引入
所谓序列学习,就是输出不单单取决于当前的输入,而且与历史输入有关。序列学习的模型有:隐马尔科夫模型(HMM)、结构化感知器、以及条件随机场。当然以上这些模型都是机器学习的方法,若应用神经网络,即深度学习(实际上属于机器学习之一)的方法,于是则诞生了 RNN (Recurrent Nerual Network)。
发展史
RNN 的发展与序列学习形影不离。序列学习其实是分类问题的一种,在 NLP 领域也叫结构化预测问题。序列学习也属于强化学习的范畴。然而这些定义总没有严格的标准。因此,这里给出笔者个人的定义:所谓序列学习,输入序列变量,该序列蕴含着某种顺序,通过这个序列变量输出标签。
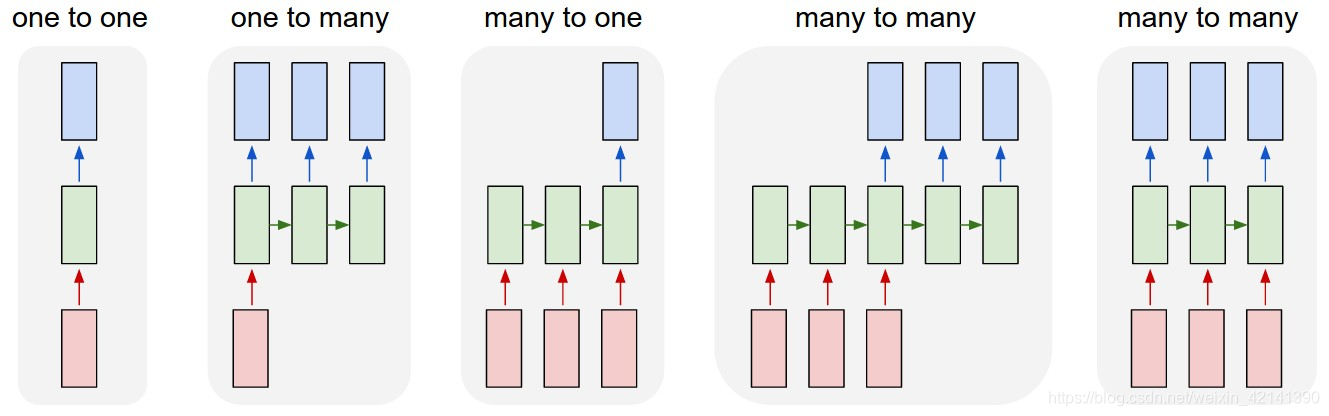
如图所示,序列学习包括如下几种状态。一是 one2one,这种类似于分类问题了,是序列个数等于 1 的特殊情况。第二种也是输入一个序列个数为 1 的“序列”,输出其当前、未来对应的标签状态。第三种,通过序列,输出最后的标签。以此类推。
传统的实现序列学习的方法有 HMM,之后又引申出了条件随机产。之后,神经网络的崛起又诞生了结构感知器。再然后,就演变成了 RNN 网络了。
实际上 RNN 并不是近代才出现的。实际上,但神经网络出现之初,就有很多 RNN 的影子。实际上,现在的很多中文文献中,常称 RNN 网络为序列神经网络。但在早期的时候,大约是 1980 年左右,其被称为反馈神经网络。比如 Elman 神经网络、NAXR 神经网络就是其一。即使到现在,还有人在使用这两种反馈神经网络。比如你下载一个2010版本的 Matlab,其 cntool 工具箱就有其实现。
为什么称反馈神经网络为 RNN 的前身呢?以 Elman 神经网络为例,其包括输入层、隐藏层、承接层和输出层,像极了今天的 RNN。其中其承接层用于延迟和存储隐藏层的输出,并自联到隐藏层的输入中。这种自联方式对历史状态的数据都具有敏感性,内部反馈网络的加入增加了网络本身的动态处理能力,从而达到动态建模的效果。
之后,随着神经网络的第一次没落,反馈神经网络也因此销声匿迹。随后,大数据时代的到来,使得反馈神经网络再一次粉墨登场,以 RNN 的新形态屹立于深度学习之林。当然,反馈神经网络与 RNN 是有区别的。比如,反馈神经网络要求定义反馈的步长。换句话说,其当前输出的,与当前输入,和有限步长内的输入有关。而 RNN 则不然,其不需要定义反馈步长。也因此,RNN 的输出,与之前的所有输入均有关。而这种有关的程度,取决与神经节点的权重。更切确的说,取决于以往的输入数据。
卷积神经网络经常用在计算机视觉领域,其接受一个矩阵(或者说图像),输出一个概率序列。内部经过一系列的卷积,因此其神经元的参数非常之多。即便如此,大数据的福音使得 CNN 不再是土豪们的玩具,并且开始了其走出象牙塔,走向工业应用。
然而,对于 RNN,人们总是有很多腹诽。很多智者们不加思考地指出,用训练一个 RNN 是非常苦难、耗时的。其实不然,在很多实践的验证下,这种无稽之谈不攻自破。于 2015 年左右, RNN 被许多专家们看上,并迅速发展起来,期间诞生了许多精通与 RNN 原理的高手,以及许多新型的 RNN 网络。
目前 RNN 通常用于物体捕捉,图像识别和自然语言处理中。题外话,在 NLP 领域中,比如汉语的分词、词性标注和语法分析中,都是用序列学习的方法实现的。通常将其视为序列标注问题。然而,它们并非使用 RNN 实现,而是条件随机场。那么 RNN 用在哪里呢?它用在逼格更高的地方,比如根据上下文,预测接下来的单词。或根据上下文,直接自动生成接下来的内容。很多高手们使用了 RNN,甚至可以根据当前的代码,自动生成接下来的代码,这不得不说是程序猿的福音与噩梦。
LSTMs 是什么
就如 Fast-RCNN 和 YOLO 之于 CNN, LSTMs 网络与 RNN 两者在概念上属于从属关系。LSTMs的全称为 Long Short Term Memory,即长期-短期记忆。
短期记忆
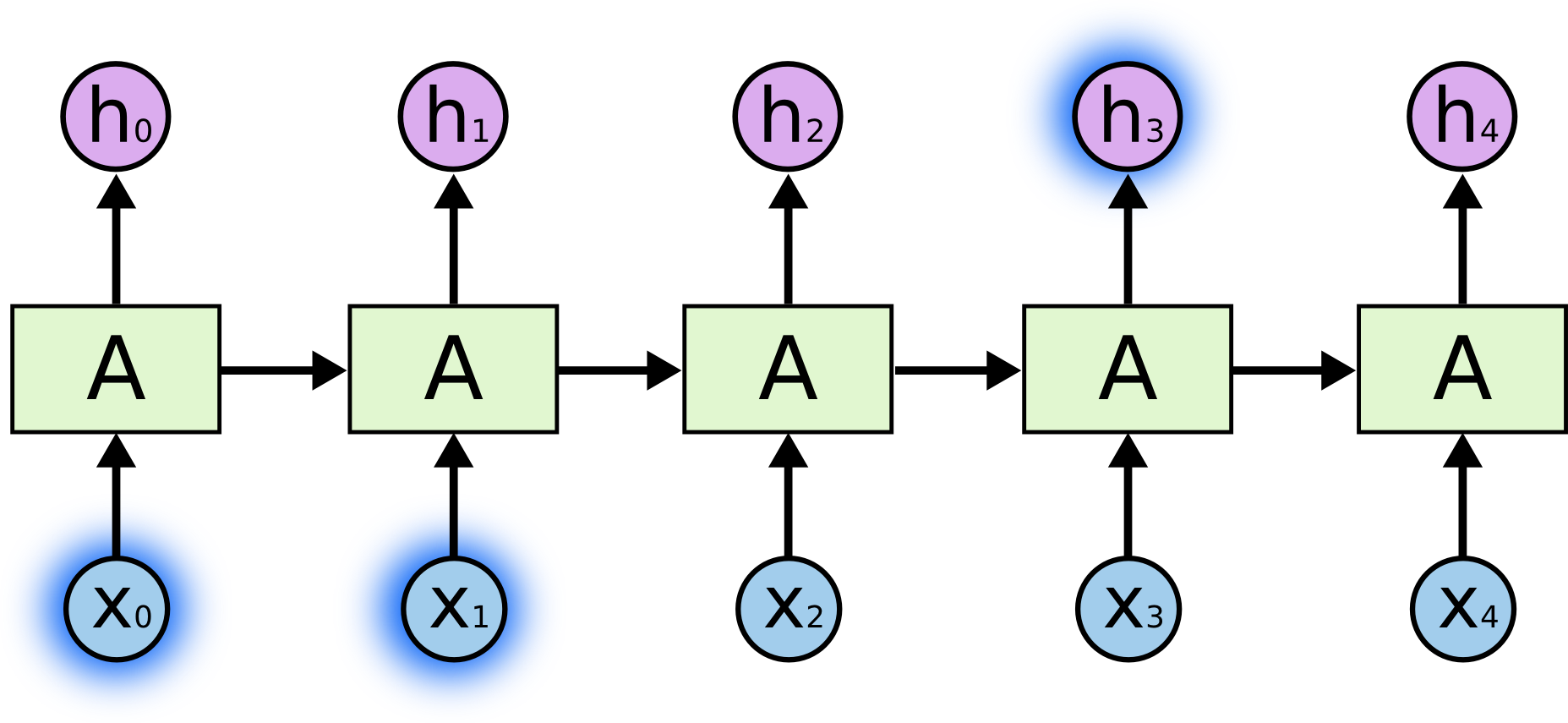
比如句子鸟在天上飞,如果要根据序列鸟在天上,预测飞,实际上是很容易的。只要根据鸟或者天上这个单词就可以预测出飞了。也许有点误差,但八九不离十了。如下图所示:
长期记忆
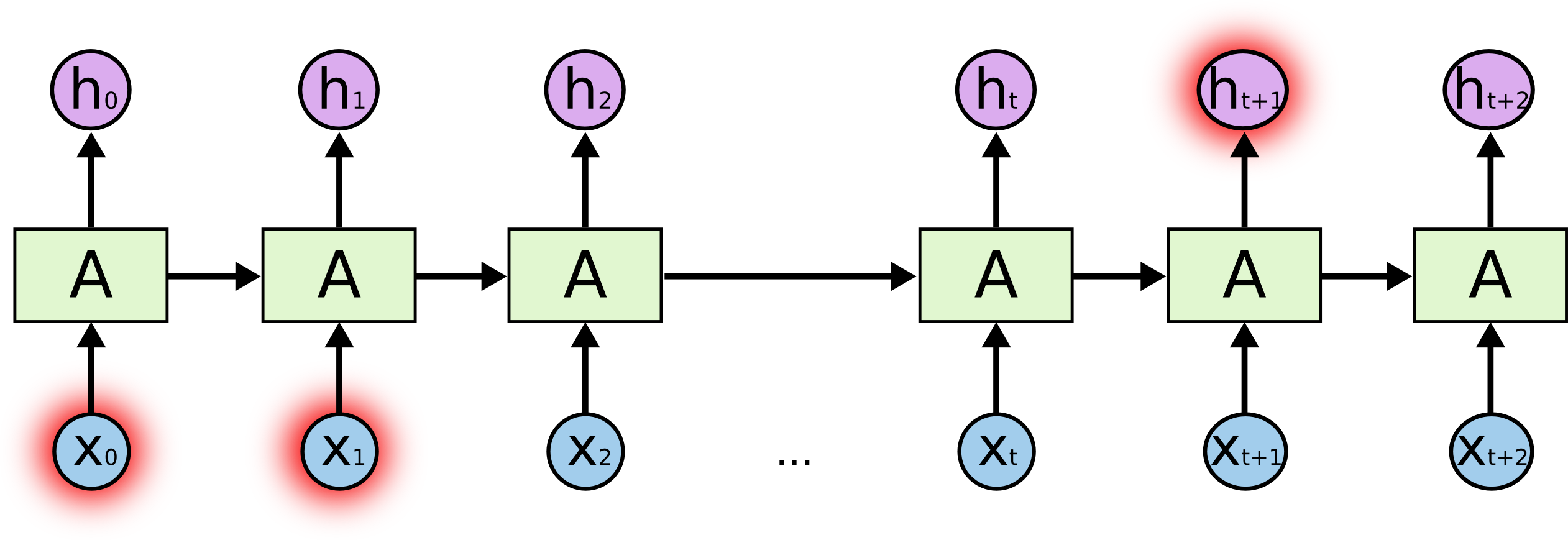
比如句子我在中国长大,…,我汉语很六,中间隔了很多条句子。但是,汉语很六只能通过在中国长大第一条句子中,才有可能推断出来。也就是说,当前的输出结果,与较早之前的记忆有关,如图所示;
RNN 的局限
然而,传统的 RNN 网络,却不能很好的解决长期记忆的问题。其原因较为复杂,大家可以参阅文献link。当然这里我也会简单的谈一下。
首先,RNN 的学习算法与 BP 神经网络一样。也是基于代价函数求梯度的反向传播算法。但与 BP 不同的是,其在计算梯度的时候,用了时间信息。具体做法是,在求一个节点的梯度时,存储该时刻节点的激活函数的形式。然后,根据以往的激活函数和现在的激活函数,来求取当前的梯度。但不幸的地方就在于,存储能力是有限的,因而限制了其处理长期记忆的能力。另外,即便能够完全存储。在很多实验中也表明:虽然 RNN 在处理长期记忆问题上,比反馈神经网络要好得多。但是,其训练始终无法有效收敛。换句话说,其收敛是局部最优的。往往这种局部最优,导致其处理短期记忆很强,长期记忆很弱。
然而,LSTM 神经网络并没有上述缺点。也就是说,它能够处理好 both 长期记忆 and 短期记忆问题~
LSTM 网络详解
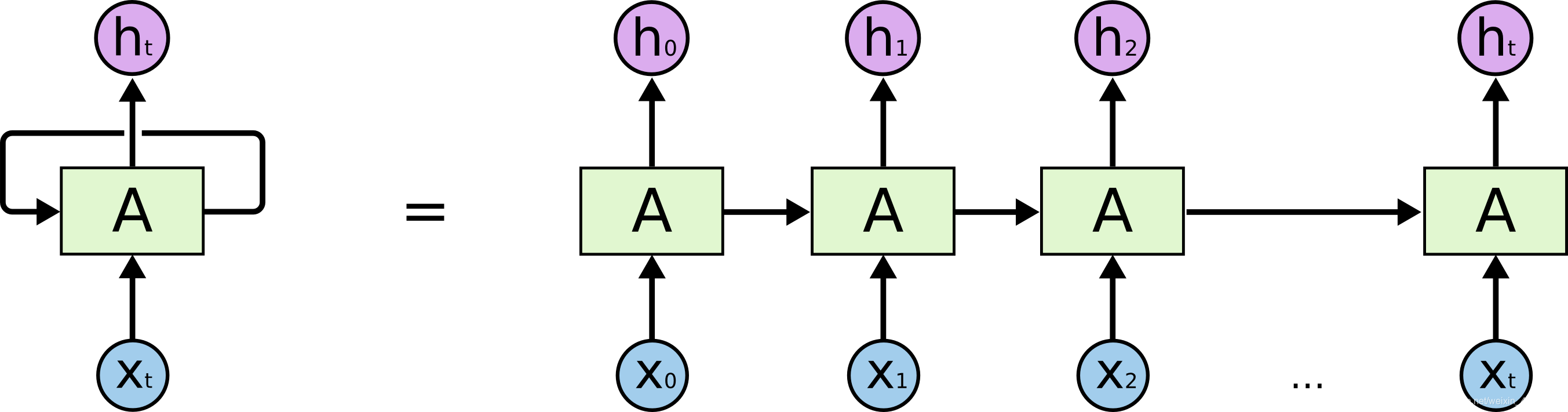
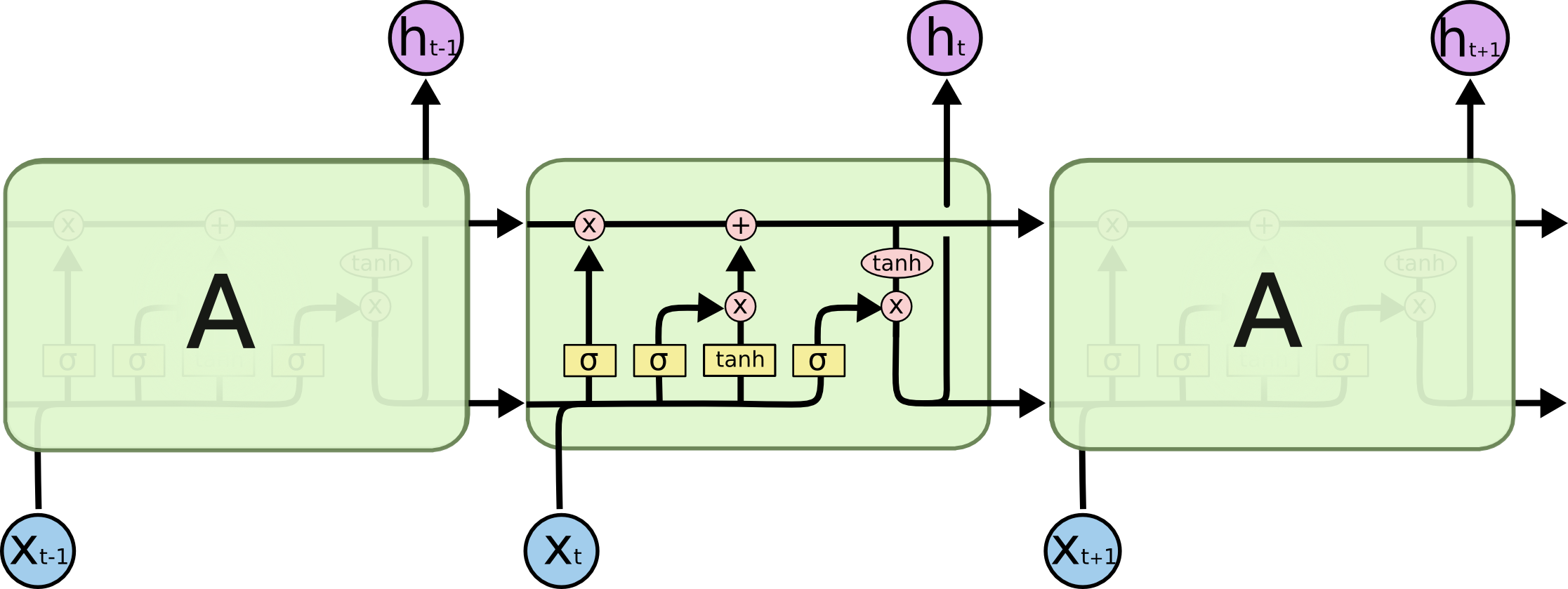
如下图所示,一个 RNN 网络可以表示如下

将循环展开,可得:
下面,我们将讨论 LSTM 网络的详细介绍,包括其定义和扩展。
符号约定

方框表示神经网络层(自设),红色圆圈表示向量运算,里面是个乘号,就表示点积。黑色箭头表示向量,两个黑色箭头融合在一起,表示将向量进行拼接。
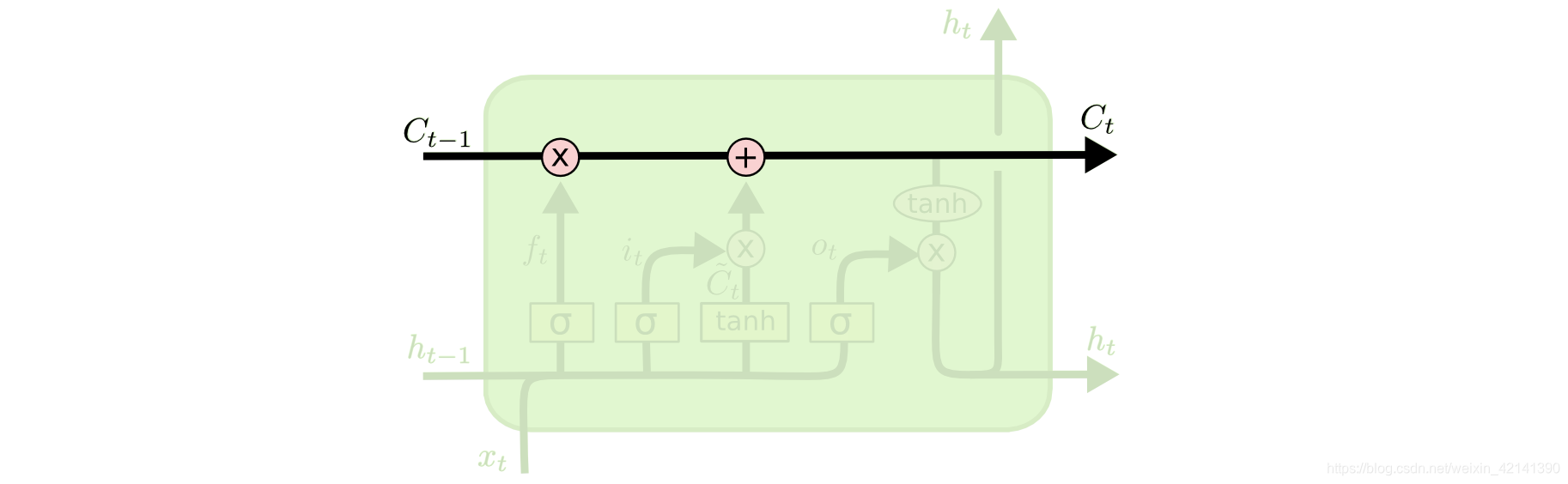
上图中
是一条胞状态,就像工厂上的传送带一样,
经过工人们的处理,最后变成
。
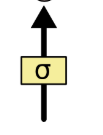
上图表示阀门,其中
是 sigmoid 函数。相信大家对 sigmoid 函数都很熟悉,其取值为
,具体长什么样,就不在介绍了。
LSTM 网络分解
一个典型的 LSTM 网络如下:
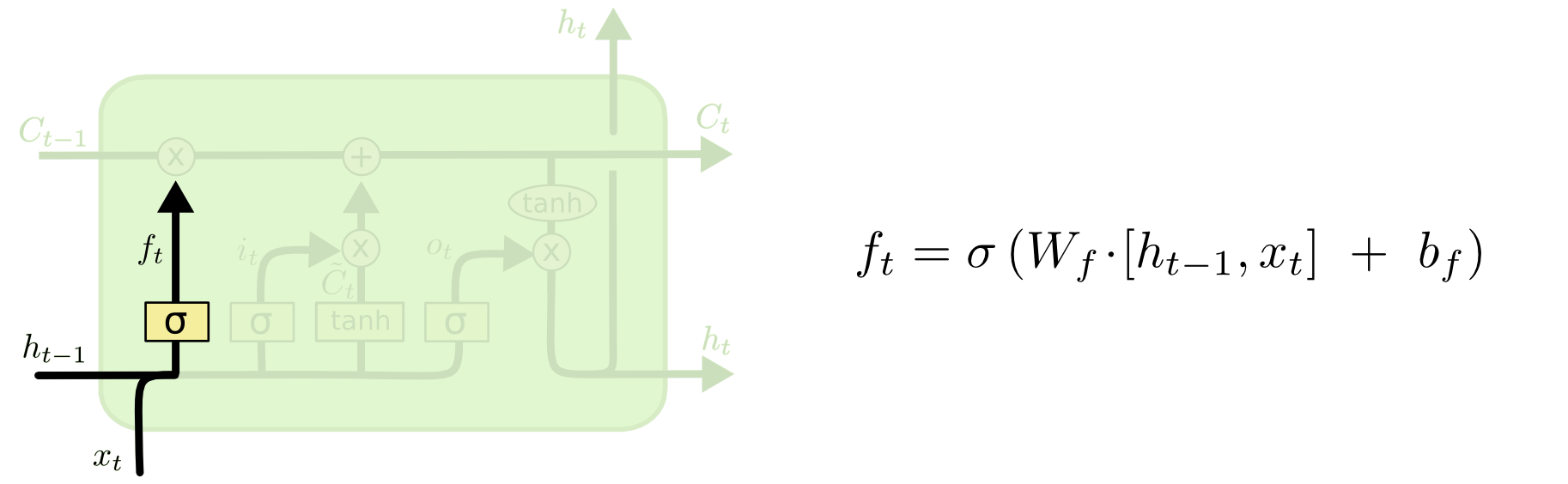
当输入
和
传送而入时,首先要经过过滤。即用 sigmoid 函数,将两者的点击进行过滤,然后传送到
的传送带中。这实际上模拟健忘过程。比如之前的主语为 he 时,若再输入主语 she,则需要将之前的 he 更新掉。
之后,为了模拟 she 替换掉 he 的过程,应该加入如下的函数。此时
和
用一个 tanh 和 sigmoid 过滤 输出
和
。
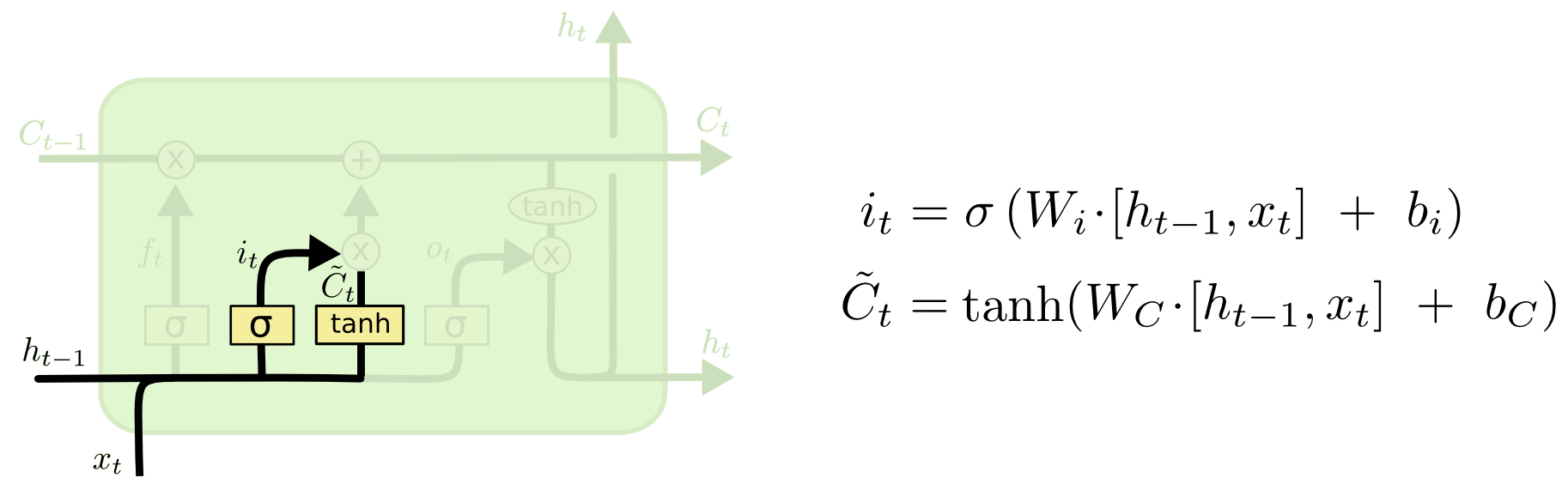
最后,将上述的结果
传送到“传送带”中了,如下:
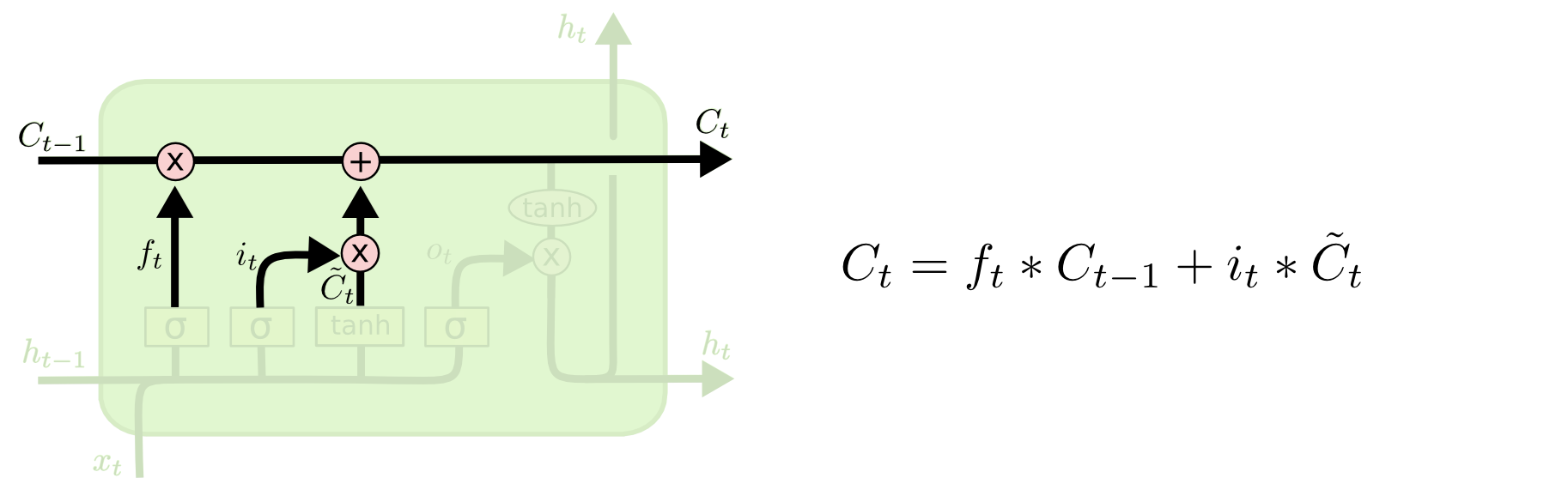
之后,为了模拟根据历史状态,以及当前的输入输出
的过程,还需要以下处理:
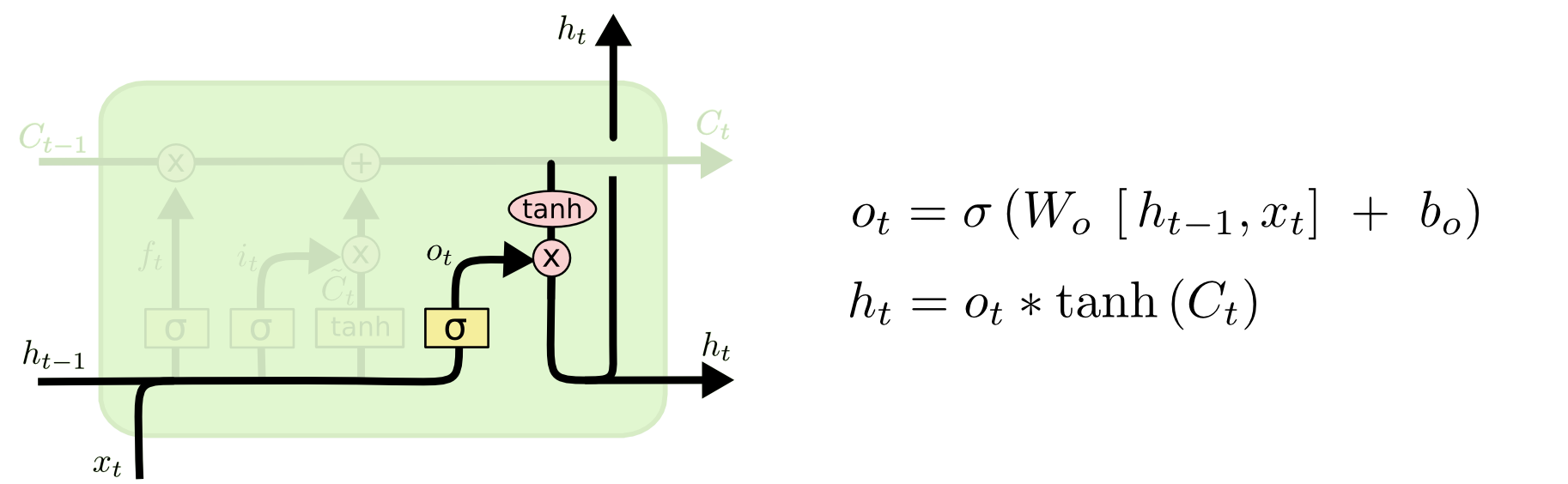
其中
通过一个 sigmoid 函数过滤,而胞状态
通过 tanh 函数过滤后,两者的点击加上偏移项输出
。
实际上,通过存储胞状态、 就可以存取历史状态了。这个历史状态的长久与否,取决于神经元的参数。当然,如果 A (记住,它是一个层)中包含多个神经元节点,那么其 和胞状态的个数还是不少的。
其他 LSTM 网络
以上的 LSTM 网络是比较典型的,LSTM网络还有如下形式:
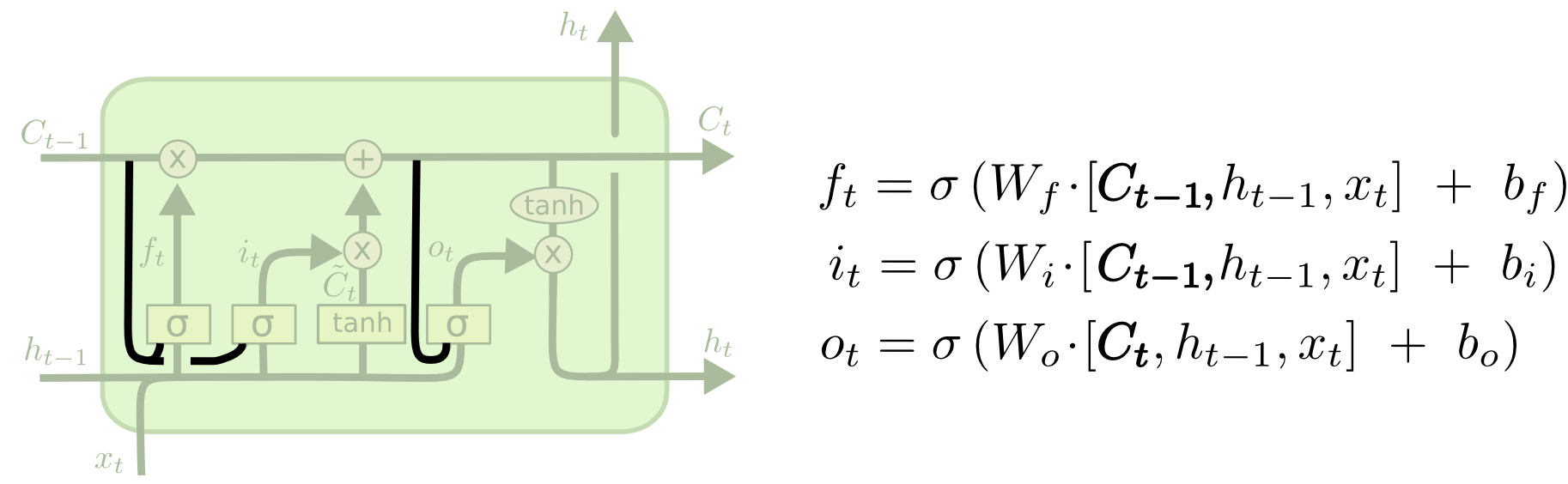
上述模型与经典模型的差别在于,其胞状态和以往的胞状态也有关系。也就是说,其长期的联系比较强烈。另一个LSTM 模型如下。

这种模型与经典模型比较相似,不过在
的更新有点差别,详见上面的公式。第三种与第一种类似,也是倾向于长期联系的,如下所示:

整体模型
我们只是讨论了隐藏层而已,换句话说,最终的输出 y 与隐藏层的输出 有关。因为隐藏层被 BP 神经网络用了,因此,我们姑且层为 LSTM 层吧。于是整个 RNN 的神经网络应该是这样
其中,LSTM 层的每个输入 为一个向量,输出亦是 亦是一个向量。通过存储 ,并根据 LSTM 层的参数,来映射历史输入对当前输出的影响。之后,输出层根据 输出最终的标签。当然,输出层的传递函数可以自定义,用 sigmoid 或者 RELU 都可以。