这篇论文主要创新在代价聚集步骤,传统的聚集一般是在局部区域,这样结果也只是局部最优。但是这篇论文提出了非局部代价聚集的方法,用一颗最小生成树(MST)将整个图像联系起来,它以全图的像素作为节点,构建过程中不断删除权值较大的边,边就是相邻像素间的最短距离(即两个节点间相似性最小,本篇文章的相邻像素点指的是4邻域,我认为可以用8邻域来尝试)。然后采用kruskal(克鲁斯卡尔)算法或prim(普里姆)算法进行计算,这样便得到了全图像素之间的关系。然后基于这层关系,构建代价聚合其中树的节点就是图像像素点,这样每个像素点作为根节点的时候都能接受来自整个图像其他像素点的支持,就只是权重的大小随距离远近变得不同而已,但至少不是局限在一个区域或者窗口里,这就是本文的创新点。但是基于每个像素点作为根节点循环,计算复杂度就比较高,作者又提出了两次遍历MST,第一次是从叶节点向根节点聚集,更新每个根节点的代价聚集值(即图中的V4节点),第二次是从根节点向叶节点聚集,更新每个叶节点的代价聚集值(图中的V3节点)。计算第二次的聚集值时,就不需要再一次以这个点为根节点,因为第一次聚集的值可以放在第二次用,只不过做个减法就好,这样省去了复杂并且不断重复的死板运算。
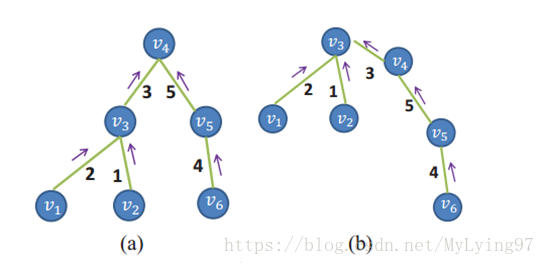
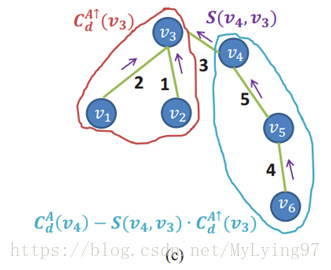
我把论文中一般公式具体化:
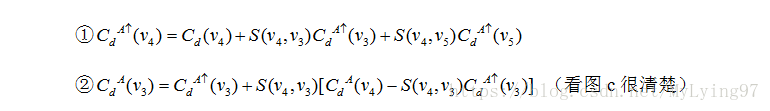
在视差精化步骤,基于上述非局部代价聚集方法,先分别得到左右两个图像的视 差图,然后进行左右一致性检测,得到稳定点和不稳定点,稳定点就可以通过检测,同时直接在左视差图上定义新的代价值,再同样利用原图所得的MST,对所有像素点重新进行代价聚合,最后利用WTA算法更新视差。其余不稳定点代价值为0。
本文的优点在于非局部的最小生成树,而且计算复杂度低,准确度高。别说,代码是真的速度快,运行完不到1s,实时性很强啊,这个非局部真不是开玩笑的。
我认为不足之处有几个(也只是我的想法):
(1)非局部MST用到了整个图像,相当于每个像素都和其他所有像素有权值联系,但是实际上距离得远的像素点之间说不定就没有相关性,这样做反而觉得有点多余,所以我认为可以对图像进行分割操作,在每个分割块内做MST,但是这个方法可能复杂度比较高,但是至少可以把目标和背景分开再进行操作,应该可以更准确。
(2)这种方法在高纹理区域效果不是很好(主要由于噪声而且会导致左右视差图不连续),所以可以结合高斯滤波的方法,而且这种方法来自周围的支持像素点相对较少,这一点对高纹理区域来说影响也很大,所以是不是可以在高纹理区域进行一些处理。
(3)最小生成树的冗余性,树连接全局,同时也是它的局限性。
int qx_tree_filter::filter(double*cost,double*cost_backup,int nr_plane)
{
memcpy(cost_backup,cost,sizeof(double)*m_h*m_w*nr_plane);
int*node_id=m_node_id;
int*node_idt=&(node_id[m_nr_pixel-1]);
for(int i=0;i<m_nr_pixel;i++)
{
int id=*node_idt--;
int id_=id*nr_plane;
int nr_child=m_mst_nr_child[id];
if(nr_child>0)
{
double*value_sum=&(cost_backup[id_]);
for(int j=0;j<nr_child;j++)
{
int id_child=m_mst_children[id][j];
int id_child_=id_child*nr_plane;
double weight=m_table[m_mst_weight[id_child]];
//value_sum+=m_mst_value_sum_aggregated_from_child_to_parent[id_child]*weight;
double*value_child=&(cost_backup[id_child_]);
for(int k=0;k<nr_plane;k++)
{
value_sum[k]+=(*value_child++)*weight;
}
}
}
}
int*node_id0=node_id;
int tree_parent=*node_id0++;
int tree_parent_=tree_parent*nr_plane;
memcpy(&(cost[tree_parent_]),&(cost_backup[tree_parent_]),sizeof(double)*nr_plane);
for(int i=1;i<m_nr_pixel;i++)//K_00=f(0,00)[K_0-f(0,00)J_00]+J_00, K_00: new value, J_00: old value, K_0: new value of K_00's parent
{
int id=*node_id0++;
int id_=id*nr_plane;
int parent=m_mst_parent[id];
int parent_=parent*nr_plane;
double*value_parent=&(cost[parent_]);//K_0
double*value_current=&(cost_backup[id_]);//J_00
double*value_final=&(cost[id_]);
double weight=m_table[m_mst_weight[id]];//f(0,00)
for(int k=0;k<nr_plane;k++)
{
double vc=*value_current++;
*value_final++=weight*((*value_parent++)-weight*vc)+vc;
}
//printf("Final: [id-value-weight]: [%d - %3.3f - %3.3f]\n",id,m_mst_[id].value_sum_aggregated_from_parent_to_child,m_mst_[id].weight_sum_aggregated_from_parent_to_child);
}
return(0);
}
这一部分代码是树滤波的核心部分,是代价聚集的两条路径,自叶节点到根节点,根节点到叶节点,其中参数较多,研究的时候费了不少功夫。
相应的效果图:




用相应的测评代码得到的误匹配率,视差图可见比较平滑,误匹配率也较低,效果很好。
这篇论文相应代码匹配代价函数结合了颜色和梯度信息,代码比较容易看懂,视差精化部分,左右一致性检测,给不稳定点赋予0的代价值,然后重新更新,更新的过程是从不稳定点到稳定点进行的。
相应的代码已经调通并且仔细研究,希望还能和大家相互交流,有什么理解不对的地方欢迎指正~
相关的基于MST的其他论文也结合代码看了许多,附上几篇,有时间也写写读后感。
Segment-Tree based Cost Aggregation for Stereo Matching
ITERATIVE COLOR-DEPTH MST COST AGGREGATION FOR STEREO MATCHING
A Nonlocal Method with Modified Initial Cost and Multiple Weight for Stereo Matching
Cross-Scale Cost Aggregation for Stereo Matching