文章地址:https://arxiv.org/pdf/1602.07019.pdf
文章标题:Sentence Similarity Learning by Lexical Decomposition and Composition(通过词汇分解和组合进行句子相似度学习)COLING2016
Abstract
传统的句子相似度分析方法只关注两个输入句子中相似的部分,而忽略了不相似的部分,这往往会给我们一些线索和句子的语义意义。在这项工作中,我们提出了一个模型,通过对句子进行词汇语义的分解和组合来兼顾相似和不同之处。该模型将每个单词表示为一个向量,并根据另一个句子中的所有单词计算每个单词的语义匹配向量。然后根据语义匹配向量将每个词向量分解为相似成分和不相似成分。在此基础上,采用双通道CNN模型,通过组合相似和不同的组件来捕获特征。最后,对合成的特征向量进行相似度评分。实验结果表明,该模型在回答句选择任务上取得了较好的效果,在意译识别任务上也取得了较好的效果。
一、Introduction
句子相似度是衡量一对句子之间可能性大小的基本尺度。它在NLP和IR社区的各种任务中都扮演着重要的角色。例如,在释义识别任务中,使用句子相似度来判断两个句子是否属于释义(Yin and Sch¨utze, 2015;He et al., 2015)。在回答问题和信息检索任务中,使用查询-答案对之间的句子相似性来评估所有候选答案的相关性和排序(Severyn和Moschitti, 2015;Wang and Ittycheriah, 2015)。

表一:句子相似学习的例子,其中sockeye意思是“红鲑鱼”,coho意思是“银鲑鱼”。“coho”和“sockeye”属于鲑鱼科,而“鲆”则不属于。
然而,句子相似度学习面临以下挑战:
- 语义等价的句子之间存在词汇差异。以表1中的E1和E2为例,它们的含义相似,但词汇不同。
- 语义相似度应该在不同的粒度级别(单词级、短语级和语法级)进行测量。例如,当与E1中的“不相干”相匹配时,E2中的“不相关”是一个不可分割的短语(方括号所示)。
- 两个句子之间的差异(用尖括号表示)也是一个重要的线索(Qiu et al., 2006)。例如,通过判断不同的部分,我们可以很容易地识别出E3和E5有相同的意思“这是关于鲑鱼的研究”,因为“sockeye”属于鲑鱼科,而“der”不属于。然而E4的含义与E3截然不同,E3强调“研究红色(一种特殊的)鲑鱼”,因为“红鲑”和“红鲑”都属于鲑鱼家族。如何提取和利用这些信息是另一个挑战。
为了应对上述挑战,研究者们长期致力于句子相似度算法的研究。为了弥补词汇差距(挑战1),提出了一些词相似度指标来匹配不同但语义相关的词。例如,基于知识的度量(Resnik, 1995)和基于语料库的度量(Jiang和Conrath, 1997;Yin和Sch¨utze, 2015;He et al., 2015)。为了测量不同粒度的句子相似性(挑战2),研究人员探索了从n-gram、连续短语、不连续短语和解析树中提取的特征(Yin和Sch¨utze, 2015;He et al., 2015;Heilman和Smith, 2010)。第三个挑战没有得到太多的关注在过去,秋的唯一相关工作(2006)。探讨了不同句子之间的一对解释识别任务,但是他们需要人工注释来训练分类器,和他们的表现仍低于预期。
在本文中,我们提出了一个新的模型,通过对句子进行词汇语义的分解和组合来共同应对这些挑战。给出一个句子,每个单词模型表示作为一个低维向量(挑战1),并计算出每个单词的语义匹配向量基于其他单词的句子(挑战2)。然后基于语义匹配向量,每个词向量分解成两个部分:一个相似的成分和一个不同的成分(挑战3)。我们用所有单词的相似成分来表示句子对的相似部分,用每个单词的不同成分来显式地建模不同的部分。然后进行双通道CNN操作,将相似和不同的成分合成一个特征向量(挑战2和3),最后利用合成的特征向量预测句子的相似度。在两个任务上的实验结果表明,我们的模型在回答句选择任务上取得了最先进的效果,在意译识别任务上也取得了类似的结果。
在接下来的部分中,我们首先简要概述了我们的模型(第2部分),然后详细介绍了我们的端到端实现(第3部分)。
二、Model Overview
在这一节中,我们提出了一个句子相似学习模型来处理这三个挑战(在第一节中提到)。为了处理第一个挑战,我们将每个单词表示为一个分布式向量,这样我们就可以计算形式上不同但语义上相关的单词的相似度。为了解决第二个问题,我们假设每个单词都可以由另一个句子中的几个单词进行语义匹配,然后根据另一边的所有单词向量计算每个单词向量的语义匹配向量。为了应对第三个挑战,我们假设每个语义单元(词)可以部分匹配,并根据其语义匹配向量将其分解为相似的成分和不同的成分。

图一:模型概述
图1显示了句子相似度模型的概述。给定一对句子S和T,我们的任务是计算相似度评分sim(S, T),步骤如下:
(1)Word Representation(词表示)
Mikolov等(2013)的词嵌入是处理句子相似度任务中词汇间隙挑战的一种有效方法,它用一个分布向量表示每个单词,出现在相似上下文中的单词往往具有相似的含义(Mikolov等,2013)。通过这些预先训练好的嵌入,我们将S和T转换成句子矩阵S = [s1,…,si,…,sm], T = [t1,…,tj,…,tnj,其中,si和tj为对应单词的d维向量,m和n分别为S和T的句子长度。
(2)Semantic Matching(语义匹配)
为了判断两个句子之间的相似性,我们需要检查一个句子中的每个语义单位是否被另一个句子所覆盖,反之亦然。例如,在表1中,为了检查E2是否为E1的转述,我们需要知道E1中的“无关”一词是否与E2中的“不相关”相匹配或相对应。在我们的模型中,我们把每个词作为一个原始语义单元,并计算每个词的语义匹配向量si如果通过组合部分或完整词向量在另一个句子T。通过这种方式,我们可以匹配一个单词如果一个词或短语在T。同样,相反方向也一样,我们也算所有语义匹配向量tj在T。
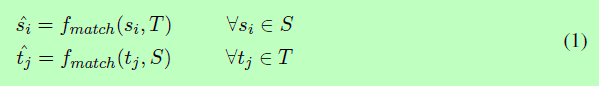
我们将在后面的第3节中讨论不同的fmatch函数。
(3)Decomposition(分解)
语义匹配阶段后,我们的语义匹配向量si和tj。我们解释ˆsi(或ˆtj)词的语义覆盖si(或tj)的句子T(或S)。然而,没有必要所有的语义si(或tj)完全由ˆsi(或ˆtj)。以表1中的E1和E2为例,E1中的单词“sockeye”只与E2中的单词“salmon”(相似的部分)部分匹配,因为“sockeye”的全部含义是“red salmon”(“red”的语义是不同的部分)。出于这一现象,我们的模型进一步分解词si(或tj),基于其语义匹配向量ˆsi(或ˆtj),分为两部分:类似的组件si+(或tj+)和不同的组件si-(或tj-)。形式上,我们将分解函数定义为:
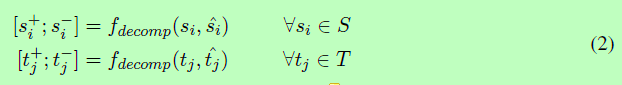
(4)Composition(组合)
给出一个相似的分量矩阵S+= [ S1+,…,Sm+ ](或T+=[ T1+,…Tn+ ])和一个不同的成分矩阵S−= [ S1-,…,Sm- ](或T−=[ T1-,…,Tn- ]),我们这一步的目标是如何利用这些信息。除了邱等人(2006)认为两句之间仅不同部分的意义对它们的相似性有很大的影响外,我们还认为不同部分和相似部分之间有很强的联系。例如,在表1中,如果我们只看不同或相似的部分,很难判断E4和E5之间哪个更像E3。当我们同时考虑相似和不同的部分时,我们可以很容易地确定E5与E3更相似。因此,我们的模型将相似分量矩阵和不同分量矩阵合成一个特征向量S(或T),合成函数为:

(5)Similarity assessing(相似性评估)
在最后阶段,我们将两个特征向量(S和T)连接起来,预测最终的相似度评分:

三、An End-to-End Implementation(一个端到端的实现)
第2节向我们展示了我们的模型。在本节中,我们将详细描述每个阶段。
3.1 Semantic Matching Functions(语义匹配函数)
本节描述了我们的语义匹配函数fmatch(公式1)。fmatch的目标是通过组合向量从T生成一个语义匹配向量ˆsi。
对于一个句子对S和T,我们首先计算一个相似矩阵Am×n,计算单词si和tj之间的余弦相似度作为其中每个元素aij的表示:
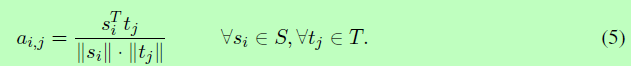
然后在Am×n上定义三个不同的语义匹配函数:
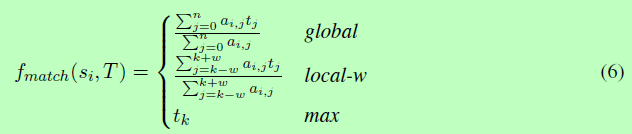
global函数的概念是考虑所有词向量tj在T。语义匹配向量ˆsi是T中所有词tj的一个加权和向量,其中每个重量是规范化的词相似aij。max函数移到了另一个极端。它通过从t中选择最相似的词向量tk生成语义匹配向量。local-w函数在global和max之间进行折中,其中w表示以k(最相似的词位置)为中心要考虑的窗口大小。因此,语义匹配向量是从tk-w到tk+w的加权平均向量。
3.2 Decomposition Functions(分解函数)
本节描述了分解的实现函数fdecomp(公式2)。fdecomp分解是一个词的字向量sj基于其语义匹配向量ˆsj到类似组件si+和一个不同的组件si−我,其中si+表示如果由ˆsi的语义,si−表示未被发现的一部分。我们实现了三种类型的分解函数:刚性、线性和正交。
刚性分解只适用于fmatch的最大版本。首先,它检测是否存在一个完全匹配的词在其他句子,或者如果si等于ˆsi。如果是,则将向量si分配给相似的分量si+,而将不同的分量分配给0向量0。否则,向量si被赋给不同的分量si-。式(7)给出了正式定义:

线性分解的动机是,si和ˆsi之间越相似,更高的si比例应该分配给相似的成分。首先,我们计算si与ˆsi之间的余弦相似度α。然后,我们将si线性分解。式(8)给出了相应的定义:

正交分解是对几何空间中的向量进行分解。基于语义匹配向量ˆsi,我们的模型将si分解成平行分量和垂直分量。将平行分量视为相似分量si+,将垂直分量视为不同分量si-。式(9)给出了具体的定义。
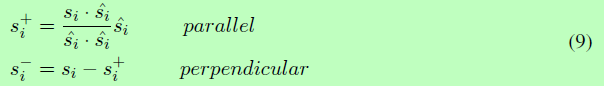
3.3 Composition Functions(复合函数)
式(3)中的复合函数fcomp的目的是从相似的成分矩阵和不同的成分矩阵中提取特征。我们还希望在合成阶段获得各种粒度的相似性和差异性。受到Kim(2014)的启发,我们使用了一个双通道卷积神经网络(CNN),并设计了基于各种n-gram阶的滤波器,例如unigram、bigram和trigram。
CNN模型包含两个顺序操作:卷积和最大池。对于卷积运算,我们定义了一个过滤器列表{wo}。每个滤波器的形状为d×h,其中d为字向量的维数,h为窗口大小。每个过滤器应用于两个来自相似和不同通道的补丁(一个窗口大小为h的向量),并生成一个特征。式(10)表达了这一过程。
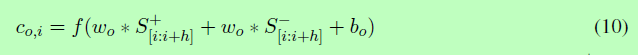
A*B操作将B中所有的元素与A中相应的权值相加,S+和S−表示来自S+和S−的patch, bo是一个偏置项,f是一个非线性函数(我们在本文中使用tanh)。我们将这个过滤器应用于所有可能的补丁,并产生一系列的特征~co=[co,1, co,2,…]。co中特征的数量取决于滤波器wo的形状和输入句子的长度。为了处理可变的特征大小,我们通过选择最大值co=max(co)来对~co执行最大池操作。因此,在这两个操作之后,每个过滤器只生成一个特性。我们通过改变窗口大小和初始值来定义几个过滤器。最后,通过组合两个分量矩阵来获取特征向量,特征维数等于过滤器的数量。
3.4 Similarity Assessment Function(相似度评价函数)
式(4)中的相似度评价函数fsim以两个特征向量为输入,预测相似度得分。我们使用一个线性函数来总结所有的特征,并应用一个s形函数来限制在[0,1]范围内的相似性。
3.5 Training
我们通过训练集的可能性最大化来训练我们的句子相似模型。训练集中的每个训练实例都表示为一个三元组(Si, Ti, Li),其中Si和Ti是一对句子,Li 2{0,1}表示它们之间的相似性。如果Ti是用于意译识别任务的Si的意译,或者Ti是用于回答句子选择任务的Si的正确答案,我们分配Li = 1。否则,我们赋值Li = 0。我们使用Theano (Bastien et al., 2012)实现数学表达式,并使用Adam (Kingma and Ba, 2014)进行优化。
四、Experiment
4.1 Experimental Setting
略
4.2 Model Properties(模型属性)
略
4.3 Comparing with State-of-the-art Models(与最先进的模型相比)
在本小节中,我们在QASent、WikiQA和MSRP的测试集上评估了我们的模型。
- QASent dataset
- WikiQA dataset
- MSRP dataset
五、Related Work
3.1小节中的语义匹配函数灵感来源于基于注意的神经机器翻译(Bahdanau et al., 2014;Luong et al., 2015)。但是,以前的大部分工作只在LSTM模型中使用注意机制。而我们的模型将注意力机制引入到CNN模型中。类似的工作还有Yin等人(2015)提出的基于注意力的CNN模型。他们首先为一个句子对建立一个注意矩阵,然后直接将注意矩阵作为CNN模型的一个新通道。不同的是,我们的模型使用注意矩阵(或相似矩阵)将原始的句子矩阵分解成相似的成分矩阵和不同的成分矩阵,然后将这两个矩阵输入到一个双通道CNN模型中。然后,该模型可以重点关注句子对中相似和不同部分之间的交互作用。
六、Conclusion
在这项工作中,我们提出了一个通过分解和组合词汇语义来评估句子相似度的模型。为了解决词汇鸿沟问题,我们的模型用上下文向量表示每个单词。为了从句子对的相似度和不相似度中提取特征,我们设计了几种方法将词向量分解成相似成分和不相似成分。为了在多个粒度级别提取特征,我们使用了一个双通道CNN模型,并为其配备了多种类型的ngram过滤器。实验结果表明,该模型在回答句选择和意译识别两方面都有较好的效果。
