Non-local neural networks
CVPR2018
Local & non-local
Local这个词主要是针对感受野(receptive field)来说的。以卷积操作为例,它的感受野大小就是卷积核大小,而我们一般都选用 3 ∗ 3 3*3 3∗3, 5 ∗ 5 5*5 5∗5之类的卷积核,它们只考虑局部区域,因此都是local的运算。同理,池化(Pooling)也是。但其实全局的信息对于图像的任务更有价值,比如短视频分类任务等等。相反的,non-local指的就是感受野可以很大,而不是一个局部领域。
那我们碰到过什么non-local的操作吗?有的,全连接就是non-local的,而且是global的。但是全连接FC带来了大量的参数,给优化带来困难。这也是深度学习(主要指卷积神经网络)近年来流行的原因,考虑局部区域,参数大大减少了,能够训得动了。
那我们为什么还需要non-local?
我们知道,卷积层的堆叠可以增大感受野,但是如果看特定层的卷积核在原图上的感受野,它毕竟是有限的。这是local运算不能避免的。然而有些任务,它们可能需要原图上更多的信息,比如attention。**如果在某些层能够引入全局的信息,就能很好地解决local操作无法看清全局的情况,为后面的层带去更丰富的信息。**这是我个人的理解。
网络模型
Non-local block模型计算
本文的non-local可以被封装成一个block,用于任何网络。把position当成了一个权重,这里的position可以指空间,时间,或者时空关系,计算全局的关联性。
视频中第一帧的A1区域和第十帧中A3区域有关联性,或者静态图像中,有些区域有关系,如果找到这些关系,就可以更好的分析目标整体的动作。
文章对于non-local运算的设计。为了能够当作一个组件接入到以前的神经网络中,作者设计的non-local操作的输出跟原图大小一致,具体来说,是下面这个公式:
y i = 1 C ( x ) ∑ ∀ j f ( x i , x j ) g ( x j ) (1) \mathrm{y}_{i}=\frac{1}{\mathcal{C}(\mathrm{x})} \sum_{\forall j} f\left(\mathrm{x}_{i}, \mathrm{x}_{j}\right) g\left(\mathrm{x}_{j}\right) \tag{1} yi=C(x)1∀j∑f(xi,xj)g(xj)(1)
- i i i 表示输出的索引,可以是空间上的、时间上的、时空上的索引位置;
- j j j 表示所有可能位置的索引,用来做与输出位置的相关性的比较,(输入为两个位置,输出为一个位置关于另一个位置的关系);
- x x x 是输入的向量(可以是图片,序列,视频,或者是特征), y y y是输出的向量(与输入形状相同)
- f ( ⋅ , ⋅ ) f(\cdot,\cdot) f(⋅,⋅)是一个计算任意两点( i i i点和 j j j点)关系的函数(可以是相关性),相当于找到了当前图片或特征图中每个像素与其他所有位置像素的归一化相关性;
- g ( ⋅ ) g(\cdot) g(⋅) 是一个一元函数,计算一个点的特征,将这个点映射成一个向量
- 1 C ( x ) \frac{1}{C(x)} C(x)1归一化参数

相似函数的问题
以图像为例,为了简化问题,作者简单地设置 g ( ⋅ ) g(\cdot) g(⋅)函数为一个 1 ∗ 1 1*1 1∗1的卷积。相似性度量函数 f ( ⋅ , ⋅ ) f(\cdot,\cdot) f(⋅,⋅)的选择有多种:
- Gaussian:
f ( x i , x j ) = e x i T ⋅ x j C ( x ) = ∑ ∀ j f ( x i , x j ) \begin{aligned} f\left(\mathrm{x}_{i}, \mathrm{x}_{j}\right)&=e^{\mathrm{x}_{i}^{T} \cdot \mathrm{x}_{j}}\\ \mathcal{C}(x)&=\sum_{\forall j} f\left(\mathrm{x}_{i}, \mathrm{x}_{j}\right) \end{aligned} f(xi,xj)C(x)=exiT⋅xj=∀j∑f(xi,xj)
其中 x i T x j x_{i}^{T} x_{j} xiTxj是点乘相似度(dot-product similarity)。也可以用欧式距离,但是点乘在深度学习平台上更好实现。此时归一化参数 C ( x ) = ∑ ∀ j f ( x i , x j ) \mathcal{C}(x)=\sum_{\forall j} f\left(\mathrm{x}_{i}, \mathrm{x}_{j}\right) C(x)=∑∀jf(xi,xj)。
- Embedded Gaussian:
f ( x i , x j ) = e θ ( x i ) T ⋅ ϕ ( x j ) C ( x ) = ∑ ∀ j f ( x i , x j ) \begin{aligned} f\left(\mathrm{x}_{i}, \mathrm{x}_{j}\right)&=e^{\theta\left(\mathrm{x}_{i}\right)^{T} \cdot \phi\left(\mathrm{x}_{j}\right)}\\ \mathcal{C}(x)&=\sum_{\forall j} f\left(\mathrm{x}_{i}, \mathrm{x}_{j}\right)\\ \end{aligned} f(xi,xj)C(x)=eθ(xi)T⋅ϕ(xj)=∀j∑f(xi,xj)
其中 θ ( x i ) = W θ x i \theta\left(x_{i}\right)=W_{\theta} x_{i} θ(xi)=Wθxi 和 ϕ ( x j ) = W ϕ x j \phi\left(x_{j}\right)=W_{\phi} x_{j} ϕ(xj)=Wϕxj是两个
embedding。归一化参数和之前一致,为 C ( x ) = ∑ ∀ j f ( x i , x j ) \mathcal{C}(x)=\sum_{\forall j} f\left(\mathrm{x}_{i}, \mathrm{x}_{j}\right) C(x)=∑∀jf(xi,xj)这里和self attention比较相似
- Dot Product:
f ( x i , x j ) = θ ( x i ) T ⋅ ϕ ( x j ) C ( x ) = ∣ { i ∣ i is a valid index of x } ∣ \begin{aligned} f\left(\mathrm{x}_{i}, \mathrm{x}_{j}\right)&=\theta\left(\mathrm{x}_{i}\right)^{T} \cdot \phi\left(\mathrm{x}_{j}\right)\\ \mathcal{C}(x)&=\mid\{i \mid i \text { is a valid index of } \mathrm{x}\} \mid\\ \end{aligned} f(xi,xj)C(x)=θ(xi)T⋅ϕ(xj)=∣{ i∣i is a valid index of x}∣
这里我们使用
embedded version。在这里,归一化参数设为 C ( x ) = N C ( x ) = N C(x)=N ,其中 N N N是 x x x的位置的数目,而不是 f ( ⋅ ) f(\cdot) f(⋅)的和,这样可以简化梯度的计算。这种形式的归一化是有必要的,因为输入的size是变化的,所以用 x x x的size作为归一化参数有一定道理。
dot product和embeded gaussian的版本的主要区别在于是否做softmax在这里的作用相当于是一个激活函数。
- Concatenation:
f ( x i , x j ) = ReLU ( w f T ⋅ [ θ ( x i ) , ϕ ( x j ) ] ) C ( x ) = ∣ { i ∣ i is a valid index of x } ∣ \begin{aligned} f\left(\mathrm{x}_{i},\mathrm{x}_{j}\right) &=\operatorname{ReLU}\left(\mathrm{w}_{f}^{T} \cdot\left[\theta\left(\mathrm{x}_{i}\right),\phi\left(\mathrm{x}_{j}\right)\right]\right)\\ \mathcal{C}(x) &=\mid\{i \mid i \text { is a valid index of } \mathrm{x}\} \mid \end{aligned} f(xi,xj)C(x)=ReLU(wfT⋅[θ(xi),ϕ(xj)])=∣{ i∣i is a valid index of x}∣
这里 [ ⋅ , ⋅ ] [\cdot,\cdot] [⋅,⋅]表示的是
concat, w f w_f wf是能够将concat的向量转换成一个标量的权重向量。这里设置$C ( x ) = N $。这相当于embedded的两个点拼接作为带ReLU激活函数全连接层的输入。它在visual reasoning中用的比较多。




这里有两点需要提一下:
- 后两种选择的归一化系数 C ( x ) \mathcal{C}(x) C(x)选择为 x x x的点数,只是为了简化计算,同时,还能保证对任意尺寸的输入,不会产生数值上的尺度伸缩。
Embedding的实现方式,以图像为例,在文章中都采用 1 ∗ 1 1*1 1∗1的卷积,也就是 θ ( ⋅ ) \theta(\cdot) θ(⋅) 和都 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)是卷积操作。
为了能让non-local操作作为一个组件,可以直接插入任意的神经网络中,作者把non-local设计成residual block的形式,让non-local操作去学 x x x的residual:
z i = W z ⋅ y i + x i \mathrm{z}_{i}=W_{z} \cdot \mathrm{y}_{i}+\mathrm{x}_{i} zi=Wz⋅yi+xi
W s W_s Ws实际上是一个卷积操作,它的输出channel数跟 x x x一致。这样以来,non-local操作就可以作为一个组件,组装到任意卷积神经网络中。
网络具体实现
如果按照上面的公式,用for循环实现肯定是很慢的。此外,如果在尺寸很大的输入上应用non-local layer,也是计算量很大的。
解决方案如下图所示
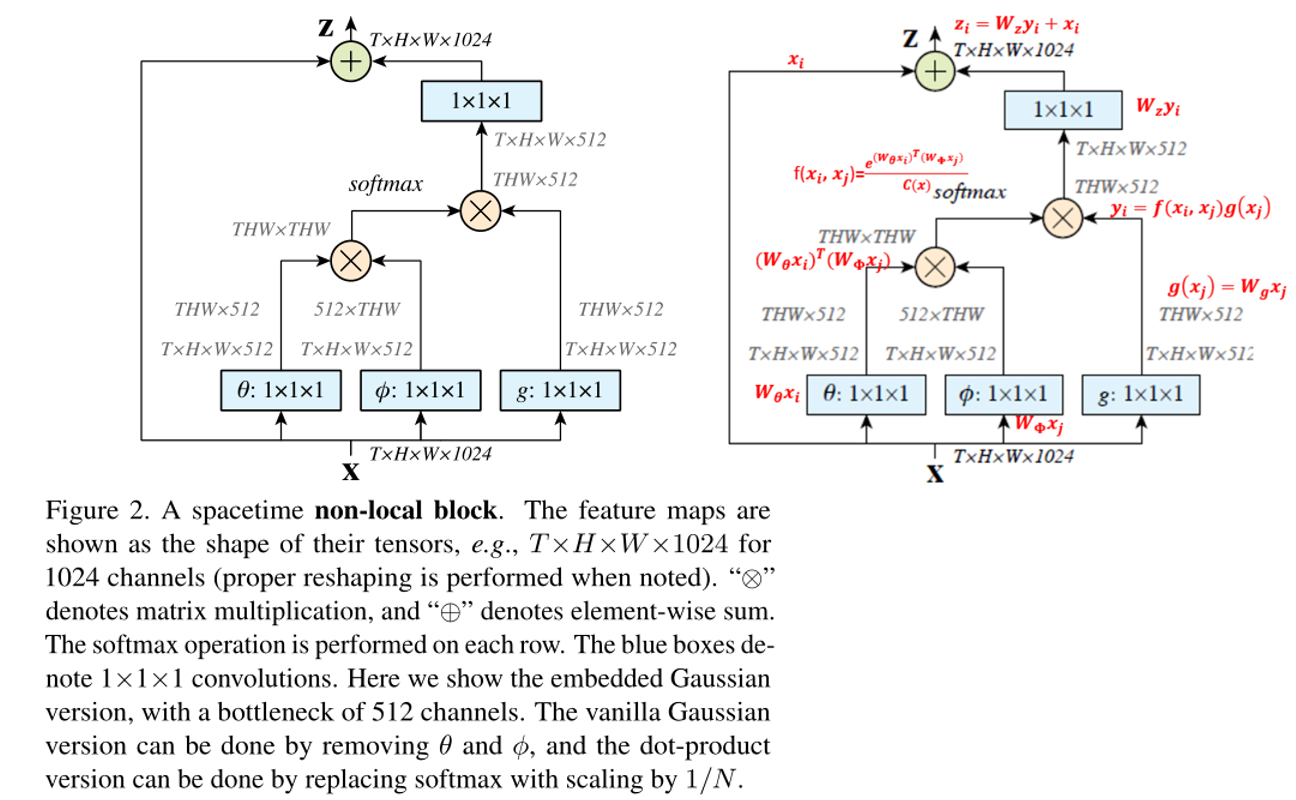
只在高阶语义层中引入
non-local layer减少计算量;通过对
embedding( θ ( ⋅ ) \theta(\cdot) θ(⋅) 和 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅))的结果加pooling层来进一步地减少计算量;注意到 f ( ⋅ ) f(\cdot) f(⋅)的计算可以化为
矩阵运算,我们实际上可以将整个non-local化为矩阵乘法运算+卷积运算。(在tensorflow和pytorch中,batch matrix multiplication可以用matmul函数实现。在keras中,可以用batch_dot函数或者dot layer实现。)
- 其中 c c c为
output_channels,卷积操作的输出filter数量。- ⊗ \otimes ⊗ 矩阵乘法
- ⊕ \oplus ⊕基于元素的矩阵加法
bottleneck结构压缩计算量,增加编码效果- 归一化使用 1 N \frac{1}{N} N1
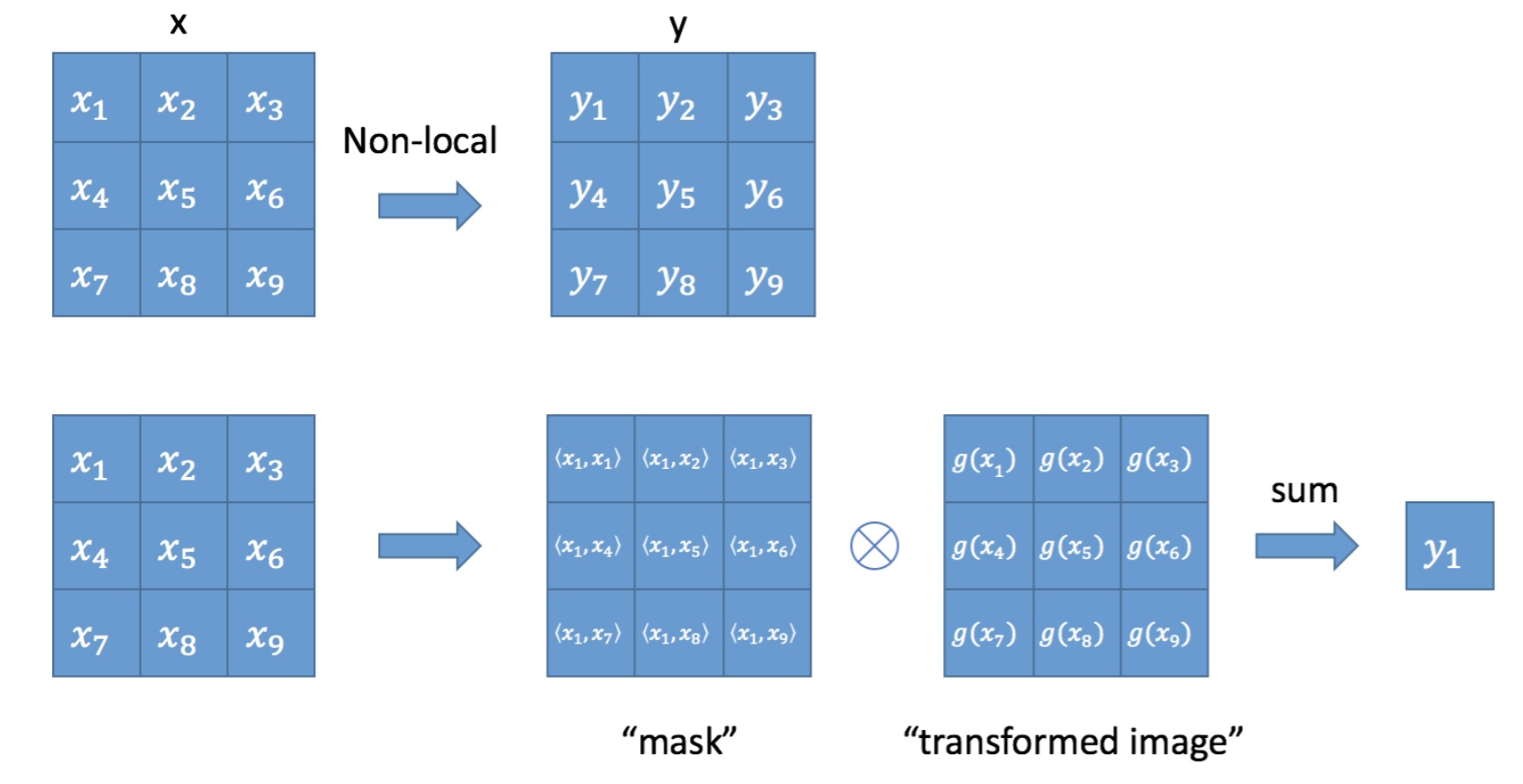
Non-local block为什么可以反映注意力
根据公式(1),为了计算输出层的一个点,需要将输入的每个点都考虑一遍,而且考虑的方式很像attention:输出的某个点在原图上的attention,而mask则是相似性给出。参看下图。
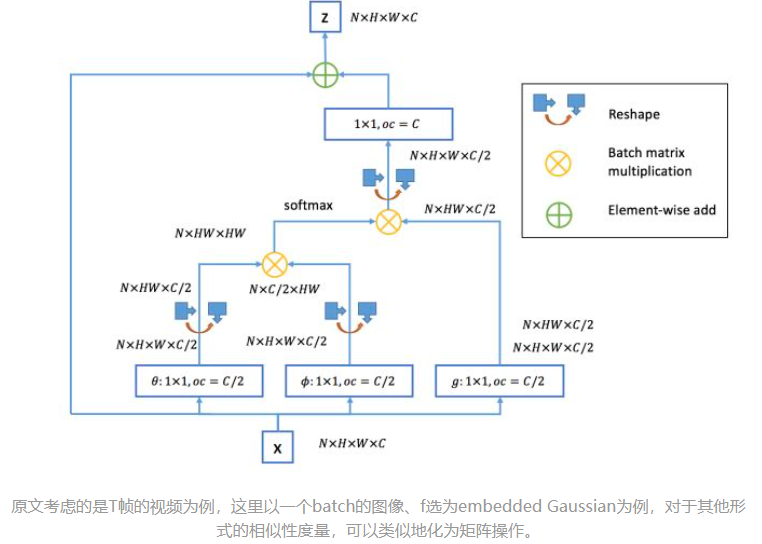
空间注意力
当考虑是图片时候,故可以直接设置 T = 1 T=1 T=1,或者说不存在。首先网络输入是 x ∈ R H ∗ W ∗ 1024 x\in \mathbb R^{H*W*1024} x∈RH∗W∗1024,经过Embedded Gaussian中的两个嵌入权重变换 W θ , W ϕ W_\theta,W_\phi Wθ,Wϕ得到两个$ \mathbb R^{HW512} 其 实 这 里 的 目 的 是 降 低 通 道 数 , 减 少 计 算 量 ; 然 后 分 别 对 这 两 个 输 出 进 行 ‘ r e s h a p e ‘ 操 作 , 变 成 其实这里的目的是降低通道数,减少计算量;然后分别对这两个输出进行`reshape`操作,变成 其实这里的目的是降低通道数,减少计算量;然后分别对这两个输出进行‘reshape‘操作,变成 \mathbb R^{(HW)1024} , 后 对 这 两 个 输 出 进 行 矩 阵 乘 ( 其 中 一 个 要 转 置 ) , 计 算 相 似 性 , 得 到 ,后对这两个输出进行矩阵乘(其中一个要转置),计算相似性,得到 ,后对这两个输出进行矩阵乘(其中一个要转置),计算相似性,得到\mathbb R^{(HW)(HW)} , 然 后 在 第 2 个 维 度 即 后 一 个 维 度 上 进 行 ‘ s o f t m a x ‘ 操 作 , 得 到 ,然后在第2个维度即后一个维度上进行`softmax`操作,得到 ,然后在第2个维度即后一个维度上进行‘softmax‘操作,得到\mathbb R^{(HW)*(HW)}$,这样做就是空间注意力,相当于找到了当前图片或特征图中每个像素与其他所有位置像素的归一化相关性;
然后将 g ( ⋅ ) g(\cdot) g(⋅)也采用一样的操作,先通道降维,然后reshape;然后和 R ( H W ) ∗ ( H W ) \mathbb R^{(HW)*(HW)} R(HW)∗(HW)进行矩阵乘,得到 R ( H W ) ∗ 512 \mathbb R^{(HW)*512} R(HW)∗512,即将空间注意力机制应用到了所有通道的每张特征图对应位置上,本质就是输出的每个位置值都是其他所有位置的加权平均值,通过softmax操作可以进一步突出共性。最后经过一个1x1卷积恢复输出通道 R H ∗ W ∗ 1024 \mathbb R^{H*W*1024} RH∗W∗1024,保证输入输出尺度完全相同。
实验与讨论
如何让nonlocal高效?
当non-local用于高层的feature map时, T H W THW THW(视频信号所以多一个维度)都比较小,这样它的运算量就比较轻量了。
- W g , W θ , W ϕ W_g, W_\theta , W_\phi Wg,Wθ,Wϕ将 x x x的
channel变成原始输入的一半,然后 W z W_z Wz 再变回来 - 有一个
subsampling的trick可以进一步使用,就是将(1)式变为: y i = 1 / C ( x ^ ) ∑ ∀ j f ( x i , x ^ j ) g ( x ^ j ) y_{i}=1 / C(\hat{x}) \sum_{\forall j} f\left(x_{i}, \hat{x}_{j}\right) g\left(\hat{x}_{j}\right) yi=1/C(x^)∑∀jf(xi,x^j)g(x^j),其中 x ^ j \hat x_j x^j是 x x x下采样得到的(比如通过pooling),我们将这个方式在空间域上使用,可以减小 1 4 \frac{1}{4} 41的pairwise function的计算量。这个trick并不会改变non-local的行为,而是使计算更加稀疏了。这个可以通过在图2中的 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)和 g ( ⋅ ) g(\cdot) g(⋅)后面增加一个较小尺度的max pooling层实现。
跟全连接层的联系
non-local block利用两个点的相似性对每个位置的特征做加权全连接层则是利用position-related的weight对每个位置做加权。于是,全连接层可以看成non-local block的一个特例。
non-local block反应的是任意两位置之间的关系(相似性),是需要通过位置坐标取出来的值等计算的。但是全连接层的这个任意两点关系仅跟两点的位置有关,与位置上的值无关,即 f ( x i , x j ) = w i j f(x_i,x_j) = w_{ij} f(xi,xj)=wij全连接中 g ( ⋅ ) g(\cdot) g(⋅)是identity函数,直接取值就可以, g ( x i ) = x i g(x_i) = x_i g(xi)=xi全连接层归一化系数为 1 1 1。归一化系数跟输入无关全连接层不能处理任意尺寸的输入。
跟Self-attention的联系
这部分在原文中也提到了。Embedding的1*1卷积操作可以看成矩阵乘法:
{ θ ( x i ) = W θ ⋅ x i ϕ ( x j ) = W ϕ ⋅ x j ⇒ { θ ( x ) = W θ ⋅ x ϕ ( x ) = W ϕ ⋅ x \begin{aligned} \begin{cases} \theta\left(\mathrm{x}_{i}\right)=W_{\theta} \cdot \mathrm{x}_{i}\\ \phi\left(\mathrm{x}_{j}\right)=W_{\phi} \cdot \mathrm{x}_{j} \end{cases} \Rightarrow \begin{cases} \theta(\mathrm{x})=W_{\theta} \cdot \mathrm{x}\\ \phi(\mathrm{x})=W_{\phi} \cdot \mathrm{x} \end{cases} \end{aligned} {
θ(xi)=Wθ⋅xiϕ(xj)=Wϕ⋅xj⇒{
θ(x)=Wθ⋅xϕ(x)=Wϕ⋅x
于是,
y = softmax ( x T ⋅ W θ T ⋅ W ϕ ⋅ x ) ⋅ g ( x ) y=\operatorname{softmax}\left(\mathrm{x}^{T} \cdot W_{\theta}^{T} \cdot W_{\phi} \cdot \mathrm{x}\right) \cdot g(\mathrm{x}) y=softmax(xT⋅WθT⋅Wϕ⋅x)⋅g(x)
这就是文章Attention is all you need提出来的self-attention。
跟Gram matrix的联系
Gram matrix第一次被应用到风格迁移任务中(文章A neural algorithm of artistic style),并在后来成为style loss的标配。
gram matrix把一个channel看成一个点(坐标就是整个filter,长度等于一个feature map大小H*W)
而公式(1)则是把每个空间位置看成点(坐标是feature map在该空间所有位置上的值,长度等于channel数)。两者都是计算任意两个点之间的内积。它们的差别在于沿着feature map的不同方向做内积。
基于gram matrix的style loss可以捕捉到纹理信息;从上一节我们知道,non-local层试图起到attention的作用。由(文章Demystifying neural style transfer)我们知道,匹配gram matrix相当于最小化feature map的二次多项式核的MMD距离。而non-local暂时不知道。
实验结果比较
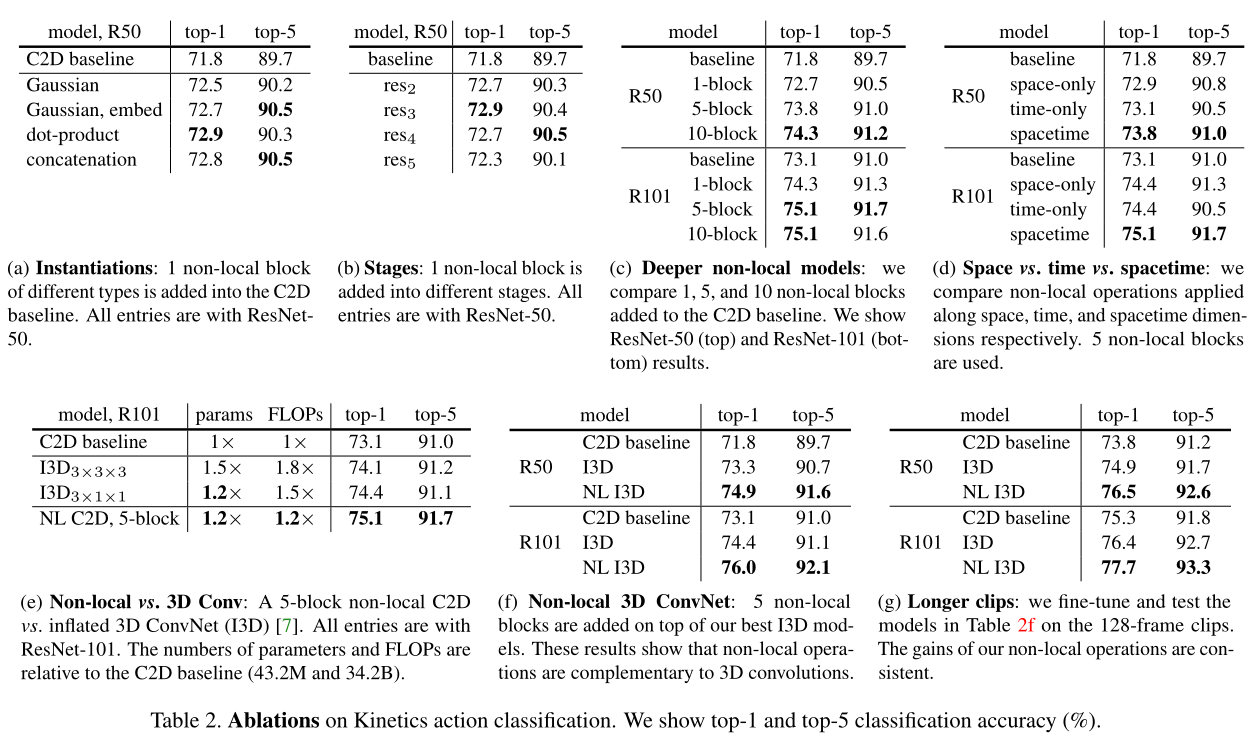
- 比较不同的相似关系函数
表2a比较了不同的
non-local block的形式插入到C2D得到的结果(插入位置在res4的最后一个residual block之前)。发现即使只加一个non-local block都能得到~1%的提高。有意思的是不同的
non-local block的形式效果差不多,说明是non-local block的结构在起作用,而对具体的表达方式不敏感。本文后面都采用embedded Gaussian进行实验,因为这个版本有softmax,可以直接给出[0,1]之间的scores
- 模块位置敏感性
表2b比较了一个
non-local block加在resnet的不同stage的效果,具体加在不同stage的最后一个residual block之前。发现在res2,res3,res4层上加non-local block效果类似,加在res5上效果稍差。这个的可能原因是res5的spatial size比较小,只有7*7,可能无法提供精确的spatial信息了。
- 不同数量的模块影响,同时比较参数量证明参数增加的更有价值
加入更多的
non-local blocks。表2c给出了加入更多non-local block的结果,我们在resnet-50上加1 block(在res4),加5 block(3个在res4,2个在res3,每隔1个residual block加1个non-local block),加10 block(在res3和res4每个residual block都加non-local block)。在resnet101的相同位置加block。发现更多non-local block通常有更好的结果。我们认为这是因为更多的non-local block能够捕获长距离多次转接的依赖。信息可以在时空域上距离较远的位置上进行来回传递,这是通过local models无法实现的。另外需要提到的是增加
non-local block得到的性能提升并不只是因为它给base model增加了深度。为了说明这一点,表2c中resnet50 5blocks能够达到73.8的acc,而resnet101 baseline是73.1,同时resnet50 5block只有resnet101的约70%的参数量和80%的FLOPs。说明non-local block得到的性能提升并不只是因为它增加了深度。
- 不同维度使用模块的评价
表2d给出了在时间维度,空间维度和时空维度分别做
non-local的结果。仅在空间维度上做就相当于non-local的依赖仅在单帧图像内部发生,也就是说在式(1)上仅对indexi i i的相同帧的indexj j j做累加。仅在时间维度上做也类似。表2d显示只做时间维度或者只做空间维度的non-local,都比C2D baseline要好,但是没有同时做时空维度的效果好。
参考文献
论文地址:Non-local Neural Networks
Keras复现:GitHub - titu1994/keras-non-local-nets: Keras implementation of Non-local Neural Networks
Pytorch复现:GitHub - AlexHex7/Non-local_pytorch: Implementation of Non-local Block.
Non-local neural networks - 知乎
语义分割之Dual Attention Network for Scene Segmentation - Hebye - 博客园
Non-local Neural Networks_CV大白菜的博客-CSDN博客