word2vec预训练词向量,训练过程中不变);c. CNN-no-static(word2vec预训练词向量,训练过程中微调);d. CNN-multichannel(多个通道,论文中使用的是双通道,即b和c)
现在一般不直接用词向量,会构建Embedding层嵌入。
3. 池化层: 池化层工作与卷积层大同小异,不同于卷积层将卷积核中数据相加;池化层的池化核将池化核中数据求平均或者是只保留最大值。论文中采用的是最大池化,然后级联。
4. 全连接层: 也叫输出层,是池化后级联,再使用图像领域中首先提出的的dropout,防止过拟合(也可加l2正则化b),然后使用激活函数分类输出。
2.2 然后是Ye Zhang关于TextCNN模型的调参
主要是调参,单层CNN调参说明:
1. 词向量维度: 影响不大,动态预训练词向量>静态预训练词向量>随机初始化,word2vec比glove好一点点,词向量维度是300,用别人预训练好的模型;
2. 卷积核尺寸: 影响较大, 一般取1-10。论文中有数据集取7最优,也有取3最优的。最后各种实验得出,首先选出单个最优的,然后再加上它们的相邻数实验,比如说3就是【3,4,5】,7就是【7,8,9】;
3. 卷积核个数: 影响比较大,选择100-600,最好接近600,默认600个卷积核数量;
4. 激活函数: tanh>Iden>relu>sigmod
5. polling池化: 最大池化>平均池化和k-max池化
6. 防止过拟合: dropout设置0.3-0.5,不要超过0.5;l2正则化效果不明确
7. 交叉验证
三.TextCNN实例
1. 代码实现并不难,就一个embedding,conv和pool,超级简单;
2.主体代码
def create_model(self, hyper_parameters):
"""
构建神经网络
:param hyper_parameters:json, hyper parameters of network
:return: tensor, moedl
"""
super().create_model(hyper_parameters)
embedding = self.word_embedding.output
embedding_reshape = Reshape((self.len_max, self.embed_size, 1))(embedding)
# 提取n-gram特征和最大池化, 一般不用平均池化
conv_pools = []
for filter in self.filters:
conv = Conv2D(filters = self.kernel_size,
kernel_size = (filter, self.embed_size),
padding = 'valid',
kernel_initializer = 'normal',
activation = 'relu',
)(embedding_reshape)
pooled = MaxPool2D(pool_size = (self.len_max - filter + 1, 1),
strides = (1, 1),
padding = 'valid',
)(conv)
conv_pools.append(pooled)
# 拼接
x = Concatenate(axis=1)(conv_pools)
x = Flatten()(x)
x = Dropout(self.dropout)(x)
output = Dense(units=self.label, activation=self.activate_classify)(x)
self.model = Model(inputs=self.word_embedding.input, outputs=output)
self.model.summary(120)希望对你有所帮助!
