假设我们试着去预测“I grew up in France… I speak fluent French”最后的词。当前的信息建议下一个词可能是一种语言的名字,但是如果我们需要弄清楚是什么语言,我们是需要先前提到的离当前位置很远的 France 的上下文的。这说明相关信息和当前预测位置之间的间隔就肯定变得相当的大。
不幸的是,在这个间隔不断增大时,RNN 会丧失学习到连接如此远的信息的能力。
LSTM
Long Short-Term Memory—— 一般就叫做 LSTM,是一种 RNN特殊的类型,可以学习长期依赖信息。
LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力!
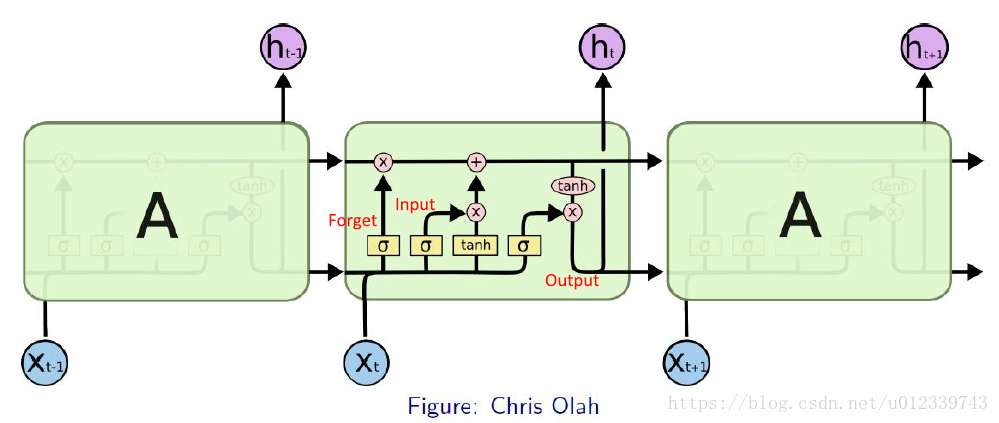
- 忘记门,在我们 LSTM 中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过一个称为忘记门层完成。(eg. 一句话中,当我们看到
新的主语,我们希望忘记旧的主语。) - 输入门,确定什么样的新信息被存放在细胞状态中。
- 输出门,实际去执行——丢弃掉我们确定需要丢弃的信息,更新需要更新的信息。
GRU
Gated Recurrent Unit——一般叫做GRU,作为LSTM的一种变体,通过分析LSTM架构中哪些部分是真正需要的,进行了改进,将忘记门和输入门合成了一个单一的更新门。同样还混合了细胞状态和隐藏状态,加诸其他一些改动。最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。
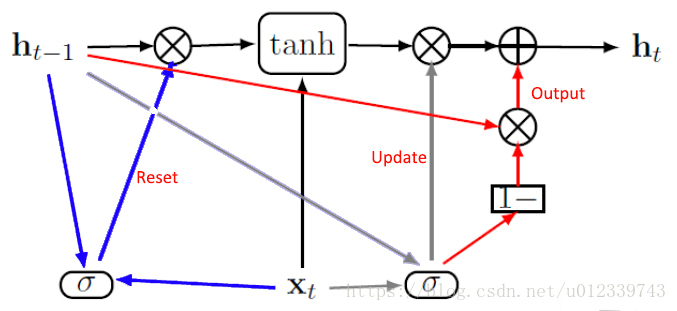
- 复位门,控制当前状态中哪些部分用于计算下一个目标状态。
- 更新门,在极端情况下,可以选择全部复制或者完全替换。
复位和更新门能独立地“忽略”状态向量的一部分。
References:
[1] [译] 理解 LSTM 网络
[2] 王亮老师《深度学习》讲义
©qingdujun
2018-6-9 于 北京 怀柔