QQ 1285575001
Wechat M010527
技术交流 QQ群599020441
纪年科技aming

递归 循环神经网络 RNN
- 不同于 神经网络 /卷积
- 输入batch -n
- 调节权重参数 w b
- b 无关联关系
- batch–>更新w/b
RNN b有相互关系
- 其希望传入的值
- 接收 序列化数据输入
- b1 --> 时间/序列 联系b2 后同
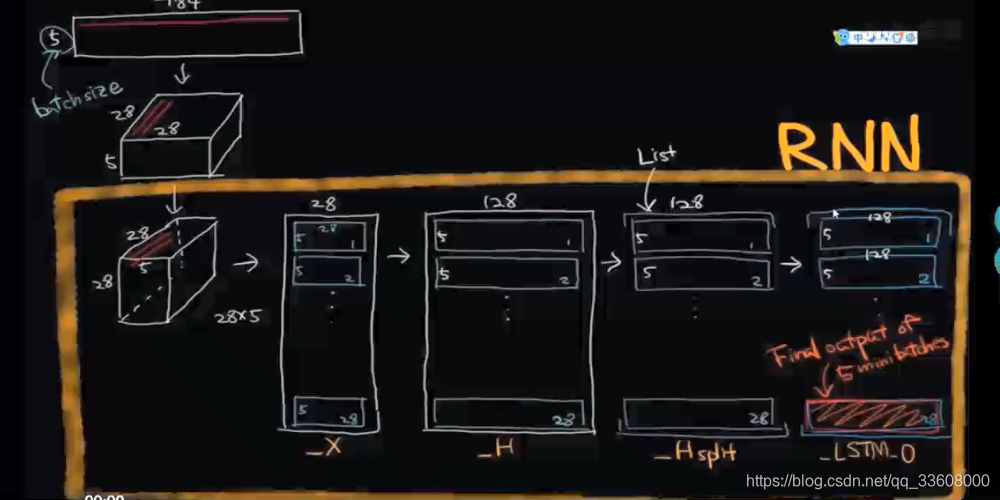
mnis神经网络数据集 28*28
完整数据---->数据序列化预处理
像素点 行标号 转换 ----> 序列化
进行跑神经网络 基于这些数据 预测
+
前一时间段 预测结果 ---->最终决策
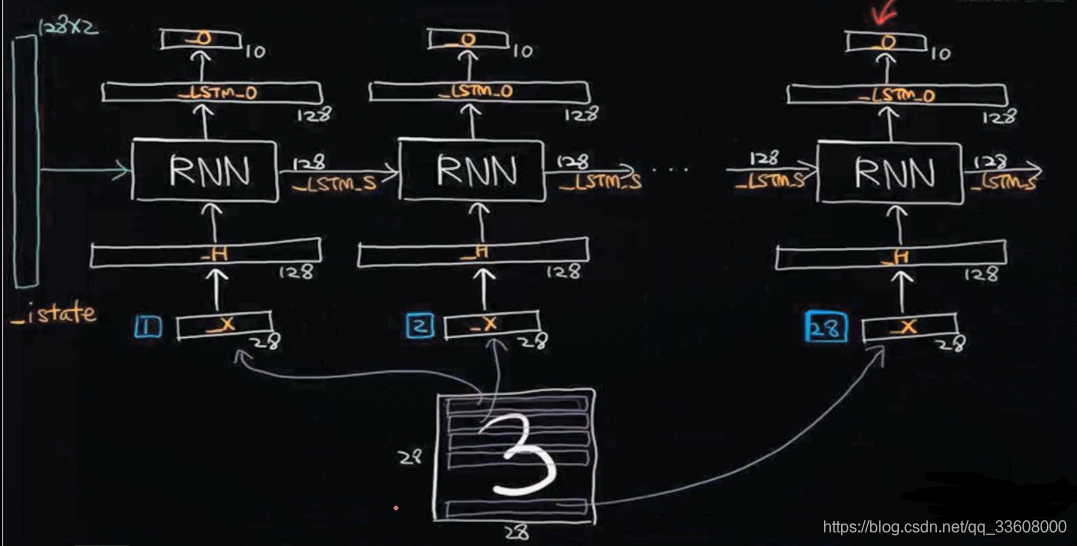
RNN网络结构
eg:28个序列
1序列 与_H隐层相连 1x28 向量 设置128神经元 => 1x128
-
矩阵初始化 w = 28x128 权重矩阵
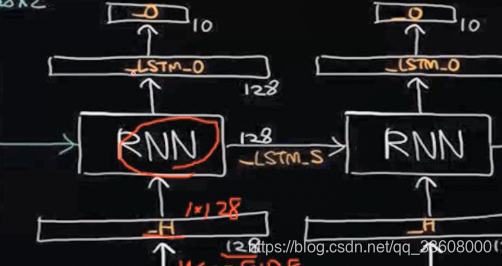
通过 中间隐层 ----> RNN _LSTM计算单元 (许多门单元处理 *前后序列 结果计算输入 筛选 保留忘记 组合信息)
-
触发两个输出
-
LSTM_O 结果特征向量
-
LSTM_S 中间结果
-
_O 与分类任务 相连
引入 一个 W参数矩阵 128x10 10类别概率值 -
_S 中间结果 与下一序列 输入相连
-
同时考虑 这一序列阶段输入/上一阶段输出
-
有用信息组合 输出 2_S 2_O
- 27_S ( 第28引用的 中间变量 )
- 阶段结果 效果综合 —> 引入原始输入 综合单元 输出 = 总结输出值
- 综合效果在 最后一个门单元输出 (最后样本 输出值 OUT = 分类概率值/得分值 )

前27 给 第28提供候选特征 RNN分类任务
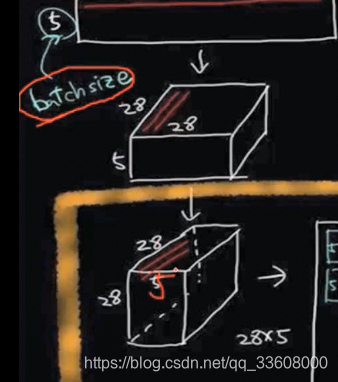

- 引入模型
- 选择batchsize
- 数据预处理
- 通过中间隐层
- 拆分序列
- 通过RNN
- LSTM计算单元 算出来
- 得到预测结果
NLP自然语言处理 重要神经网络 ——RNN 递归神经网络
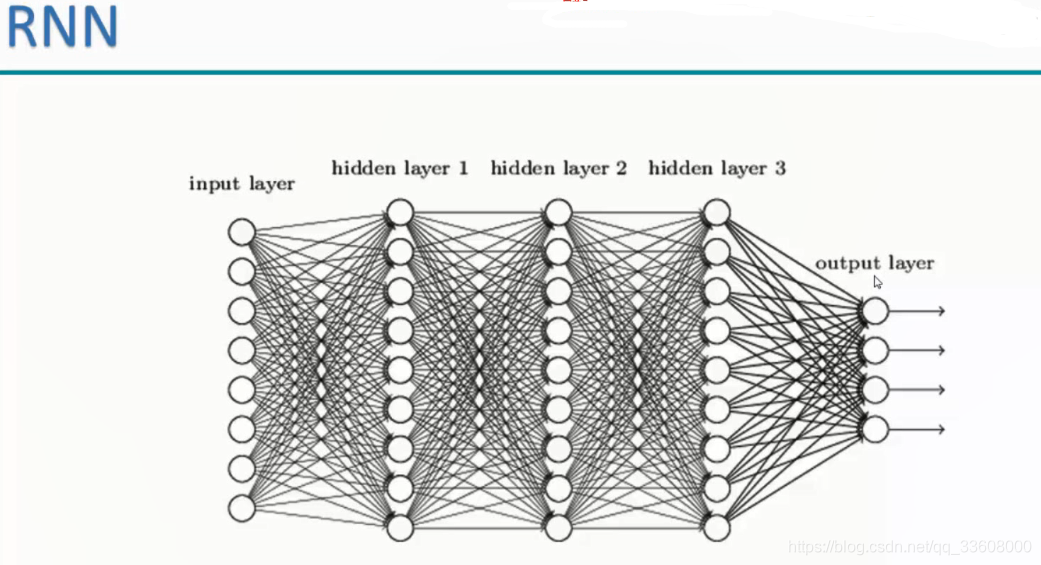
- 与传统神经网络 的不同
- 数据层------>输入层(中间隐层 xx隐层)-----> 最终结果
- input 数据层 (像素点)拉长 ----> 多层权重 变换 ----> w1 —wx----最终结果
- 权重层多输入组合 (组合数据单独处理)
- 每一次 数据不互相 组合影响 传递更新W权重参数 (无关)
- 每一个 数据 对之前之后 没有影响 (独立)
- 实际生活中 有联系 相关(上下文)
(- 预测下一句)递归神经网络
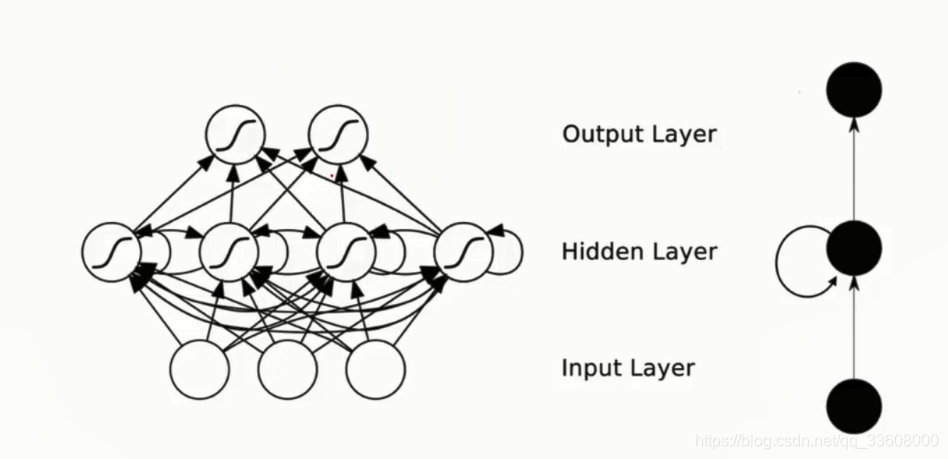
- input 输入 —> 中间隐层 循环递归操作 —> 权重W组合 ---->中间信息特征(当前输入+ 之前中间值)
- 信息有保留 有循环
网络结构
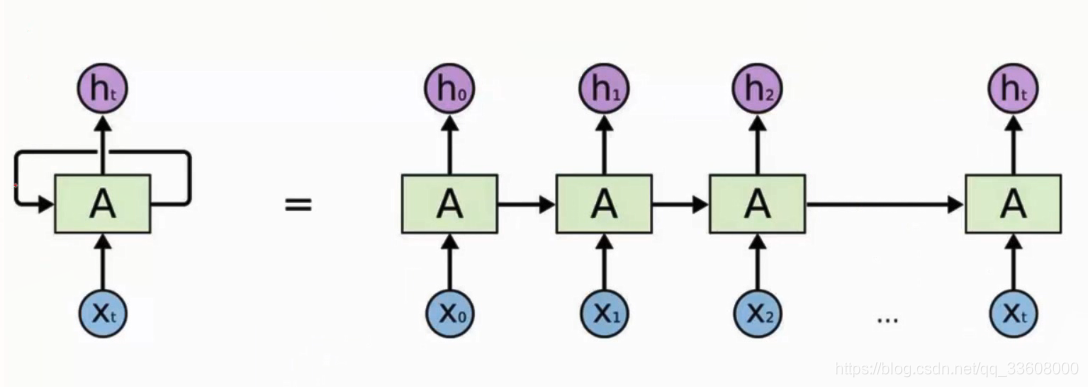
- X0----输入> U值矩阵 (x 与 U特征组合) ----> 中间(记忆单元 记录信息)----权重W0> 下一次输入
- X1 ----输入/前一次输入 (有价值的信息)---->
- … 得到Ht 最终组合结果
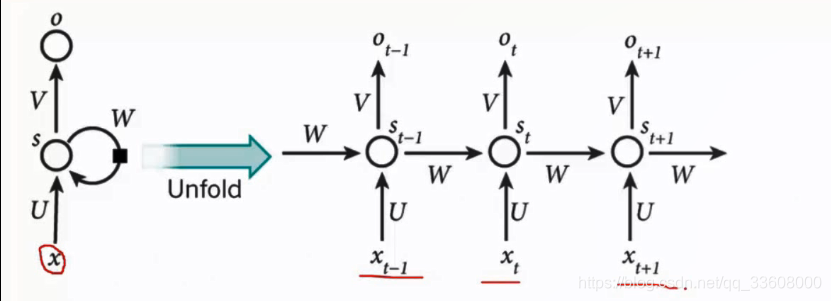

- 根据任务不同 调整
话 —> 分词 ----> 输入RNN (每一步)
中间结果(考虑需求) - ST 记忆单元 (储存这层输入 + 前输入 组合 )
- u W 权重参数矩阵 矩阵组合
- st 与权重参数矩阵组合 (特征再提取)以此反复
- 当前输入·f 值 (不仅仅与特征组合 + 非线性激活函数)
- ot 每一步 输出 记忆信息提取 对ST进行全链接操作
- V矩阵 全连接 分成 xx · n 的矩阵
- 分类出 得到概率值 Ot 向量转换成 概率
所以 RNN 适合做NLP
- 卷积神经网络 除了 网络结构不同 输入输出类似(计算机视觉 没有强调先后关系 *相互独立 )
- RNN 关联上下文 (符合人类趋势 )
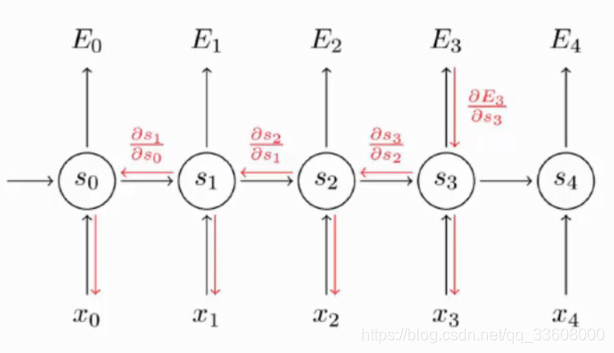
神经网络 反向传播(更新)
输入 —>得到 唯一输出值
- 输出值 —> 求mel函数 /lot值 ,求偏导 累乘(链式法则)
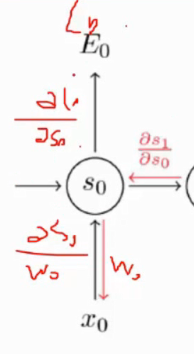
- RNN 有记忆单元
- 连最近的 贡献 看当前输入连接
- W3 的更新 Wt1 Wtn的更新 (梯度传播)求传播途径 偏导
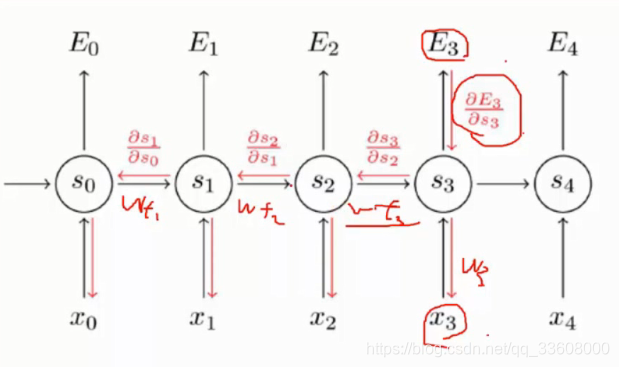
- 最后的 对所有进行更新(对之前的进行更新)(类似 卷积神经网络 进行更新)
- 跟传统神经网络不同 需要将之前的 全部更新
局限性
NLP 一句话 ---->分词
从第一个词开始记 -->向下传递 (如预测 第200个词 之前的效用不大)
- 影响RNN 数据不做预处理 效果不好
- 离的近的 关系大 离得远的 游乐程度越低
- 输入的多 记得多 神经网络庞大 信息大量无用
- 梯度传播 回传 计算量大 (梯度消失问题 ≈ 0 参数无法更新)
- 链式法则 累积为0 量大网络 不必要间隙
递归网络问题优化 升级
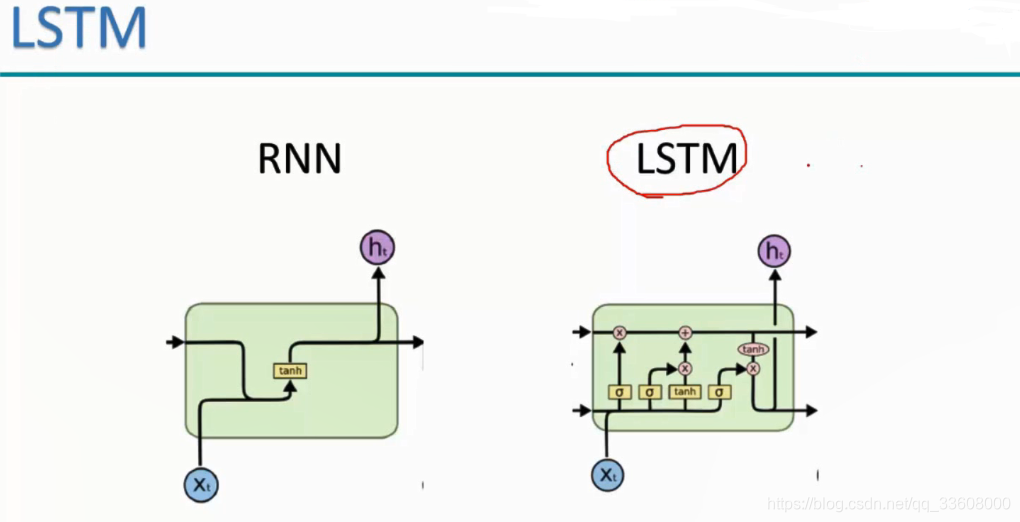
- 长短记忆网络
- 结构不同
RNN st-1 组合 tanh激活 —>ht
LSTM st-1 输入 结构更复杂
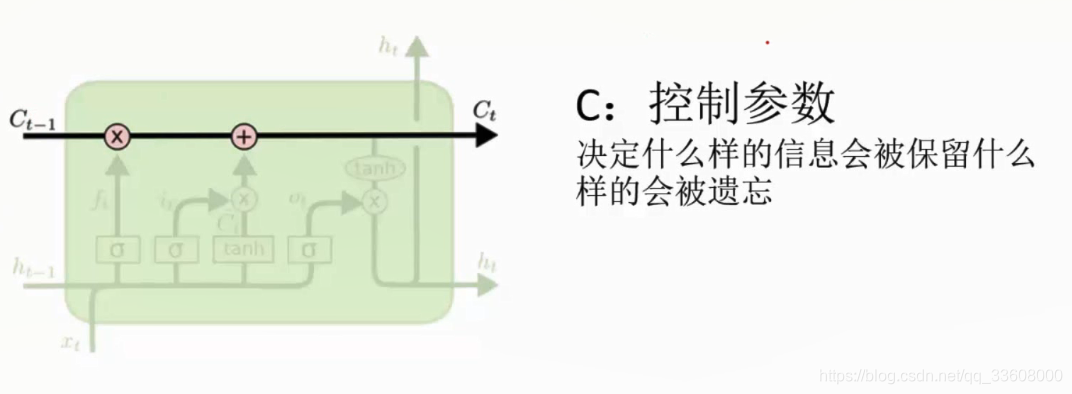
- list 中 根据训练得值C 特征部分保留
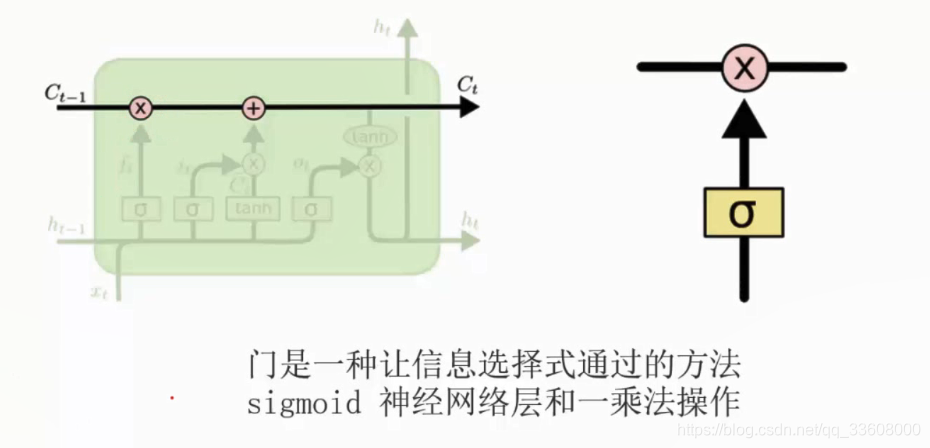
- 门单元
- sigmoid 函数 (把所有的输入 压缩到 0/1区间上)

- 记忆 0 与 1
- 门单元 /神经元
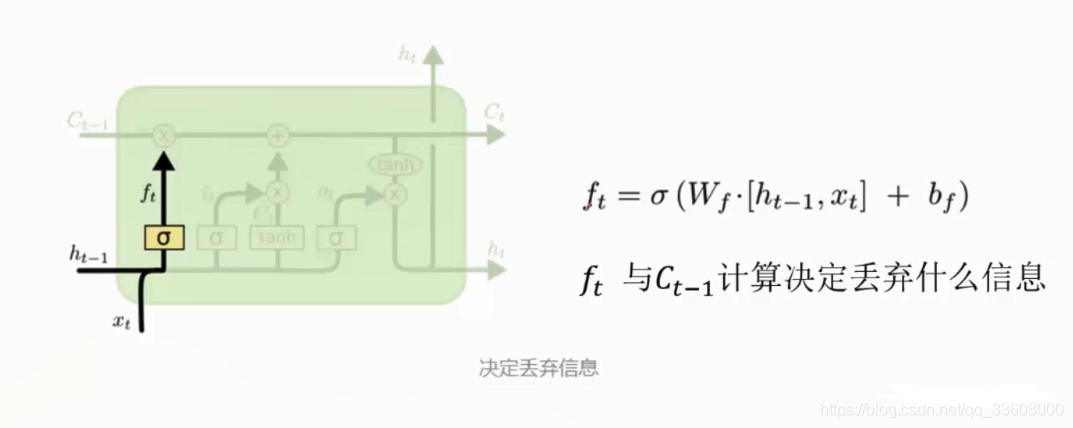
- 第一步 丢弃
- xt 数据
- ht-1 中间结果
- 组合 之后 通过激活函数 sigmoid
- 得到ft 0-1范围
- ft 与 Ct-1 组合乘法操作 有选择丢弃
- Ct 维护更新 保留
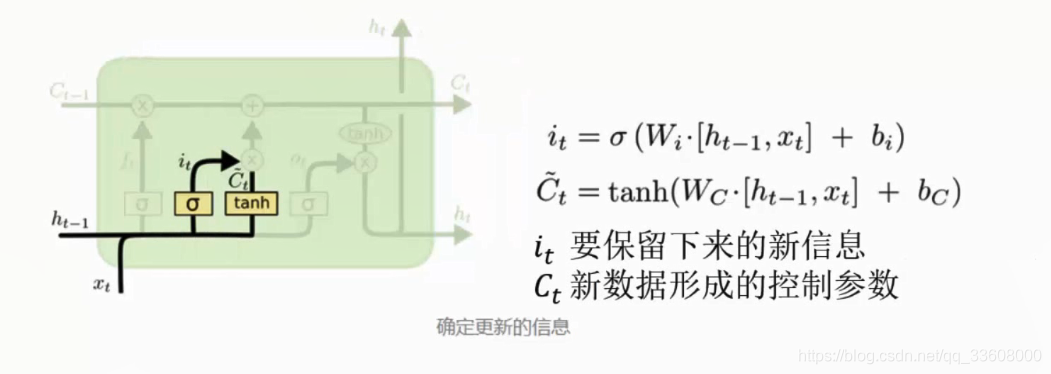
- 保存信息门单元
- it 保留 与 Ct进行组合 加法
串子组合
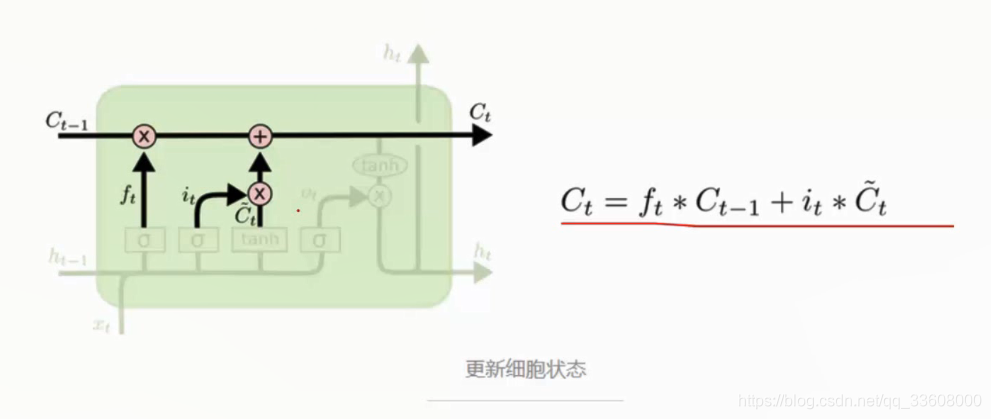
- Ct 更新 = 遗忘+ 保留 (小Ct参数 与 it组合)
- 得到新的Ct 迭代更新
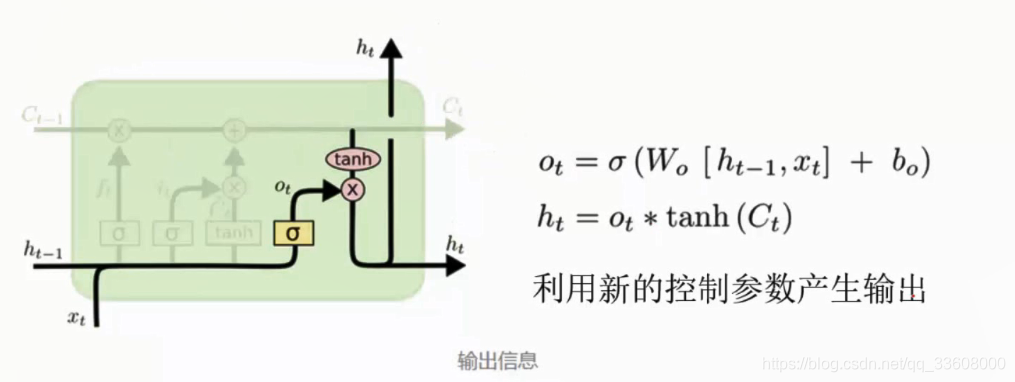
- ht 输出值
- 数据(前加后)与 Ct 再组合 (去留)
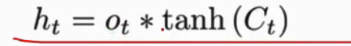
- 核心 控制参数更新
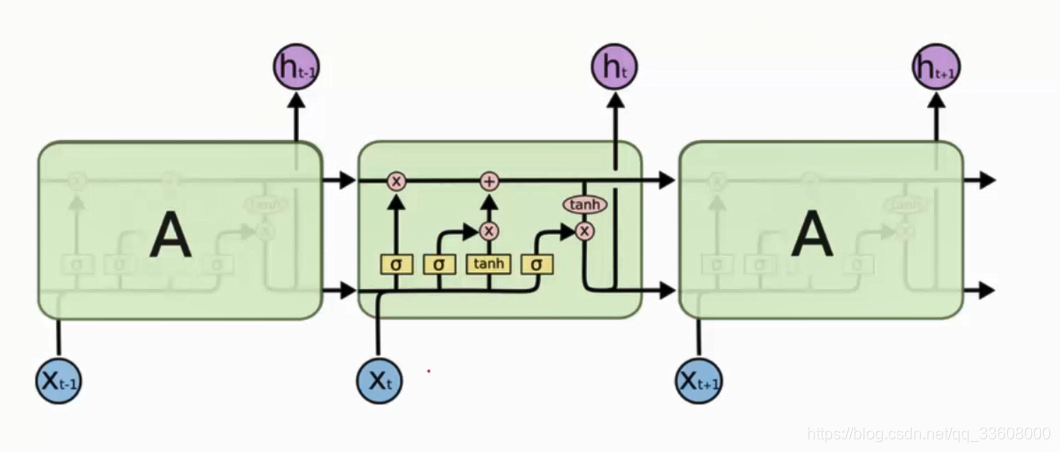
- 网络 利用细节 更变
- 得到ht+1 结果
