论文:Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
一、从神经网络开始
神经网络包括前向过程和后向过程,前向过程定义网络结构,后向过程对网络进行训练(也就是优化参数),经过多轮迭代得到最终网络(参数已定)。
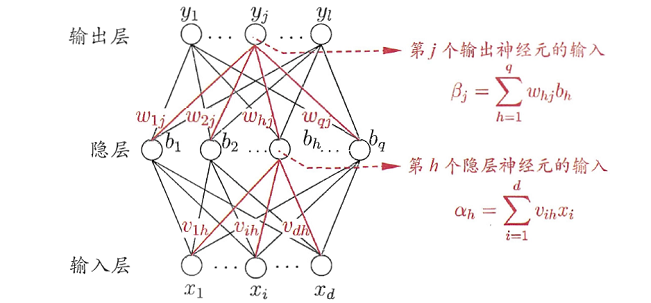
我们先来分析一个非常简单的三层神经网络:
数据集
前向过程
在输入层,假设该层节点数为d,也就是特征x的维度, 作为该层输出;在隐藏在输入层,假设该层节点数为d,也就是特征x的维度, 作为该层输出;在隐藏层中,该层节点数为q,每个节点的输入 就是上一层所有节点输出 的线性组合值,该节点的输出 是 的激活值,这里假设使用sigmoid激活函数;
在输出层,该层节点数为l,也就是输出y的维度,同理,每个节点的输入 是 的线性组合值,输出 是 的激活值,根据不同任务选择不同激活函数,比如二分类任务一般是用sigmoid激活函数把 限制到[0,1]之间。
后向过程
那么我们的目标就是最小化Loss,调整参数和
,
,使得网络尽量去拟合真实数据。如何求最小值?那当然是求导了,根据loss函数对参数求导,然后往梯度下降的方向去更新参数,可以降低loss值。梯度主宰更新,如果梯度太小,会带来梯度消失问题,导致参数更新很慢;那如果梯度很大,又会造成梯度爆炸问题。对于输出层参数
,E对
进行链式求导,也就是,E先对节点的输出
求导,再对节点的输入
求导,最后对
求导,结果为:
这里我们令 ,就可以得到参数 的更新量为:
就可以愉快地将更新 了。
隐藏层参数 ,也是链式求导,E先对该层节点的输出 求导,再对节点的输入 求导,最后对 求导,其实在前面我们已经求出了部分梯度,最后结果为:
注意到, 其实我们刚刚求过,其实就是 这货,因此我们可得:再次令
,可以得到 的更新量为: 也就可以愉快地将更新 了。
等等,事情好像并没有这么简单,我们仔细观察 ,涉及到了这些东西:
1) :这是上一层传递过来的梯度,如果上一层的梯度本来已经很小,那么在这一层进行相乘,会导致这一层的梯度也很小。所以如果网络层比较深,那么在链式求导的过程中,越是低层的网络层梯度在连乘过程中可能会变得越来越小,导致梯度消失。
2) :这是这一层的权重,这一项是造成梯度爆炸的主要原因,如果权重很大,也可能会导致相乘后的梯度也比较大。(梯度爆炸不是问题,做个梯度裁剪就行了,对梯度乘以一个缩放因子,我们主要考虑的是梯度消失问题)
3) :这是sigmoid激活函数的导数,sigmoid激活值本身已经是一个比较小的数了,这两个小于1的数相乘会变得更小,就可能会造成梯度消失。
我们直接来看sigmoid的这个图吧,只有在靠近0的区域梯度比较大(然而也不会超过0.25),在接近无穷小或者无穷大的时候梯度几乎是0了:
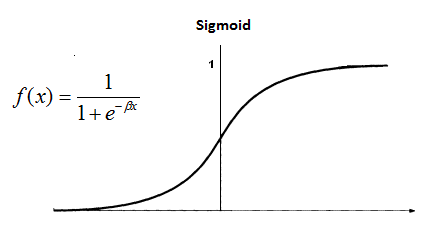
所以sigmoid是造成梯度消失的一个重要原因,激活函数其实是为了引入了非线性操作,使得神经网络可以逼近非线性函数。因此如果不是输出层必须要用sigmoid来限制输出范围,我一般是不用sigmoid的。
那么从激活函数出发,缓解梯度消失有以下方法:
1)不行就换,比如把sigmoid换成relu,在x>0的时候可以稳稳维持1的梯度。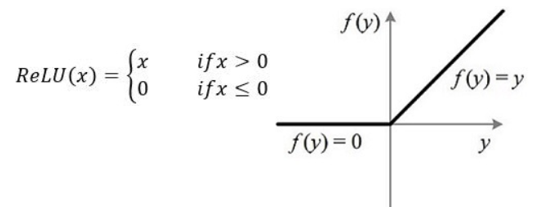
2)不想换那也行,既然我们知道sigmoid在靠近0的取值范围内梯度比较大,但我们可以把数据尽量规范化到一个比较合适的范围,也就是part III 要谈到的Normaliztion。
二、从RNN到LSTM再到GRU
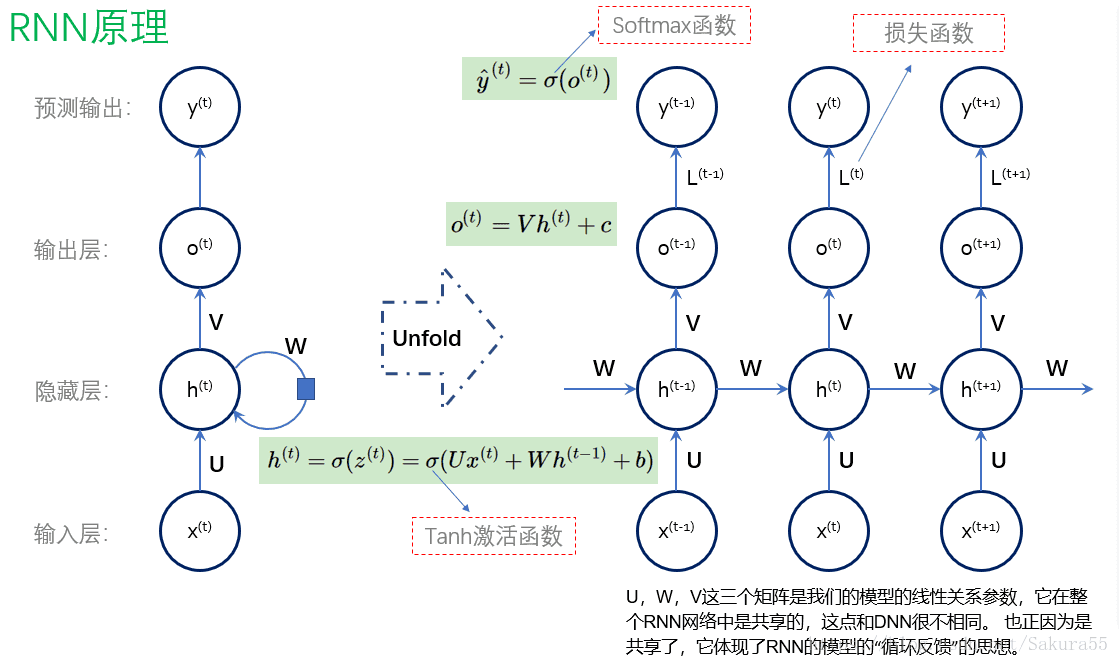
接下来我们再探讨一下RNN系列,也就是展开型的神经网络。RNN是最简单的循环神经网络,其实就是对神经网络展开k个step,所有step共享同一个神经网络模块S,我们还是直接来看图吧:
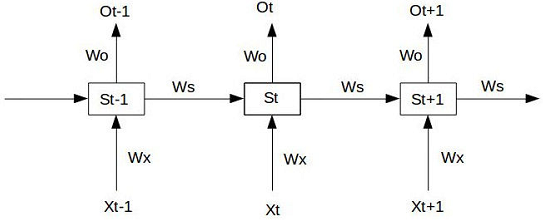
这是一个序列预测任务,可以看到在RNN中
和
这两个参数是共享的,注意噢:这里也有个共享的
,但不是包含在RNN中的,只是用于序列预测而已。
在step t下,RNN的输出向量
是:
接下来 和 进行相乘得到step t下的预测值 (加激活函数也可以)。假设step t 的正确label是 ,我们现在还是将Loss函数定义为均方误差:
也就是,每个step t 的loss是 ,
现在我们来看看怎么更新 ,可以看到在step t 下,计算 不仅涉及到了step t下的 ,也涉及到了前面step下的 ,来看这个反向传播路径图:
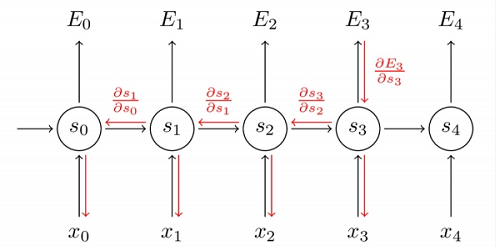
因此在step t下, 对
求导需要对前面所有step的
依次进行求导,再加起来:
注意到有一个硕大的连乘符号,事情好像又开始变得不简单起来,我们来继续求导下去,在RNN中 s的激活函数是tanh函数:
套路和前面的神经网络是一样的!这里又涉及到了激活函数的梯度,以及网络的其它权重 ,而 其实只是将sigmoid的范围从[0, 1]变到[-1, 1]而已:
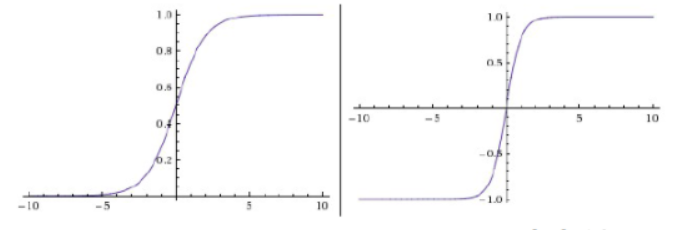 这货还是不能解决梯度消失的问题啊!另外,
又可能会造成梯度爆炸,也就是说,RNN和普通的神经网络一样存在着梯度消失和爆炸的隐患,并且RNN网络又是展开的,相当于很深层的神经网络,因此梯度还比普通的神经网络要不稳定得多。
另外,我们从矩阵的角度来看,
这货还是不能解决梯度消失的问题啊!另外,
又可能会造成梯度爆炸,也就是说,RNN和普通的神经网络一样存在着梯度消失和爆炸的隐患,并且RNN网络又是展开的,相当于很深层的神经网络,因此梯度还比普通的神经网络要不稳定得多。
另外,我们从矩阵的角度来看,
我们来看看LSTM的内部结构,包含了四个门层结构: ;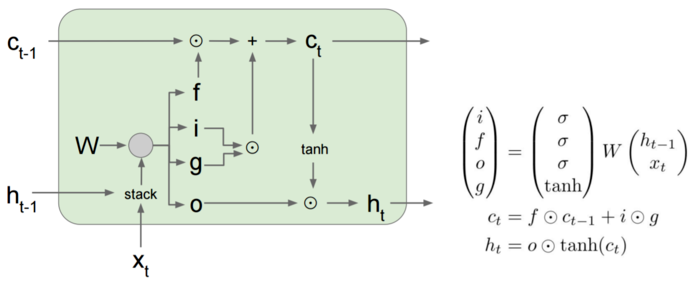
LSTM相信很多人看过这个:[译] 理解 LSTM 网络,但是我发现cs231n的公式更加简洁,把四个门层结构的权重参数合成一个W。
求导过程比较复杂,我们先看一下这一项:
和前面一样,我们来求一下 ,这里注意
和
都是
的复合函数:
而且forget gate解决了RNN中的长期依赖问题,不管网络多深,也可以记住之前的信息。
另外,LSTM可以缓解梯度消失,但是梯度爆炸并不能解决,但实际上前面也讲过,梯度爆炸不是什么大问题。
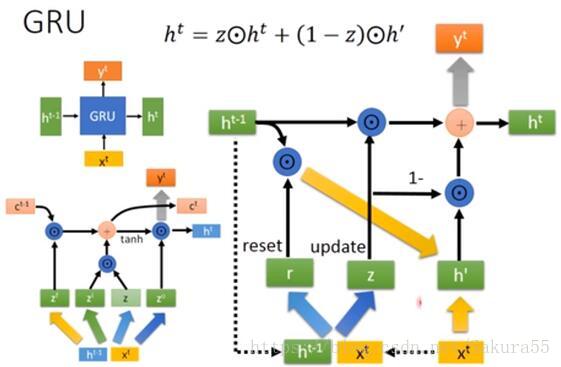
GRU
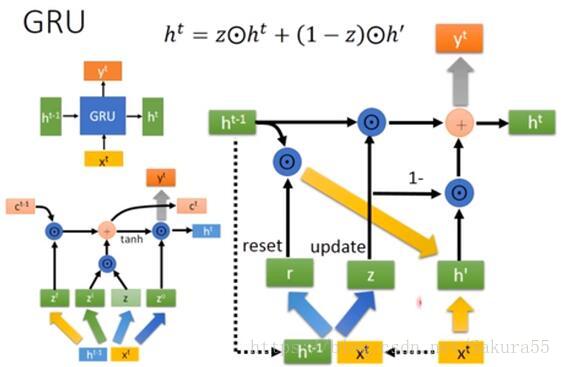
LSTM内部结构比较复杂,因此衍生了简化版GRU,把LSTM的input gate和forget gate整合成一个update gate,也是通过gate机制来控制梯度:
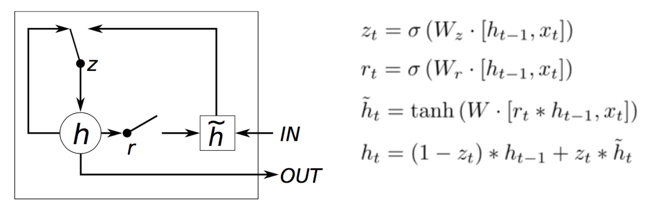
我们还是来求一下 \
那一串省略号我们还是不管,我们依然可以通过控制 来控制梯度。
所以,我们现在可以看到,LSTM系列都是通过gate机制来缓解梯度消失问题的。
三:从Batch Normalization到Group Normalization
现在我们已经知道:
1)激活函数对梯度也有很大的影响,大部分激活函数只在某个区域内梯度比较好。
2)在后向传播的时候,我们需要进行链式求导,如果网络层很深,激活函数有权重又小,会导致梯度消失;如果权重很大,又会导致梯度爆炸。
那么解决梯度消失可以从这几方面入手:
1)换激活函数;
2)调整激活函数的输入;
3)调整网络结构
事实上,我们有一个好东西可以解决梯度问题,叫做Normalization,就是从第二方面入手同时解决梯度消失和爆炸,而且也可以加快训练速度。
Batch Normalization
假设对于一个batch内某个维度的特征
BN需要将其转化成
首先对节点的线性组合值进行归一化,使其均值是0,方差是1。(也就是,对节点的输入进行归一化,而不是对输出进行归一化)
其中
是均值,
是标准差,
是用来控制分母为正。
但是数据本来不是这样子的啊!我们强行对数据进行缩放,可能是有问题的,所以BN又加了一个scale的操作,使得数据有可能会恢复回原来的样子:
加了scale可以提升模型的容纳能力。
既然是Batch归一化,那么BN就会受到batch size的影响:
1)如果size太小,算出的均值和方差就会不准确,影响归一化,导致性能下降,
2)如果太大,内存可能不够用。
Group Normalization
因此上个月提出的GN,就是为了避免batch size带来的影响。乍一看标题以为做了啥大改革,BN要退出舞台了,其实只是归一化的方向不一样,不再沿batch方向归一化,他们的不同点就在于归一化的方向不一样:
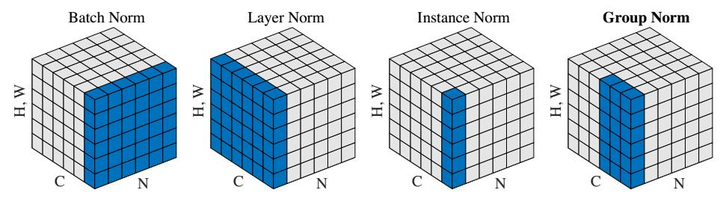
BN:批量归一化,往batch方向做归一化,归一化维度是[N,H,W]
LN:层次归一化,往channel方向做归一化,归一化维度为[C,H,W]
IN:实例归一化,只在一个channel内做归一化,归一化维度为[H,W]
GN:介于LN和IN之间,在channel方向分group来做归一化,归一化的维度为[C//G , H, W]
四、比较
除语言建模外,GRU在所有任务上都优于LSTM
●MUT1与GRU在语言建模方面的表现相匹配,在所有其他任务上均优于GRU
●允许丢失时,LSTM在PTB上的性能明显优于其他体系结构
●增加大忘记栅极偏置可大大提高LSTM性能
●LSTM的遗忘门是最重要的,而输出门相对不重要
参考文献:● RNN梯度消失和爆炸的原因
● https://zhuanlan.zhihu.com/p/36101196?utm_source=qq&utm_medium=social&utm_oi=761548970097917952