逻辑回归是一个二分类问题
二分类问题
二分类问题是指预测的y值只有2个取值(0或1),二分类问题可以扩展到多分类问题.例如:我们要做一个垃圾邮件过滤系统,
xi是邮件的特征,预测的y值就是邮件的类别,是垃圾邮件还是正常邮件.对于类别我们通常称为正类(positive class)和负类(negative class),垃圾邮件的例子中,正类就是正常邮件,负类就是垃圾邮件
逻辑回归
Logistic函数
如果我们忽略二分类问题中y的取值是一个离散的取值(0或1),我们继续使用线性回归来预测y的取值.这样会导致y的取值并不为0或1.逻辑回归使用一个函数来归一化y值,使y的取值在(0,1)之间,这个函数称为Logistic函数(Logistic function),也称为Sigmoid函数,公式如下
g(z) =
1+e−z1
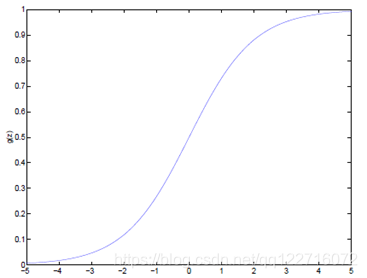
Logistic函数当z趋近于无穷大时,g(z)趋近于1;当z趋近于无穷小时,g(z)趋近于0
Logistic函数图如下:
Logistic函数求导时有一个特征
g/(z) =
dzd
1+e−z1
=
(1+e−z)21(
e−z)
=
1+e−z1(1-
(1+e−z)1)
=g(z)*(1-g(z))
逻辑回归表达式
逻辑回归本质上是线性回归,只是在特征到结果的映射中加入了一层函数映射,即先把特征线性求和,然后使用函数g(z)将最为假设函数来预测.g(z)可以将连续值映射到0和1之间.线性回归模型的表达式代入g(z),就得到逻辑回归的表达式:
hθ(x)=g(θTx)=1+e−θ1
这里为什么用
hθ(x):hyperthesis:假设
令
x0=1,
θTx=θ0+∑j=0nθjxj
逻辑回归的软分类
现在我们将y的取值
hθ(x)通过Logistic函数归一化到(0,1)间,y的取值特殊的含义,它表示结果取1的概率,因此对于输入x分类结果为类别1和类别0的概率分别为:
P(y=1∣x;θ)=hθ(x)
P(y=0∣x;θ)=1−hθ(x)
对上面的表达式合并:
P(y∣x;θ)=(hθ(x))y(1−hθ(x))1−y
解释:当y=0时,
P(y∣x;θ)=1−hθ(x).当y=1时,
P(y∣x;θ)=hθ(x)
梯度上升
得到逻辑回归的表达式,下一步和线性回归类似.构建似然函数,然后最大似然估计,最终推导出
θ的迭代更新表达式,这个请参考文章《线性回归、梯度下降》,只不过这里用的不是梯度下降,而是梯度上升,因为这里是最大化似然函数不是最小化似然函数.
似然函数表达式:
L(θ)=p(y
∣X;θ)
=
∏i=1mp(y(i)∣xi;θ)
=
∏i=1m(hθ(xi))y(i)(1−hθ(xi))1−yi
对似然函数取
log:即逻辑回归的损失函数
Ψ(θ)=logL(θ)
=
∑i=1my(i)logh(x(i))+(1−y(i))log(1−h(x(i)))
转换后的似然函数对
θ求偏导,
αθjαΨ(θ)
=
(yg(θTx)1−(1−y)1−g(θTx)1)αθjαg(θTx)
=
(yg(θTx)1−(1−y)1−g(θTx)1)g(θTx)(1−g(θTx)αθjα)θTx
=
(y(1−g(θTx))−(1−y)g(θTx))xj
=
(y−hθ(x))xj
这个求导过程第一步是对
θ偏导的转化,一句偏导公式:
y=lnx;
y/=x1
- 第二步是根据个g(z)求导的特性:
g/(z)=g(z)(1−g(z))
- 第三步就是普通的变换
这样我们就得到了梯度上升每次迭代的更新时间,那么
θ的迭代表达式为:
θj:=θj+α(y(i)−hθ(x(i)))xj(i)
这个表达式域LMS算法的表达式相比,看上去完全相同,但是梯度上升与LMS是两个不同的算法,因为
hθ(xi)表示的是关于
θTx的一个非线性函数.两个不同的算法,同一个表达式表达,这并不仅仅是巧合,两者存在深层次的联系.这个问题,我们将在广义线性模型GLM中解答