版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_34613450/article/details/82498211
环境:
Python3.6
Tensorflow-GPU 1.8.0
本文所实现的网络模型是在https://blog.csdn.net/liuchonge/article/details/64440110的基础上搭建的,不同的是为了应对loss为NAN的情况,本文在每一层卷积的后面都添加了一层BN,且comU1只计算cosine距离和L1距离,comU2只计算cosine距离。
基于此,本文只列出训练文件的代码。
首先,对GPU进行设置,并对模型涉及的参数进行设置,如下所示:
#GPU设置
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ['CUDA_VISIBLE_DEVICES'] = "0"
"""各项参数设置"""
#网络参数
tf.flags.DEFINE_integer('sentence_length', 100, 'The length of sentence')
tf.flags.DEFINE_integer('embedding_size', 50, 'The dimension of the word embedding')
tf.flags.DEFINE_integer('num_filters_A', 20, 'The number of filters in block A')
tf.flags.DEFINE_integer('num_filters_B', 20, 'The number of filters in block B')
tf.flags.DEFINE_string('filter_sizes', '1,2,100', 'The size of filter')
tf.flags.DEFINE_integer('num_classes', 6, 'The number of lables')
tf.flags.DEFINE_integer('n_hidden', 150, 'The number of hidden units in the fully connected layer')
tf.flags.DEFINE_float('dropout_keep_prob', 0.5, 'The proability of dropout')
#训练参数
tf.flags.DEFINE_integer('num_epochs', 10, 'The number of epochs to be trained')
tf.flags.DEFINE_integer('batch_size', 32, 'The size of mini batch')
tf.flags.DEFINE_integer('evaluate_every', 100, 'Evaluate model on dev set after this many steps(default:100)')
tf.flags.DEFINE_integer('checkpoint_every', 100, 'Save model after this many steps(default;100)')
tf.flags.DEFINE_integer('num_checkpoints', 5, 'The number of checkpoints to store(default:5)')
#L2正则项
tf.flags.DEFINE_float('lr', 1e-3, 'The learning rate of this model')
tf.flags.DEFINE_float('l2_reg_lambda', 1e-4, 'The regulatization parameter')
#设备参数
tf.flags.DEFINE_boolean('allow_soft_placement', True, 'Allow device soft device placement')
tf.app.flags.DEFINE_boolean('log_device_placement', False, 'Log placement of ops on devices')
"""各项参数设置"""
FLAGS = tf.flags.FLAGS
FLAGS.flag_values_dict()
print('\nParameters:')
for attr, value in sorted(FLAGS.__flags.items()):
print('{}={}'.format(attr.upper(), value))
print('')设置完参数之后,我们需要读取数据:
#glove是载入的词向量。glove.d是单词索引字典<word, index>,glove.g是词向量矩阵<词个数,300>
print('loading glove...')
glove = emb.GloVe(N=50)
print('==============GloVe模型载入完毕!===================')
print("Loading data...")
Xtrain, ytrain = data_helper.load_set(glove, path='./sts/semeval-sts/all')
Xtrain[0], Xtrain[1], ytrain = shuffle(Xtrain[0], Xtrain[1], ytrain)
#[22592, 句长]
Xtest, ytest = data_helper.load_set(glove, path='./sts/semeval-sts/2016')
Xtest[0], Xtest[1], ytest = shuffle(Xtest[0], Xtest[1], ytest)
#[1186, 句长]
print('==============数据载入完毕!===================')建议采用将读取GloVe模型进行封装已具备更好的代码健壮性。
继而,我们就需要编写训练模型的代码:
"""Start the MPCNN model"""
with tf.Graph().as_default():
session_config = tf.ConfigProto(allow_soft_placement = FLAGS.allow_soft_placement,
log_device_placement = FLAGS.log_device_placement)
session_config.gpu_options.allow_growth = True
session = tf.Session(config=session_config)
with session.as_default():
"""定义输入输出等placeholder"""
input_1 = tf.placeholder(tf.int32, shape=[None, FLAGS.sentence_length], name='input_x1')
input_2 = tf.placeholder(tf.int32, shape=[None, FLAGS.sentence_length], name='input_x2')
input_3 = tf.placeholder(tf.float32, shape=[None, FLAGS.num_classes], name='input_y')
dropout_keep_prob = tf.placeholder(tf.float32, name='dropout_keep_prob')
print('占位符构建完毕!')
with tf.device('/cpu:0'), tf.name_scope('embedding'):
s0 = tf.nn.embedding_lookup(glove.g, input_1) #此时输入变量的shape为3维
s1 = tf.nn.embedding_lookup(glove.g, input_2)
print('embedding转换完毕!')
with tf.name_scope('reshape'):
# input_x1 = tf.expand_dims(s0, -1) #将输入变量转换为符合的Tensor4维变量
# input_x2 = tf.expand_dims(s1, -1)
input_x1 = tf.reshape(s0, [-1, FLAGS.sentence_length, FLAGS.embedding_size, 1])
input_x2 = tf.reshape(s1, [-1, FLAGS.sentence_length, FLAGS.embedding_size, 1])
input_y = tf.reshape(input_3, [-1, FLAGS.num_classes])
print('reshape完毕!')
#构建MPCNN模型
model = MPCNN(num_classes=FLAGS.num_classes, embedding_size=FLAGS.embedding_size,
filter_sizes=[int(size) for size in FLAGS.filter_sizes.split(',')],
num_filters=[FLAGS.num_filters_A, FLAGS.num_filters_B],
n_hidden = FLAGS.n_hidden,
input_x1=input_x1,
input_x2=input_x2,
input_y=input_y,
dropout_keep_prob=FLAGS.dropout_keep_prob,
l2_reg_lambda = FLAGS.l2_reg_lambda)
print('MPCNN模型构建完毕!')
global_step = tf.Variable(0, name='global_step', trainable=False)
# 获得模型输出
print('================模型计算相似性得分====================')
model.similarity_measure_layer()
print('===============模型计算完毕========================')
optimizer = tf.train.AdamOptimizer(FLAGS.lr)
grads_and_vars = optimizer.compute_gradients(model.loss)
train_step = optimizer.apply_gradients(grads_and_vars, global_step=global_step)
timestamp = str(int(time.time()))
out_dir = os.path.abspath(os.path.join(os.path.curdir, "runs", timestamp))
# print("Writing to {}\n".format(out_dir))
#
loss_summary = tf.summary.scalar("loss", model.loss)
acc_summary = tf.summary.scalar("accuracy", model.accuracy)
#
train_summary_op = tf.summary.merge([loss_summary, acc_summary])
train_summary_dir = os.path.join(out_dir, "summaries", "train")
train_summary_writer = tf.summary.FileWriter(train_summary_dir, session.graph)
#
dev_summary_op = tf.summary.merge([loss_summary, acc_summary])
dev_summary_dir = os.path.join(out_dir, "summaries", "dev")
dev_summary_writer = tf.summary.FileWriter(dev_summary_dir, session.graph)
#
# checkpoint_dir = os.path.abspath(os.path.join(out_dir, "checkpoints"))
# checkpoint_prefix = os.path.join(checkpoint_dir, "model")
# if not os.path.exists(checkpoint_dir):
# os.makedirs(checkpoint_dir)
# saver = tf.train.Saver(tf.global_variables(), max_to_keep=conf.num_checkpoints)
def train(x1_batch, x2_batch, y_batch):
"""
A single training step
"""
feed_dict = {
input_1: x1_batch,
input_2: x2_batch,
input_3: y_batch,
dropout_keep_prob: 0.5
}
_, step, summaries, batch_loss, accuracy = session.run(
[train_step, global_step, train_summary_op, model.loss, model.accuracy],
feed_dict)
time_str = datetime.datetime.now().isoformat()
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, batch_loss, accuracy))
train_summary_writer.add_summary(summaries, step)
def dev_step(x1_batch, x2_batch, y_batch, writer=None):
"""
Evaluates model on a dev set
"""
feed_dict = {
input_1: x1_batch,
input_2: x2_batch,
input_3: y_batch,
dropout_keep_prob: 1
}
_, step, summaries, batch_loss, accuracy = session.run(
[train_step, global_step, dev_summary_op, model.loss, model.accuracy],
feed_dict)
time_str = datetime.datetime.now().isoformat()
dev_summary_writer.add_summary(summaries, step)
# if writer:
# writer.add_summary(summaries, step)
return batch_loss, accuracy
session.run(tf.global_variables_initializer())
print('模型参数初始化完毕!')
print('生成batch')
batches = data_helper.batch_iter(list(zip(Xtrain[0], Xtrain[1], ytrain)), FLAGS.batch_size, FLAGS.num_epochs)
print('batch生成完毕!')
print('Start Training......')
for batch in batches:
x1_batch, x2_batch, y_batch = zip(*batch)
train(x1_batch, x2_batch, y_batch)
current_step = tf.train.global_step(session, global_step)
if current_step % FLAGS.evaluate_every == 0:
total_dev_loss = 0.0
total_dev_accuracy = 0.0
print("\nEvaluation:")
dev_batches = data_helper.batch_iter(list(zip(Xtest[0], Xtest[1], ytest)), FLAGS.batch_size, 1)
for dev_batch in dev_batches:
x1_dev_batch, x2_dev_batch, y_dev_batch = zip(*dev_batch)
dev_loss, dev_accuracy = dev_step(x1_dev_batch, x2_dev_batch, y_dev_batch)
total_dev_loss += dev_loss
total_dev_accuracy += dev_accuracy
total_dev_accuracy = total_dev_accuracy / (len(ytest) / FLAGS.batch_size)
print("dev_loss {:g}, dev_acc {:g}, num_dev_batches {:g}".format(total_dev_loss, total_dev_accuracy,
len(ytest) / FLAGS.batch_size))
print("Optimization Finished!")如此,整个训练文件就编写完毕!
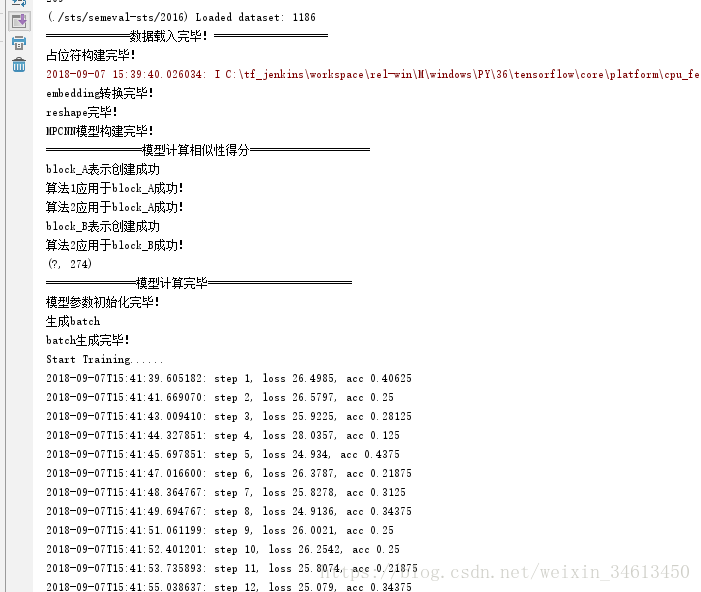
执行之后,结果如下所示: