第一篇blog
专业两年了,很早就有写blog的打算,迟迟没有动笔。第一篇就先当我的学习笔记了,另外我会把我觉得困难的地方或者参数都解释出来。方便其他人学习。
MNIST数据集
mnist数据集是一个经常被当作教程的机器学习数据集,而在本例中我们使用的简单来说就是0到9的手写体数字图片,每张图片由一个数字构成,分辨率是28pixel×28pixel。这会在构建神经网络的时候用到。
如图:

图片来自https://img-blog.csdnimg.cn/20190701105657950.jpeg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk
RNN+LSTM神经网络
如果真的要明白RNN和LSTM的内核需要一定的基础,而且对数学和计算机思维都需要有一定的训练。所以我下面只会简单的介绍一下不会深入解释。后续的blog会有专门进行RNN和LSTM或者其他网络模型的探讨。
RNN:
循环神经网络(Recurrent Neural Network,RNN)是一类专门用于处理时序数据样本的神经网络,它的每一层不仅输出给下一层,同时还输出一个隐状态,给当前层在处理下一个样本时使用。就像卷积神经网络可以很容易地扩展到具有很大宽度和高度的图像,而且一些卷积神经网络还可以处理不同尺寸的图像,循环神经网络可以扩展到更长的序列数据,而且大多数的循环神经网络可以处理序列长度不同的数据(for 循环,变量长度可变)。它可以看作是带自循环反馈的全连接神经网络。
而简单来讲相比于CNN,RNN拥有了保存上一个输入得到的状态的能力,进而可以将上一个得到的结论加入下一个输入中,面对时序数据处理RNN就更能体现它的优势了。

LSTM:
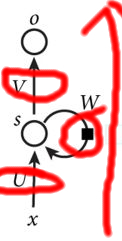
简单来说,如果我们说RNN有了循环的功能但是我们想,一个weight即使它是0.9,那么0.9的高幂次也是一个几乎接近于0的数字;而weight=1.1大于1,此时weight的高幂次也会非常大,这在神经网络中也是有问题的。前者我们称为梯度消失,而后者我们叫做梯度爆炸。那该如何解决呢?LSTM就成为了很好的解决方案,如下图所示,LSTM与RNN相比结构上又多了三个红圈也就是三个控制器,而在右边的红色箭头我愿意把它叫做主线。三个控制器会将有影响力的状态数据(m_state)这里称为分支状态,存在红色箭头所示的主线状态中(c_state),这样的话我们可以理解为LSTM是有记忆功能的。这也就可以理解什么是long short-term memory.
代码
1.导入
我们使用tensorflow,当然使用别的学习库也可以,但要选择主流的。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
2.定义学习中的必要参数
tf.set_random_seed(1)#目的是希望得到不同的测试的结果
#导入数据
minist=input_data.read_data_sets('MNIST_data',one_hot=True)
##one_hot表示用非0即1的数值来表示图片
#定义参数hyperparameters
lr=0.001
#learn rate 不一定要和我设置的一样,其决定着目标函数能否收敛到局部最小值以及何时收敛到最小值。
#合适的学习率能够使目标函数在合适的时间内收敛到局部最小值。
training_iters=100000#训练次数
batch_size=128
#batch_size也是可以自定义的,可以简单的理解为每次取多少张图片
n_inputs=28
n_steps=28
#28×28 不知道你还记得吗 就是我们所说过得,图片的分辨率 单位是pixel
n_hidden_units=128
#我们设置有128个单元 ,你也可以进行自定义
n_outputs=10
#这是分类训练,最后输出0-9是个类。
3,定义数据流图
#define date flow graph
#placeholder是占位符,用来作为数据流图的输入
#shape是张量的维度,在tensorflow中shape的变化和选取非常重要,否则会报错
x=tf.placeholder(tf.float32,shape=[None,n_steps,n_inputs])#输入图片
y=tf.placeholder(tf.float32,shape=[None,n_outputs])
#权重
weights={
'in':tf.Variable(tf.random_normal([n_inputs,n_hidden_units])),
'out':tf.Variable(tf.random_normal([n_hidden_units,n_outputs]))
}
#矩阵偏执,大家有问题的可以先去了解linear regression然后更好理解什么是bias
biases={
'in':tf.Variable(tf.constant(0.1,shape=[n_hidden_units,])),
'out':tf.Variable(tf.constant(0.1,shape=[n_outputs,]))
}
4.定义RNN网络
def RNN(X,W,B):
##hidden layer for input
X=tf.reshape(X,[-1,n_inputs])
X_in=tf.matmul(X,W['in'])+B['in']
X_in=tf.reshape(X_in,[-1,n_steps,n_hidden_units])
#################################################
##cell
if int((tf.__version__).split('.')[1])<12 and int((tf.__version__).split('.')[0])<1:
cell=tf.nn.rnn.cell.BasicLSTMCell(n_hidden_units,forget_bias=1.0,state_is_tuple=True)
else:
cell=tf.contrib.rnn.BasicLSTMCell(n_hidden_units)
init_state=cell.zero_state(batch_size,dtype=tf.float32)
#################################################
##hidden layer for output
outputs,final_state = tf.nn.dynamic_rnn(cell, X_in, initial_state=init_state, time_major=False)
if int((tf.__version__).split('.')[1])<12 and int((tf.__version__).split('.')[0])<1:
results0=tf.unpack(tf.transpose(outputs,[1,0,2]))
else:
results0=tf.unstack(tf.transpose(outputs,[1,0,2]))
results=tf.matmul(results0[-1],W['out'])+B['out']
return results
5.定义loss函数和训练参数
pred=RNN(x,weights,biases)
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred,labels=y))#成本函数,我们训练的过程就是最小化loss/cost function的过程
train_op=tf.train.AdamOptimizer(lr).minimize(loss)
#这次我选择了adam优化器,其实有七种,大家或者自己取搜索,
#用别的优化器也不是不可以,可以简单的理解为梯度下降算法的一种。比普通的GDO更快。
correct_pred=tf.equal(tf.argmax(pred,1),tf.argmax(y,1))
accuracy=tf.reduce_mean(tf.cast(correct_pred,dtype=tf.float32))#得到准确率
6.开始训练同时输出正确率
with tf.Session() as sess:#定义会话,tensorflow中需要Session才能运行
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
step = 0
while step * batch_size < training_iters:
batch_xs, batch_ys = minist.train.next_batch(batch_size)
batch_xs = batch_xs.reshape([batch_size, n_steps, n_inputs])
sess.run([train_op], feed_dict={
x: batch_xs,
y: batch_ys,
})
if step % 50 == 0:#每隔一定布长输出一次正确率,方便我们进行观察训练情况。
#当然也可以使用tensorboard在这里我不进行演示,大家可以在我将有关tensorboard时再进行尝试。
print(sess.run(accuracy, feed_dict={
x: batch_xs,
y: batch_ys,
}))
step += 1
之后进行运行该就可以啦,我测试的正确率最高达到99,但是这并不稳定,平均在95-96之间,读者的结构和我应该会有偏差,可以修改一些参数再进行测试观察对网络的影响。
有任何错误欢迎大家指正,一起交流,一起进步。
wechat:final_say

{kind=link}