论文:Non-local Neural Networks for Video Classification
论文链接:https://arxiv.org/abs/1711.07971
代码链接:https://github.com/facebookresearch/video-nonlocal-net
这篇是CVPR2018的文章,将non local思想引入视频分类。这篇文章受传统的non-local mean operation启发,核心思想就是:our non-local operation computes the response at a position as a weighted sum of the features at all positions. 简单讲单纯的一层卷积操作其实都是很local的,因此为了达到non local的效果(也就是文中说的获取 long range dependency),一般就是不断叠加这样的特征提取层,这样高层网络的感受野(receptive field)就越来越大,获取的信息分布广度也越来越高。但是这种不断叠加的方式必然会带来计算量的增加和优化难度的增加,因此就有了本文作者提出的non local机制。
non-local操作如公式1所示,表达的意思就是利用xi附近的xj的信息来得到yi。
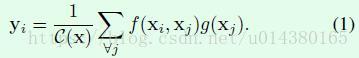
公式1中的xi和xj的含义可以参考Figure1的图表解释,字面上也是非常容易理解non local这种操作,就是在提取某处特征时利用其周围点的信息,这个“周围”既可以是时间维度的,也可以是空间维度的。时间维度的话就如这篇文章中的视频分类例子一样,可以更好地利用时序上的信息。

那么公式1中的两个函数具体要怎么实现呢?
在实验中为了简单计算,g()默认采用下面的形式(代码实现上通过卷积来实现):
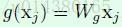
而f()函数是文章研究的重点,文章中列举了f()函数的4种形式:
1、Gaussian。

2、Embedded Gaussian。
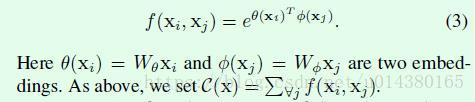
3、Dot product。
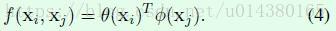
4、Concatenation。

我们把Figure2中的这一部分截图下来,这一部分实现的就是f()操作,可以看出前面介绍的Embedded Gaussian就是截图的完整操作(因为softmax操作会有一个分母,也就是C(x),因此截图中的softmax操作就完成了f()函数的幂计算和除以C(x)计算);Gaussian就是对应截图中去掉θ和φ的结果;Dot product对应截图中将softmax换成1/N。
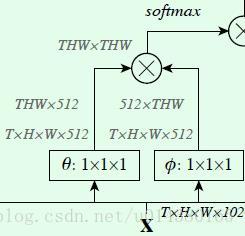
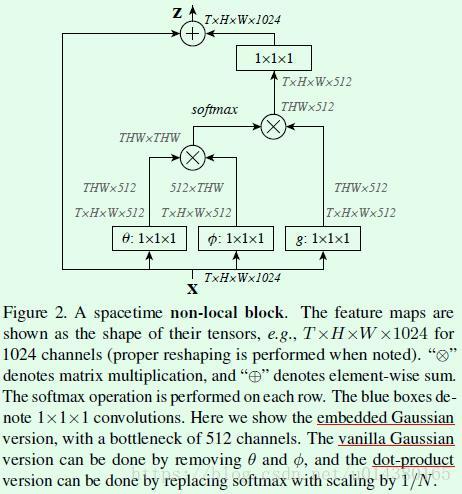
前面介绍的是f()函数的几种形式,接下来作者通过公式6将前面介绍的non local包装成一个block,这个block就类似ResNet网络中的block,这样non local操作就可以很方便地插入到现有的网络结构中。这里的yi就是前面公式1中的yi,W*y对应Figure2中右上角的1*1*1卷积;+xi就是residual connection,也就是Figure2中最上面的element-wise sum操作。

因此公式1+公式3+公式6就是Figure2。换句话说Figure2表示f()函数采取Embedded Gaussian且添加了residual connection的计算图。数据流是这样的:输入x的维度是T*H*W*1024,然后分别用数量为512,尺寸为1*1*1的卷积核进行卷积得到3条支路的输出,维度都是T*H*W*512,然后经过flat和trans操作得到THW*512、512*THW和THW*512的输出,前两条支路的两个输出进行矩阵乘法得到THW*THW的输出,经过softmax处理后再和第三条支路的输出做矩阵乘法得到THW*512维度的输出,将该输出reshape成T*H*W*512维度的输出后经过卷积核数量为1024,尺寸为1*1*1的卷积层并和原来的T*H*W*1024做element-wise sum得到最后的输出结果,这个element-wise sum就是ResNet网络中的residual connection。
为了提高non local block的计算效率,作者还从两个角度做了优化:1、θ、φ和g操作的卷积核数量设定为输入feature map通道数的一半(Figure2中512对1024)。2、对φ和g输出采取pooling方式进行抽样,这样φ和g输出的feature map的size就减小为原来的一半。这二者在代码中都有体现。
从公布的代码来看,non local并不是对网络的每个block都引入,思考下原因可能是:non local机制的设计初衷就是为了获取全局信息,而原来的卷积操作是为了获取局部信息,二者相辅相成才能有好的效果。
实验结果:
Table2是在Kinetics数据集(视频分类)上的效果分析。(a)中对比了几种不同f()函数的结果,没有太大差别,后面的实验基本都是基于Embedded Gaussian。
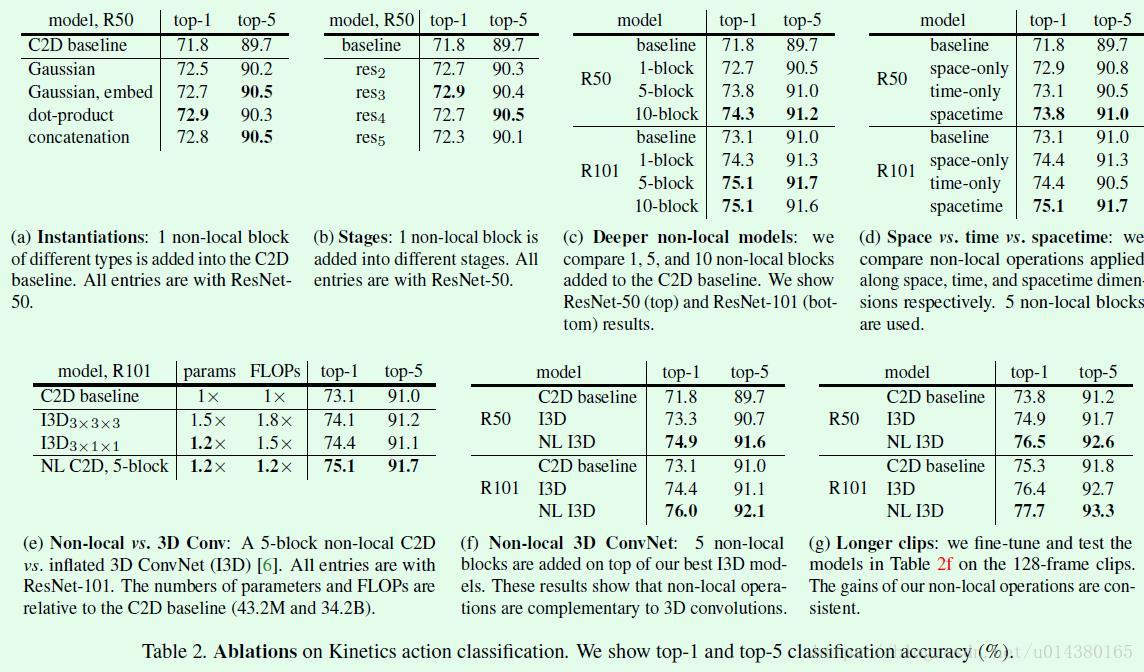
Table3是在Kinetics数据集上和其他算法的对比,可以看出只采用RGB作为输入的non-local I3D算法效果还是很不错的。
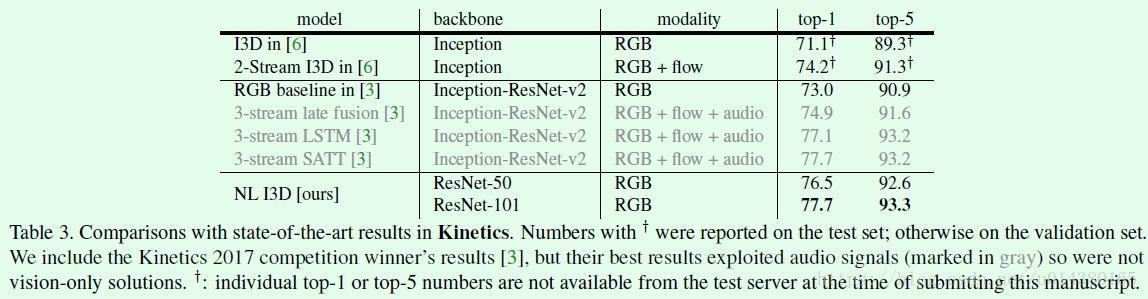
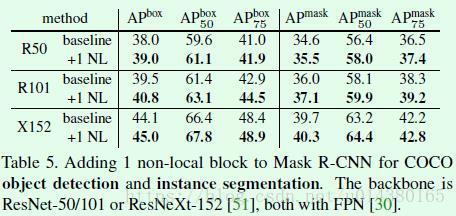
Table5是non-local机制在COCO数据集上的检测和分割效果提升情况,基本上都能提升1个百分点。