Non-local Neural Networks基于non-local means的思想捕获远程依赖,提高了视频分类和图片分类的分类精度。
Motivation
捕获远程依赖性在深度神经网络中至关重要。对于序列数据,捕获远程依赖的主要方法是循环操作(循环网络)。对于图片数据,捕获远程依赖的方法是使用一叠卷积层来获取大的接收域。卷积和循环操作都是处理局部的邻近区域(local neighborhood),不管是空间上还是时间上。因此,捕获远程依赖的唯一方法是不断重复卷积或循环操作,把远程依赖纳入到局部依赖中。重复这些局部操作有3点局限性,第一,计算效率不高;第二,引起优化困难;第三,当信息需要在远距离位置来回传递时,多跳模型难以实现。

例如,上图的卷积区域的人脸与卷积区域之外的手脚有依赖关系,需要经过多层卷积层之后才能捕获到这种远程依赖。

在一个短视频中,男孩在玩足球,其中一帧图片中的足球与多帧图片的足球和男孩都有关系,上图每两张图片之间的间隔是8帧。R-CNN只能在相邻两帧图片之间传递依赖关系,想要传递远程依赖,只能多循环几次。
如果模型能直接捕获到这种远程依赖,模型的性能会更好,同时提高运行效率。
Innovation
作者从经典的图像处理算法non-local means中得到启发,提出了non-local操作和non-local块。
non-local means是一种经典的滤波算法,它的思想是:当前像素点的灰度值与图像中所有与其结构相似的像素点加权平均得到。应用到卷积模型,就是feature map上的某一点X的响应值是与其他位置的所有点的关系值的加权和,所有点可以是空间范围,时间范围或者空间时间范围上的点。两点之间的依赖关系越强,其权重越高。
non-local operation就是计算某一点X的non-local响应值。non-local block可以嵌入到任何卷积模型中。
Advantages
第一,non-local操作直接通过计算两个位置的相互影响来捕获远程依赖,不管两个位置之间的距离有多远。
第二,non-local操作有效率,只需少量的网络层就能达到最优的结果。
第三,non-local操作保持输出大小不变,可以容易地与其他操作相结合。
上图是作者non-local操作的可视化。位置
的响应值通过对
所有位置的特征加权平均得到,上图的箭头表示值最大的前20个权重。上图可以说明non-local确实可以捕获到远程依赖。
Non-local Neural Networks
Non-local Neural Networks就是包含non-local块的网络,non-local块就是进行non-local操作的网络层。
Non-local operation
首先介绍non-local操作的公式:
其中i表示输入位置(在空间上、时间上或空间时间上的位置)的序号,这个位置要计算响应值,j表示其他所有位置的序号。 表示输入信号,而 表示输入信号(响应值),和 同样大小。函数 计算一个标量,用来表示位置i与j的关系,相当于权重。函数 计算位置j处输入信号的表示。 用于标准化响应值。
non-local操作考虑了所有的位置 。与之相反,卷积操作只是对局部区域进行加权求和,循环操作在第i时间步只基于本次时间步和上一次时间步。non-local操作同样与全连接层不同,全连接层使用学习到的权值,而non-local操作计算响应值只基于两个位置之间的关系,而且non-local操作接收任何大小的输入,同时输出大小不变,而全连接操作只能接收固定长度的输入,而且忽略了位置之间的对应关系。
non-local块非常灵活,可以很容易地与卷积层或循环层结合使用。它可以放在网络前面的部分,让网络同时捕获non-local和local的信息。
,至于函数 ,作者提出了几种实现方法。
Gaussian
根据non-loca mean和双边过滤算法,f很自然的选择高斯函数。
标准化因子是 。比较两个向量是否相似,可以计算两个向量的L2距离,距离越小,相似度越高,或者计算两个向量的点乘,点乘越大,相似度越高。作者为了计算方便,使用点乘操作计算两个向量的相似度。
Embeded Gaussian
Embeded Gaussian是高斯方法的简单扩展,它是在一个嵌入的空间中计算相似度。
其中 , 是两个嵌入向量。同时设 。
这里, 可以看成是在j维度上的softmax,因此,最初的公式可以写成
Dot product
Dot product简化Embeded Gaussian,直接计算嵌入向量的点乘
为了简化梯度计算, ,其中N为 的位置数。
Concatenation
把两个嵌入向量拼接在一起,加上ReLU激活函数
同样, 。
这几种不同的实现版本说明了non-local操作的灵活性。还可能有其他更好的实现。
Non-local Block
一个non-local块是
公式后面 代表一个残差连接。残差连接允许我们在任何预训练的模型中插入一个新的non-local块,不用改变non-local块的初始化行为。
一个non-local块的实现如下图所示:
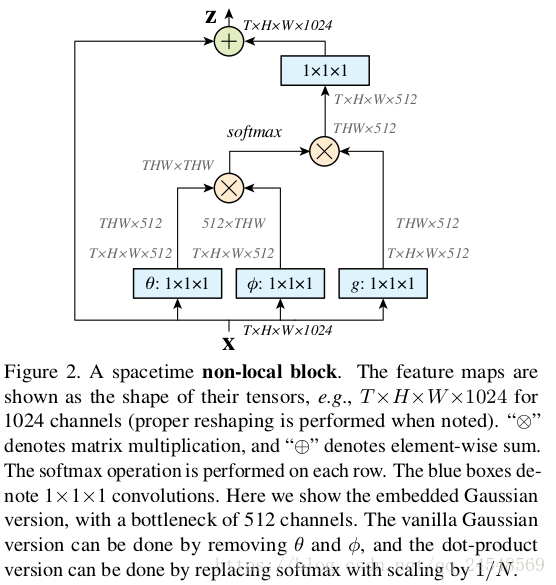
在这里,
的通道数是
的一半,这是依照bottleneck进行设计,可以减少计算量。
作者还提出了减少计算量的技巧。他把non-local操作的公式修改为
其中 是 二次采样版本,比如说通过池化 得到 。
Video Classification Models
为了理解non-local网络的行为,作者对视频分类任务进行了全面的消融实验,作者使用两种网络与non-local network进行比较。
2D ConvNet baseline (C2D)
作者构建了一个简单的2D baseline架构,称作C2D,如下图所示:

上图网络的原型是ResNet-50,输入的数据是
,T表示视频的帧数,H和W分别表示高和宽。上表的所有卷积操作使用2D kernel,分别对每帧图片进行处理。涉及时间维度上的操作只有pooling层。基于ResNet-50和ResNet-100的模型都使用ImageNet数据进行预训练。
Inflated 3D ConvNet(I3D)
我们可以把C2D模型通过膨胀卷积核变成3D卷积模型。例如,一个2D 的卷积核可以膨胀成3D的 的卷积核。这个3D卷积核可以从已经训练好的2D卷积核初始化,每个t面的 的核使用2D的卷积核初始化,同时除以 。因为如果视频所有帧都是同一副图像,该初始化操作可以得到和2D卷积处理同样图像一样的结果。
作者研究了两种膨胀方式。第一种,把残差块的 卷积核膨胀成 ,记为I3D 。第一种,把残差块的第一个 卷积核膨胀成 ,记为I3D 。I3D模型2个残差块膨胀一次卷积核。I3D模型还把conv1膨胀成 。
Non-local network
作者往C2D或I3D模型中插入non-local块组成non-local模型,模型分成3种类型,插入non-local块的个数分别是1,5,10,插入位置如下图所示。
| - | 1 | 5 | 10 |
|---|---|---|---|
| ResNet-50 | res4 1 | res3 2 res4 3 |
res3 4 res4 6 |
| ResNet-101 | ResNet-50的对应位置 | 同左 | 同左 |
Experiments
最后来看看实验结果。作者对多个方面分析non-local。下面的实验都是在Kinetics数据集上进行的。

上图的实验结果显示,加了non-local块的C2D模型的错误率比C2D模型低。说明non-local操作是有效果的。
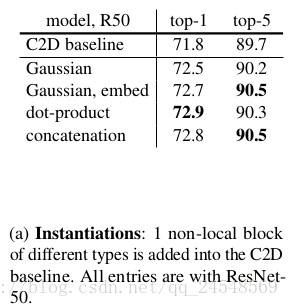
上图是比较不同non-local操作的实现版本的实验结果。可以看到,这4个实现的实验结果相差不大,而且都比baseline C2D的结果好,说明non-local的行为是改善实验结果的关键。
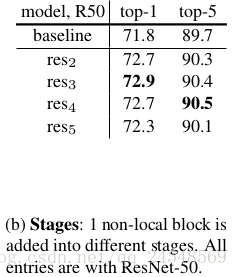
上图比较在不同阶段插入non-local块的实验结果。non-local块在每个阶段的最后一个残差块前面。在res2,res3,res4阶段插入一个non-local块的改进效果相似,而在res5阶段的效果差了点,原因可能是res5阶段有一个小的空间大小(输出大小为
),不能提供准确的空间信息。
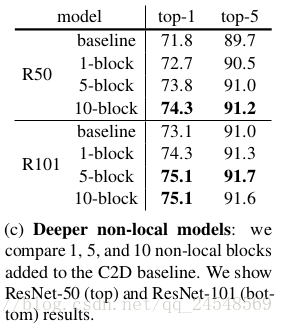
上图的实验结果说明了更多的non-local块提升模型的表现,多个non-local块可以执行远程多跳通信。远距离位置信息可以在时间维度上来回传递。同时应该注意到,non-local 5-block ResNet-50的模型在top-1有73.8%的精度,比更深的ResNet-101 baseline的73.1%要高,说明non-local块的提升效果不是因为加深了模型的网络。
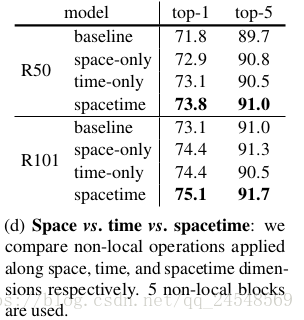
上图比较在不同维度上应用non-local操作的表现效果,同时在空间和时间维度上应用non-local操作的表现效果最好。
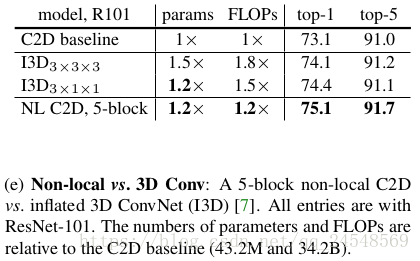
上图说明虽然3D ConvNet能够提高视频分类的分类精度,但是提升幅度低于non-local网络。而且non-local网络的参数和每秒浮点运算次数都比3D ConvNet要低,相比于3D ConvNet,non-local网络是一个更好的选择。
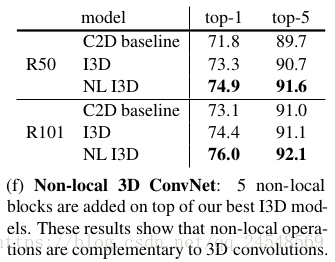
上图的实验结果显示把non-local块嵌入到I3D模型中同样可以提高模型的表现。non-local操作和3D卷积操作是互补的,3D卷积操作捕获局部依赖,non-local操作捕获远程依赖。
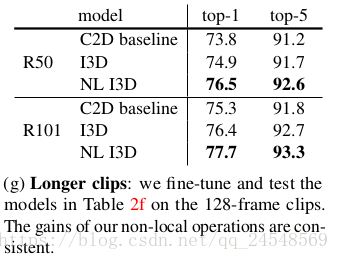
默认的输入数据大小为
,即输入32帧图片。上图是输入128帧图片的实验结果,更长的输入数据提供更多信息,所有模型分类效果都提升了,而且non-local模型的分类效果还是最好的。
![non-local vs state-of-the-art model]](https://img-blog.csdn.net/20180915142737641?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzI0NTQ4NTY5/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)
与其他先进的视频分类算法进行比较,ResNet-101的non-local I3D与3-stream SATT并列第一,而且non-local I3D没有使用视频的光流和声音信息。
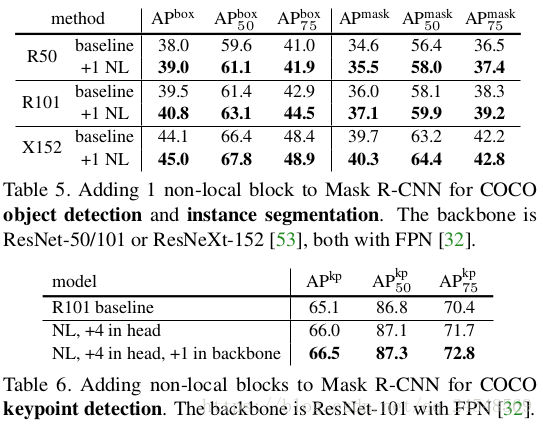
non-local操作不仅仅提高了视频分类的表现,同样也提高了静态图像的分类效果。实验结果如下图所示(数据集为COCO)