一、RNN
RNN(Recurrent Neural Networks,循环神经网络)不仅会学习当前时刻的信息,也会依赖之前的序列信息,允许信息持久化。由于其特殊的网络模型结构解决了信息保存的问题。所以RNN对处理时间序列和语言文本序列问题有独特的优势。
标准的RNN模型如下图所示:

由图可以看到RNN引入了隐状态h的概念,h可以对序列形式的数据提取特征,接着再转换为输出。ht = tanh(ht-1, xt)有前一个神经元的输出和当前时刻的输入共同决定。推导可见链接
这里我们不禁要问,为什么RNN选用tanh函数作为激活函数,而不选用ReLu或sigmod函数呢?这里首先我们需要知道tanh函数是将值转换为(-1, 1)之间,具体请看我的另一片博客。总而言之有两个原因:
(1)在RNN中直接把激活函数换成ReLU会导致非常大的输出值,加大计算量。
(2)激活函数ReLu不能解决梯度在长程上传递的问题。
关于上述为什么RNN选用tanh的问题,还请参考知乎回答。
RNN存在的问题:
a、梯度消失 :更新模型参数的方法是反向求导,越往前梯度越小。而激活函数是 sigmoid 和 tanh 的时候,这两个函数的导数又是在两端都是无限趋近于0的,会使得之前的梯度也朝向0,最终的结果是到达一定”深度“后,梯度就对模型的更新没有任何贡献。
b、梯度爆炸:梯度爆炸就是由于初始化权值过大,反向传播时对激活函数进行求导,如果此部分大于1,那么层数增多的时候,最终的求出的梯度更新将以指数形式增加,即发生梯度爆炸的现象。
c、长期依赖问题:相关信息和当前预测位置之间的间隔不断增大时,RNN 会丧失学习到连接如此远的信息的能力。
针对RNN的上述问题,相关学者设计了LSTM,以避免长期依赖问题。
RNN用于文本多分类模型:

二、LSTM
LSTM 具有与RNN同样的结构,但是重复的模块拥有一个不同的结构。不同于单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。
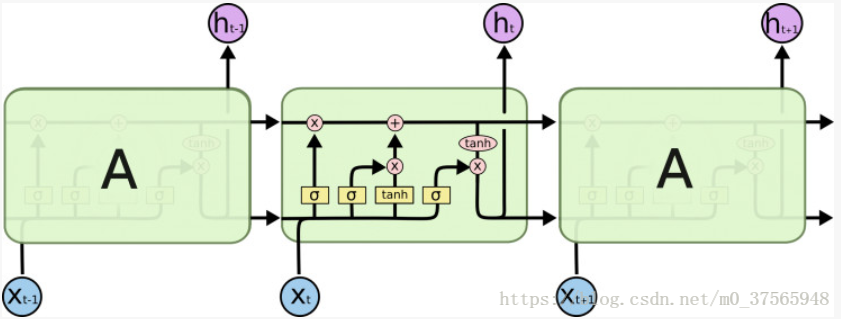
上图为LSTM的交互模块,其核心在于添加了cell状态,也就是图中最上面的一条线。cell就像传送带沿着整条链传送,记录历史的信息。LSTM通过三个名字为门的结构控制cell状态。
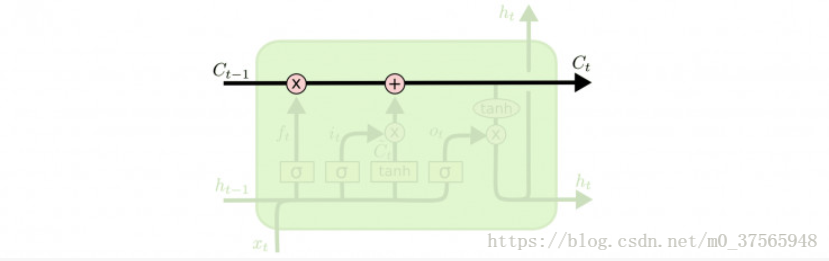
如上图所示,ft(遗忘门)、it(输入门)、ot (输出门)三个门来控制cell的状态。
(1)ft(遗忘门):这一步决定从cell中抛弃哪些信息,因为cell中不可能保存所有历史数据,这样不仅会造成运算数据量庞大,还会使传输的数据携带一些噪音,不利于最终结果的运算。
(2)it(输入门):这一步与输入相连,决定哪些输入信息会存储到cell中,即向cell中存储信息。
(3)ot (输出门):该步骤的输出分为两部分,一部分流入写一个计算单元,另一部分作为该xi的的特征表示输出。
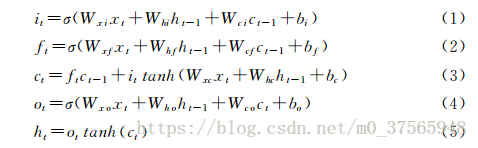
上图中的计算公式为LSTM隐藏层的输出表示h的具体计算过程。
关于LSTM的输入,详情参考如下链接的“隔壁小王”的回答。