——同事推荐的一篇paper,想把它和SGBM opencv源码学习笔记写在一起,是因为感觉pipeline真的很像,可能他们都用了scanline optimization的原因吧 : )
前言
文中指出,在middleBury上排名前10的,基本都是那种将多种重量级算法(CC, CA, optimization, refine)串联起来,效果倒是好了,需要使用trick或是设计一些复杂的数据结构才能用GPU加速,在移动设备上使用,性能堪忧;
作者将几篇轻量级的模块组合在了一起,可以在GPU上进行加速,效果也还不错,使得在移动设备上使用成为了可能。其实,pipline也比较正常:AD Census + CBCA + Scanline Optimization + 常规Refine,分别引用自以下文献:
- AD Census:
X. Sun, X. Mei, S. Jiao, M. Zhou, and H. Wang. Stereo matching with reliable disparity propagation. In Proc. 3DIMPVT, pages 132–139, 2011. - CBCA:
K. Zhang, J. Lu, and G. Lafruit. Cross-based local stereo matching using orthogonal integral images. IEEE TCSVT, 19(7):1073–1079, 2009 - Scanline Optimization:
H. Hirschm¨uller. Stereo processing by semiglobal matching and mutual information. IEEE TPAMI, 30(2):328–341, 2008.
摘要
paper链接
源码链接
核心思想
代价计算(Cost Computation, CC): AD + Census,即:the absolute differences (AD) measure and the census transform
代价聚合(Cost Aggregation, CA): CBCA,即基于crossed窗口的代价聚合方法
视差求解(disparity computation): Scanline optimization + WTA,很常规,引用于SGM的扫描线优化 + winner takes all
后处理(post process, refine):区域投票 + 插值 + 边缘优化 + 亚像素增强
贡献点
作者构造了上述的pipeline,并基于cuda实现了GPU版本
相关研究

算法
AD Census
题外话:
R. Zabih and J. Woodfill. Non-parametric local transforms for computing visual correspondence. In Proc. ECCV, pages 151–158, 1994.
这篇paper里提到了一些代价计算的方法,包括AD, SGBM里边用的BT,Census等方法,空的时候可以去读读;
H. Hirschm¨uller and D. Scharstein. Evaluation of stereo matching costs on images with radiometric differences.
IEEE TPAMI, 31(9):1582–1599, 2009.
H. Hirschm¨uller 大牛做的一个代价计算特征的评估,结论如下:
census shows the best overall results in local and global stereo matching methods
Census思想:
对于左图中的点 \(\vec{p}= I_{left}(x, y)\),在视差层级 \(d\) 下,\(C_{census}(\vec{p}, d)\) 定义为以左图中点 \(\vec{p}\)为中心,整个邻域窗口内的census编码和以右图中点为中心\(\vec{pd} = I_{right}(x-d, y)\),邻域窗口的census编码之间的hamming距离,https://blog.csdn.net/qq_40313712/article/details/86349363 是一个比较简介明了的解释。
census优点——将邻域点像素值和当前点的相对关系编码起来,对噪声以及畸变引入的outliers有较好的鲁棒性
Census encodes local image structures with relative orderings of the pixel intensities other than the intensity values themselves, and therefore tolerates outliers due to radiometric changes and image noise
census不足——难以区分邻域点和当前点较为相似的区域,诸如: 重复纹理场景;
However, this asset could also introduce matching ambiguities in image regions with repetitive or similar local structures.
为解决Census的问题,提出结合AD来使用:
AD定义如下:
\[C_{AD}(\vec{p}, d) = \frac{1}{3}\sum_{i=R, G, B}|I_i^{left}(\vec{p}) - I_i^{right}(\vec{pd})| \tag{1}\]
AD Census的定义如下:
\[C_{AD Census} = \rho(C_{census}(\vec{p}, d), \lambda_{census}) + \rho(C_{AD}(\vec{p}, d), \lambda_{AD}) \tag{2}\]
其中, \(\rho(c, \lambda)\)的定义如下:
\(\rho(c, \lambda) = 1- exp(-\frac{c}{\lambda}) \tag{3}\)
一个简单对比如下图:

CBCA
代价聚合可看做对代价立方体做refine的一个过程,也就是传说中的聚合,用于降低噪声对后面视差计算的影响,CBCA全称是Cross-based Cost Aggregation,本质上就是一种cross型窗口的均值滤波,思想如下:
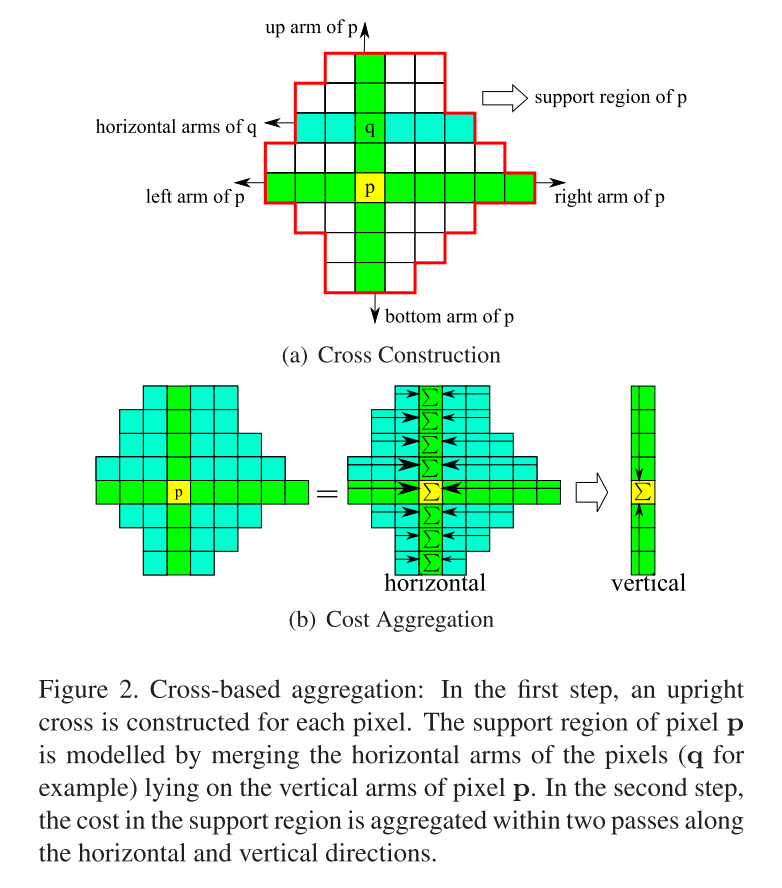
从上图可以总结CBCA可分为两步:
- cross窗口构造
- 窗口内的均值滤波
cross窗口构造
cross窗口,也就是十字窗口,会有自己的上下左右界限,左边界限到当前点之间的距离,也就是文中说的"left arm",上、下以及右亦如此;
每一个点都会有自己的cross窗口,用于实现下面的代价聚合;
现在问题来了,上下左右界限怎么确定,便是cross窗口构造要解决的核心问题。
纵观可利用的资源,有以下几个信息可以使用起来:
- 当前点和邻域点之间的颜色距离 \(D_c(\vec{p_1}, \vec{p}) = max_{i=R,G,B}|I_i(\vec{p_1}) - I_i(\vec{p})|\)
- 当前点和邻域点之间的空间距离 \(D_s(\vec{p_1}, \vec{p}) = |\vec{p1}-\vec{p}|\)
判断一个邻域点是否在当前点的cross窗口内,作者定义如下几个准则:
- \(D_c(\vec{p_1}, \vec{p}) < \tau_1\) 同时 \(D_c(\vec{p_1}, \vec{p_1} + (1, 0)) < \tau_1\)
- \(D_s(\vec{p_1}, \vec{p}) < L1\)
- 如果 \(L2<D_s(\vec{p_1}, \vec{p}) < L1\) 需满足:\(D_c(\vec{p_1}, \vec{p}) < \tau_2\)
1是保证不跨边缘做聚合,需要当前点和邻域点之间的颜色距离小于\(\tau_1\),同时,该邻域点和它往外一点之间的颜色距离也要小于\(\tau_1\);
2以及3,是为了cover住无纹理场景足够的平滑性,通过设定一个较大的\(L_1\)来对无纹理场景保证有足够大的窗口,如果窗口半径大于预设的半径\(L2\),则需满足\(D_c(\vec{p_1}, \vec{p}) < \tau_2\)才可以。
窗口内的均值滤波
一些先验知识:
均值滤波基于积分图来实现可以达到O(n)的复杂度,并实现radius-free;
分离为一维均值滤波行列方向交替进行,会比直接算二维均值滤波快;
在上面构造好cross窗口后,构造代价立方体的积分图,根据上一步计算得到的窗口半径即可实现cross型窗口的代价聚合;
由于cross型窗口均值滤波并非常规均值滤波,在经历行列交替的一维滤波后,通常会存在条状artifacts,因此,便有了作者下边的这部分迭代操作:
- 做4次迭代,一次迭代包含行方向和列方向;
- 1,3次迭代先行后列
- 2,4次迭代先列后行
引用一句作者的评价:
our improved method are presented in Figure 3, which shows that the enhanced cross construction rules and aggregation strategy can produce more accurate results in large textureless regions and near depth discontinuities.
对于一个研究滤波起家的人来看,这简直就是传说中的保边平滑性嘛,哈哈
Scanline Optimization
扫描线优化是从SGM原文里边引用的,核心思想可借用SGM原文的公式来表述:
\[E(D)=\sum_\vec{p}(C(\vec{p}, D_p) + \sum_{\vec{q}\isin{N_p}}P1T[|D_p-D_q|=1]+\sum_{\vec{q}\isin{N_p}}P2T[|D_p-D_q|>1])\tag{4}\]
为了得到一个全局最优结果,通常会构建一个包含数据项和平滑项的能量函数,通过最小化能量函数值来求得最优视差解。代价立方体本身存在一个代价,对于邻域内的像素点和当前点视差相差1的点做P1的惩罚,大于1的点做P2的惩罚。因此,第一项即为数据项,后面两项则为平滑项。
但由于在立体匹配中,代价立方体维度都会很大,想要求解这个最优化问题,直接用传统方法,内存和耗时都会很大。于是,SGM原文提出可使用动态规划求出近似解,代价函数简化成了下式:
\[C_\vec{r}=C_1(\vec{p}, d) + min(C_\vec{r}(\vec{p}-\vec{r}, d), C_\vec{r}(\vec{p}-\vec{r}, d \pm 1) + P1, min_kC_\vec{r}(\vec{p} - \vec{r} , k) + P2) - min_kC_\vec{r}(\vec{p}-\vec{r}, k)\tag{5}\]
定义 \(D_1 = d_c(\vec{p}, \vec{p}-\vec{r})\),\(D_2 = D_c(\vec{pd}, \vec{pd}-\vec{r})\), 通过\(D_1\)和\(D_2\)的值来控制\(P_1, P_2\)的值:
- \(P_1 = \Pi_1, P_2 = \Pi_2, if D_1 < \tau_{SO}, D_2 < \tau_{SO}\)
- \(P_1 = \Pi_1 / 4, P_2 = \Pi_2 / 4, if D_1 < \tau_{SO}, D_2 > \tau_{SO}\)
- \(P_1 = \Pi_1 / 4, P_2 = \Pi_2 / 4, if D_1 > \tau_{SO}, D_2 < \tau_{SO}\)
- \(P_1 = \Pi_1 / 10, P_2 = \Pi_2 / 10, if D_1 > \tau_{SO}, D_2 > \tau_{SO}\)
最终的代价立方体结果为: \(C_2(\vec{p}, d) = \frac{1}{4}\sum_\vec{r}C_\vec{r}(\vec{p}, d)\)
最终的视差图用WTA即可得到,即:对每个像素点,取代价最小的那个视差值作为当前点视差
Post-process & Refine
经由WTA计算得到的视差图通常在遮挡区域存在着无效视差,同时也会存在一些噪声点甚至是大面积出错的情况,作者用了以下几个模块来做refine:
Outlier Detection
这部分主要是基于左右视差图的一致性检测来提取出视差不准确区域,简单而粗暴的设一个阈值,左右图匹配点对应的左右视差大于某个阈值,则该点即为视差不准确点;
视差不准确点可分为两种:1)遮挡点;2)误匹配点
对于上述两种点的区分,作者使用的是SGM原文里的方法:
1) 在极线上搜索,若在右视差图上找到相交的点,则该点为误匹配点2) 在极线上右视差图上没有搜索到相交的点,则该点为遮挡点
Iterative Region Voting
对于上一步检测出来的outlier,统计其cross窗口中可靠点的视差直方图\(H_\vec{p}\),分为\(d_{max}+1\)个bins,对于可靠点数最多的bin即为\(d_\vec{p}^*\),记所有可靠像素点数为\(S_\vec{p} = \sum_{d=0}^{d=d_{max}}H_\vec{p}(d)\),当\(H_\vec{p}\)满足以下条件时:
\(S_\vec{p} > \tau_S, \frac{H_\vec{p}(d_\vec{p}^*)}{S_\vec{p}} > \tau_H\)
outlier处的视差由\(d_\vec{p}^*\)替代,五次迭代后,错误区域会少很多
Proper Interpolation
经由上一步之后,错误点会少很多。这一步会对误匹配点&遮挡点区别对待;
搜寻outliter周围最相近的16个方向上的可靠点;
对于遮挡点,选取其中最小的视差最为其视差值;
对于误匹配点,选取和其最相似的那个点的视差作为其视差值;
Depth Discontinuity Adjustment
Step 1: 检测视差图的边缘
Step 2: 判断边界点两边点的代价值,如果低于当前点的代价值,则调整当前边界点的视差至边界两边的那个点
Sub-pixel Enhancement
——基于quadratic polynomial interpolation的亚像素增强方法
后面再跟一个3x3的中值滤波
refine各个stage带来的收益:

实验
测试平台
PC with Core2Duo 2.20GHz CPU and NVIDIA GeForce GTX 480 graphics card
数据集
Middlebury
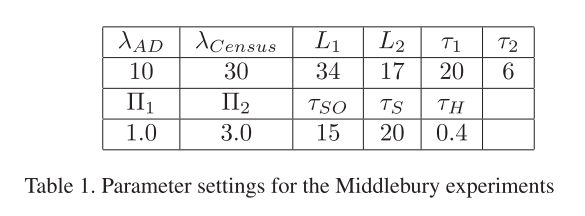
参数设置
性能
| Tsukuba | Venus | Teddy | Cones | |
|---|---|---|---|---|
| CPU | 2.5s | 4.5s | 15s | 15s |
| GPU | 0.016s | 0.032s | 0.095s | 0.094s |
tips
调参很重要
后记——SGBM OpenCV源码学习笔记
在opencv源码的位置:
opencv-4.0.0_src\opencv-4.0.0\modules\calib3d\src\stereosgbm.cpp
推荐博客:
https://blog.csdn.net/wwp2016/article/details/86080722
https://zhuanlan.zhihu.com/p/53060518
pipeline
pipeline很符合常规立体匹配pipeline:代价计算 -> 代价聚合 -> 视差计算 -> 视差后处理,和上面paper的逻辑极为相近,可以串起来做相关优化和尝试,所以把他们写在了一篇文档里。
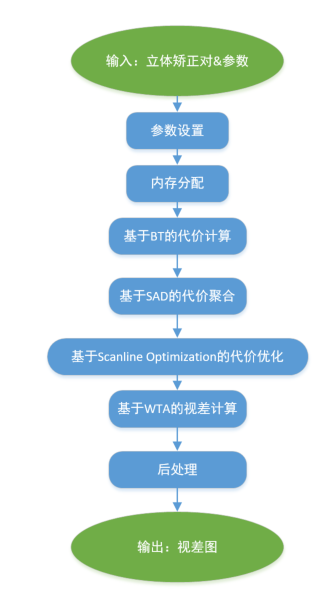
函数调用与参数解析
SGBM opencv源码将上述pipeline封装为两个接口供外界调用:1)通过带参数设置的构造函数设置参数;2)算法核心;
StereoSGBMImpl()
{
params = StereoSGBMParams();
}
StereoSGBMImpl( int _minDisparity, int _numDisparities, int _SADWindowSize,
int _P1, int _P2, int _disp12MaxDiff, int _preFilterCap,
int _uniquenessRatio, int _speckleWindowSize, int _speckleRange,
int _mode )
{
params = StereoSGBMParams( _minDisparity, _numDisparities, _SADWindowSize,
_P1, _P2, _disp12MaxDiff, _preFilterCap,
_uniquenessRatio, _speckleWindowSize, _speckleRange,
_mode );
// _minDisparity: 最小视差,默认为0; 对于实际应用中可能存在负视差的场景,可适当是设置为负视差,e.g. -3;
// _numDisparities: 视差层级,需设置为16的倍数,默认为16;
// 注意:输出视差图的视差层级为(16 * _minDisparity + _numDisparities);
// _SADWindowSize: SAD窗口直径,代价聚合部分,形同boxfilter的窗口直径,默认为5;
// _P1: 邻域点视差和当前点相差1的惩罚量,即上面eq4的P1,默认为2;
// _P2: 邻域点视差和当前点相差大于1的惩罚量,即上面eq4的P2, 默认:max(params.P2 > 0 ? params.P2 : 5, P1+1);
// _disp12MaxDiff: LR Check中不匹配点检测的阈值,默认:1;
// _preFilterCap: SGBM 代价计算是基于BT特征的,这个值是将每个匹配点对的匹配代价值抑制在_preFilterCap - 2 * _preFilterCap范围内;
// 注意:该值会影响到匹配代价的数量级,P1, P2的调参需要和该值协同修改;
// BT的大概思想:
// if k < 256*4 - _preFilterCap, 则CC = _preFilterCap;
// if 256*4 - _preFilterCap < k < 256*4 + _preFilterCap, 则CC = k - 256*4 + _preFilterCap;
// if k > 256*4 + _preFilterCap, 则CC = 2 * _preFilterCap;
// _uniquenessRatio: 唯一匹配检测阈值。要求除了bestDisp前后各一个视差之外,其余视差值对应的S必须大于minS * 1.x,默认为10, 大于1.1;
// _speckleWindowSize & _speckleRange: filterSpeckle的参数,用于对视差对做斑点去除的函数;
// _mode:
// - MODE_SGBM_3WAY:
// - MODE_HH4:
// - MODE_HH:默认模式
}
void compute( InputArray leftarr, InputArray rightarr, OutputArray disparr ) CV_OVERRIDE
{
CV_INSTRUMENT_REGION();
Mat left = leftarr.getMat(), right = rightarr.getMat();
CV_Assert( left.size() == right.size() && left.type() == right.type() &&
left.depth() == CV_8U );
disparr.create( left.size(), CV_16S );
Mat disp = disparr.getMat();
if(params.mode==MODE_SGBM_3WAY)
computeDisparity3WaySGBM( left, right, disp, params, buffers, num_stripes );
else if(params.mode==MODE_HH4)
computeDisparitySGBM_HH4( left, right, disp, params, buffer );
else
computeDisparitySGBM( left, right, disp, params, buffer );
medianBlur(disp, disp, 3);
if( params.speckleWindowSize > 0 )
filterSpeckles(disp, (params.minDisparity - 1)*StereoMatcher::DISP_SCALE, params.speckleWindowSize,
StereoMatcher::DISP_SCALE*params.speckleRange, buffer);
}一些代码细节
SGBM的三个模式
- MODE_SGBM_3WAY
- MODE_SGBM_HH
- MODE_SGBM_HH4
SGBM的内存管理
核心算法思想
基于BT的代价计算
——Birchfield-Tomasi metric
from BT org paper
最初是在A Pixel Dissimilarity Measure That Is Insensitive to Image Sampling中由Stan Birchfield and Carlo Tomasi提出,旨在提升相似性度量对image sampling的鲁棒,BT在该paper的Section 2中提出了BT的基本思路,在Section 3从理论上和实验中证明了该算法的有效性,具体的内容没有很清楚,但对BT的主要思想做了下梳理,内容如下:
对于两幅连续的立体对\(I_L(x_L)\), \(I_R(x_R)\),经过硬件处理、图像采样后,左图和右图匹配点的灰度值可能会出现一些偏差,而BT的思想就是基于简单的线性插值,搜索\(x+1, x-1\)的\(I_{min},I_{max}\)来协同表征当前位置下左右视图的相似度:
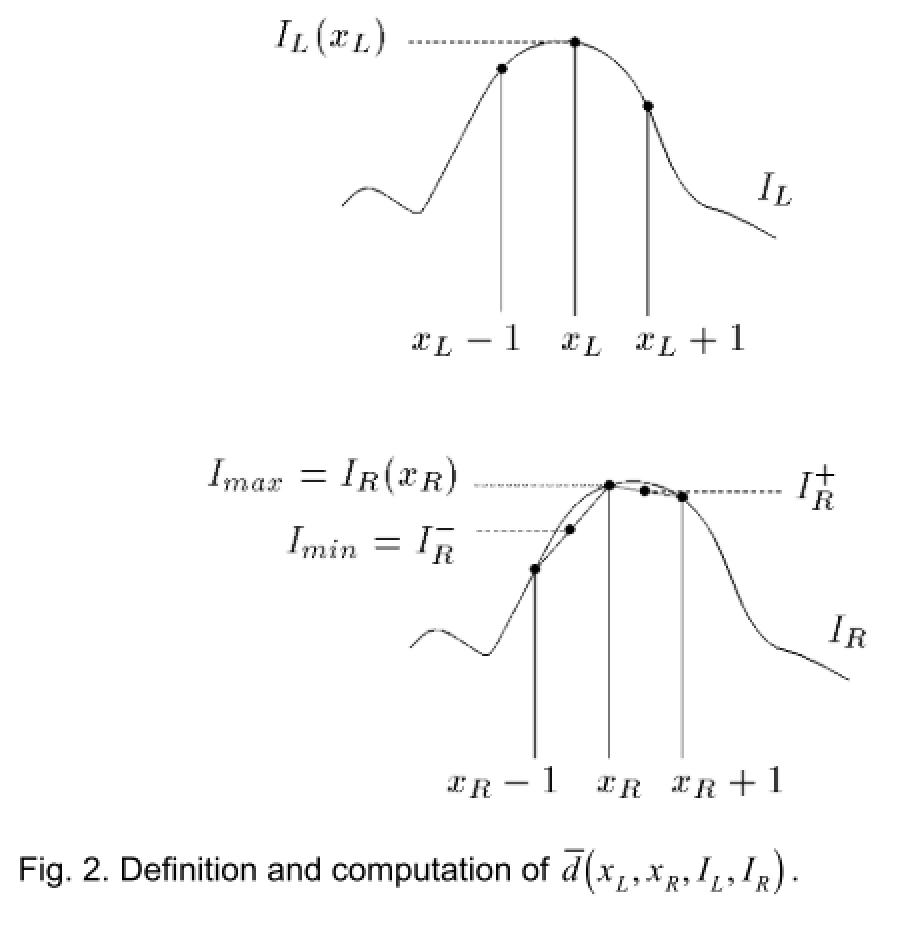
数学表达如下:
设\(I_R^- \equiv \hat{I_R}(x_R - \frac{1}{2}) = \frac{1}{2}(I_R(x_R) + I_R(x_R - 1))\), \(I_R^+ \equiv \hat{I_R}(x_R + \frac{1}{2}) = \frac{1}{2}(I_R(x_R) + I_R(x_R + 1))\)
设\(I_{min} = \min{I_R^-, I_R^+, I_R(x_R)}\), \(I_{max} = \max{I_R^-, I_R^+, I_R(x_R)}\)
则cost为\(\bar{d}(x_L, x_R, I_L, I_R) = \max{\{0, I_L(x_L) - I_{max}, I_{min} - I_L(x_L)\}}\)
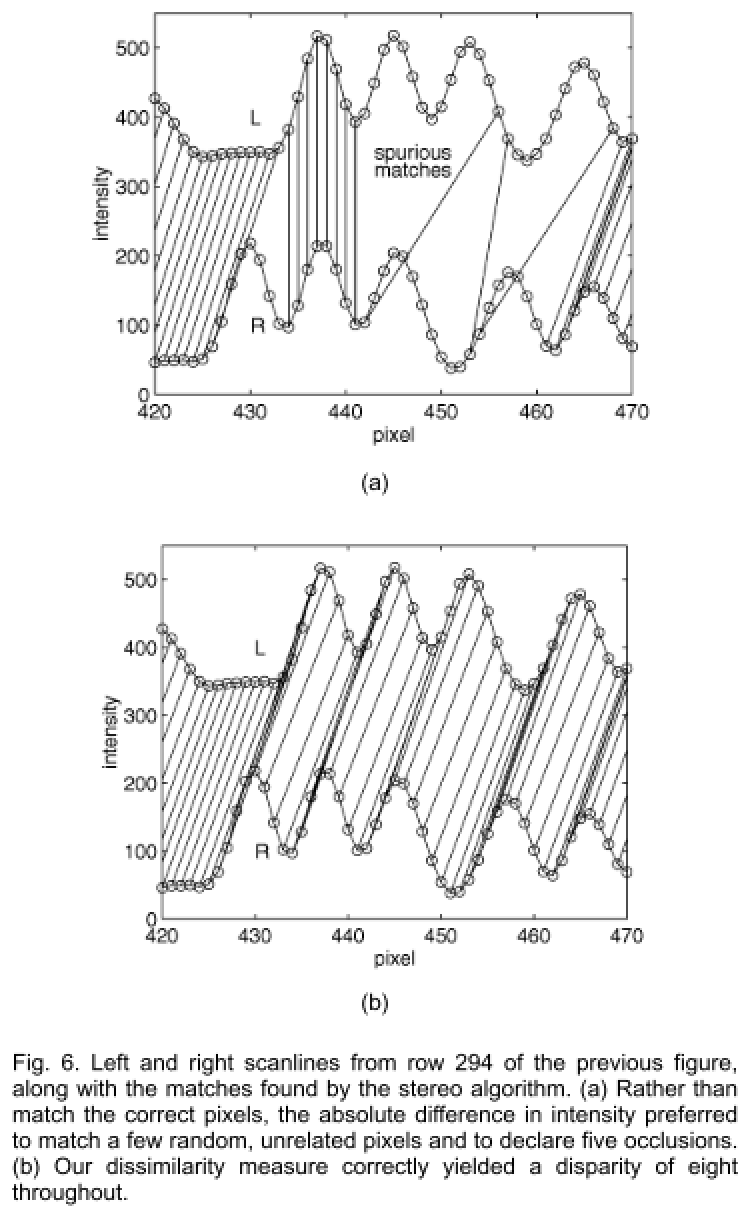
下图为BT vs AD的一个具体的例子:
SGBM中的BT
基于Scanline Optimization的代价优化
——代价聚合邻域点的取值方式
调用demo
#include "stdafx.h"
#include "opencv2/opencv.hpp
using namespace std;
using namespace cv;
int _tmain(int argc, _TCHAR* argv[])
{
Mat left = imread("imgL.jpg", IMREAD_GRAYSCALE);
Mat right = imread("imgR.jpg", IMREAD_GRAYSCALE);
Mat disp;
int mindisparity = 0;
int ndisparities = 64;
int SADWindowSize = 11;
//SGBM
cv::Ptr<cv::StereoSGBM> sgbm = cv::StereoSGBM::create(mindisparity, ndisparities, SADWindowSize);
int P1 = 8 * left.channels() * SADWindowSize* SADWindowSize;
int P2 = 32 * left.channels() * SADWindowSize* SADWindowSize;
sgbm->setP1(P1);
sgbm->setP2(P2);
sgbm->setPreFilterCap(15);
sgbm->setUniquenessRatio(10);
sgbm->setSpeckleRange(2);
sgbm->setSpeckleWindowSize(100);
sgbm->setDisp12MaxDiff(1);
//sgbm->setMode(cv::StereoSGBM::MODE_HH);
sgbm->compute(left, right, disp);
disp.convertTo(disp, CV_32F, 1.0 / 16); //除以16得到真实视差值
Mat disp8U = Mat(disp.rows, disp.cols, CV_8UC1); //显示
normalize(disp, disp8U, 0, 255, NORM_MINMAX, CV_8UC1);
imwrite("results/SGBM.jpg", disp8U);
return 0;
}