*个人学习笔记
一、基础定义
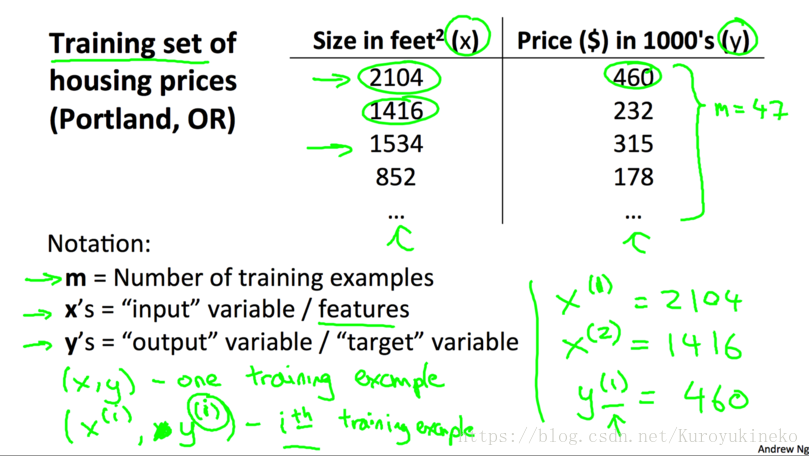
1.1 数据集符号定义
m: 样本数量
(x, y): 训练样例
(x(i), y(i)): 第i个训练样例(i ≥ 1)
1.2 假设函数
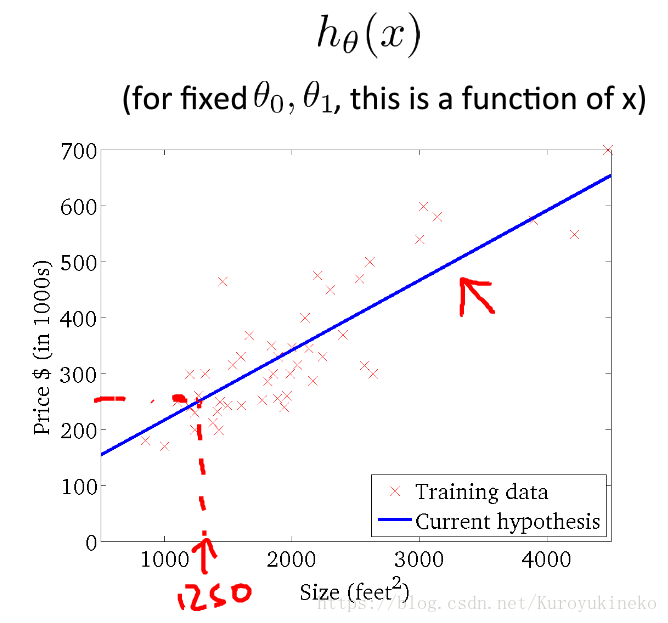
使用某种学习算法对训练集进行训练,我们可以得到假设函数(Hypothesis)。
在房价问题中,确定了假设函数,我们就可以根据平方数面积预测房价了。


hθ(x)=θ0+θ1
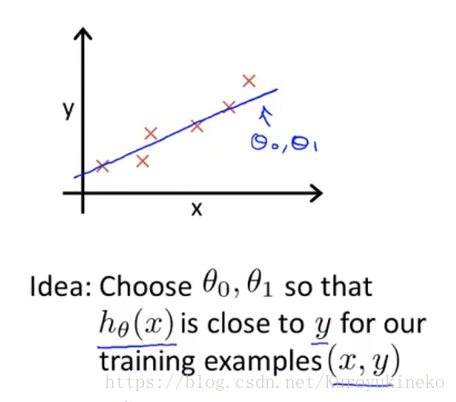
三、模型描述

上面这个模型叫做(单变量)线性回归模型【(Univariate)Linear Regression】
平方误差函数(Squared error function): J(θ0,θ1)对于回归问题来说是最常用的代价函数。
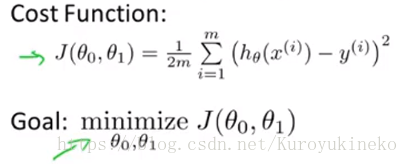
其中,hθ代表预测输出,y代表真实输出,平方项的目的是将差转换为正数,然后将其针对所有样本求和,除以m得到平均平方误差。除以2是为了方便后面的计算,没有实际的意义。
4.1 简化假设函数h帮助理解代价函数J
将假设函数简化为:hθ(x) = θ1*x(θ0 = 0),三个真实数据在 y = x 直线上,
根据不同的θ1取值可以绘制右侧的代价函数曲线(左侧为假设函数曲线),可以看到当θ1 = 1时,J取到最小值,因此θ1 = 1时假设函数最能够拟合真实的数据曲线:

4.1 进一步理解代价函数J
上一小节讲了只有θ1一个参数的简化情况,那么正常情况下拥有两个参数的J是什么样子的呢?很容易想到。
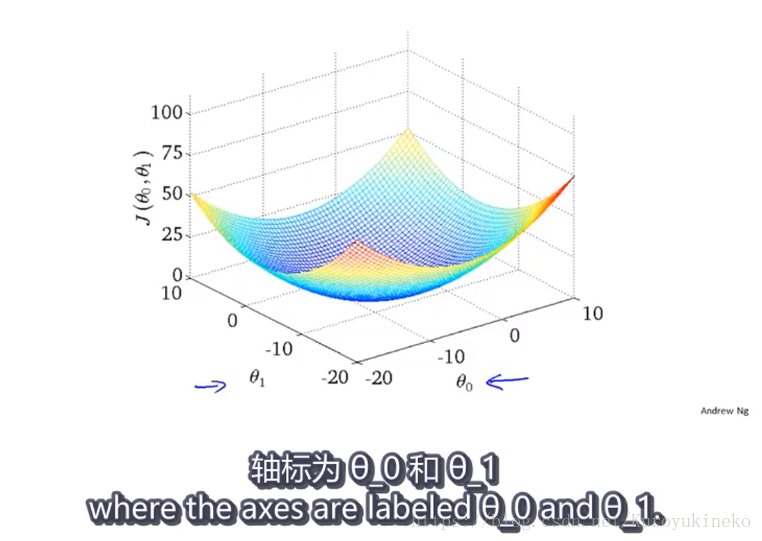
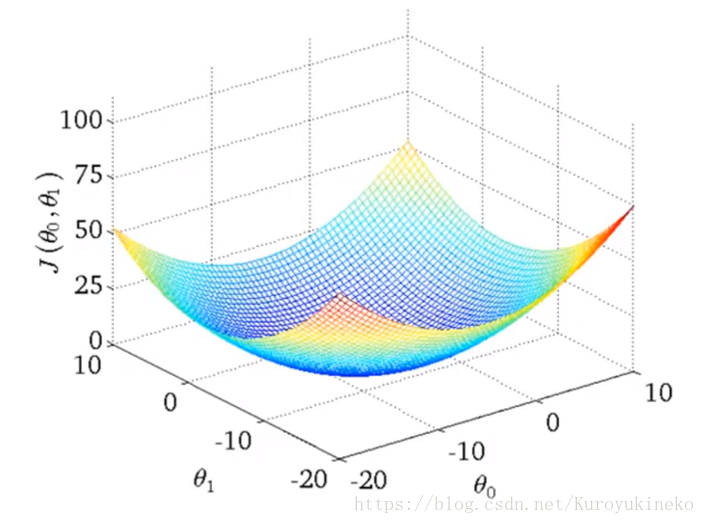
代价函数是一个3d曲面,横坐标轴分别为两个参数,曲面的高度代表代价函数J的计算值。
同样地,曲面也可以由等高图像来表示:
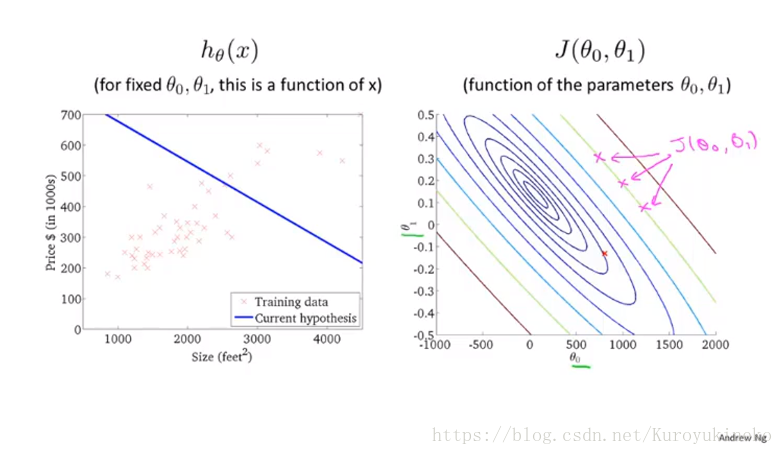
等高图像中相同颜色代表着相同的J值,如右上图中的三个玫瑰红色的叉叉。
那么我们如何通过软件来找到最小的J值呢?下面就来介绍一种算法。
四、梯度下降(Gradient Descent)
4.1 梯度下降算法概念
梯度下降算法是一种优化算法, 它可以帮助我们找到一个函数的局部极小值点。 它不仅仅可以用在线性回归模型中, 在机器学习许多其他的模型中也可以使用它。 对于我们现在研究的单变量线性回归来说, 我们想要使用梯度下降来找到最优的θ0,θ1。它的思想是, 首先随机选择两个θ0,θ1(例如, θ0=0,θ1=0), 不断地改变它们的值使得J(θ)变小, 最终找到J(θ)的最小值点。
可以把梯度下降的过程想象成下山坡, 如果想要尽可能快的下坡, 应该每次都往坡度最大的方向下山。

梯度下降算法得到的结果会受到初始状态的影响, 即当从不同的点开始时, 可能到达不同的局部极小值, 如下图:

然而线性回归模型没有这个问题,因为线性回归模型总是一个弓形图(凸函数),不存在局部最优值,只有全局最优值:
4.2 梯度下降算法过程
如下图所示, 其中:=表示赋值,α叫做学习率用来控制下降的幅度(可以理解为下山的步子,α大的话就是跨大步子下山),∂J(θ0,θ1)/∂θ叫做梯度。这里一定要注意的是,算法每次是同时(simultaneously)改变θ0和θ1的值,如图下图所示。

4.3 计算梯度代入梯度下降法
现在我们已经知道了梯度下降的公式了,但是如何求得梯度(即偏导)呢?
通过代入代价函数和假设函数计算偏导,分别求出对θ0和θ1的偏导:
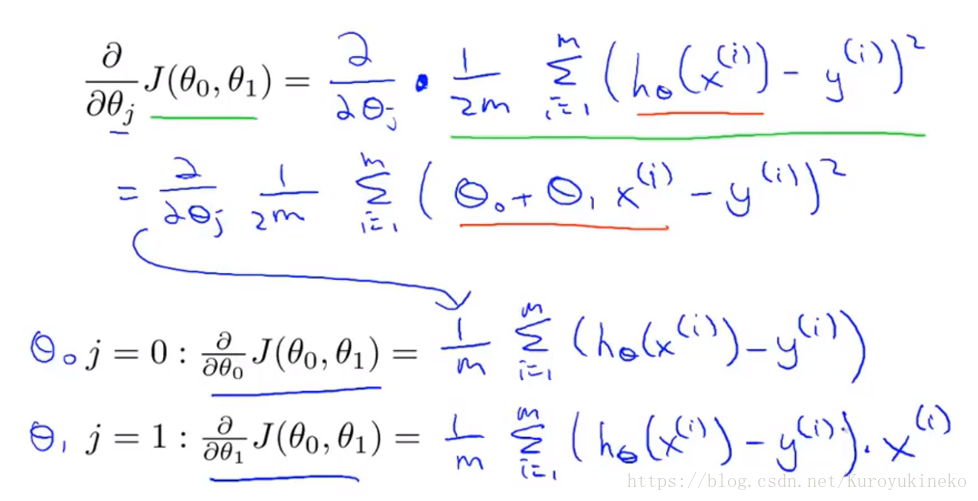
将偏导代入梯度下降法公式:

注意到,hθ(x) = θ0 + θ1x时,上面则是对线性回归模型的梯度下降算法。
此外,因为每一步我们都要对整个数据集(体现在代价函数中的∑(1~m))进行计算来得到梯度下降,所以该算法也叫做”BatchGradientDescent“。有些只运用部分子集,如minibatch之后会谈到。
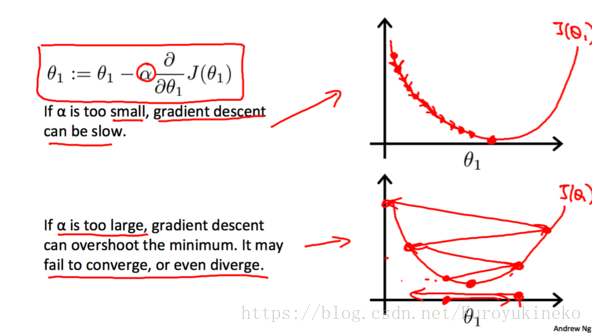
4.4 学习率α的选取
考虑单参数的情况:
学习率α会影响梯度下降的幅度。如果α太小, θ的值每次会变化的很小,那么梯度下降就会非常慢;相反地,如果α过大,θ的值每次会变化会很大,有可能直接越过最低点,可能导致永远没法到达最低点。
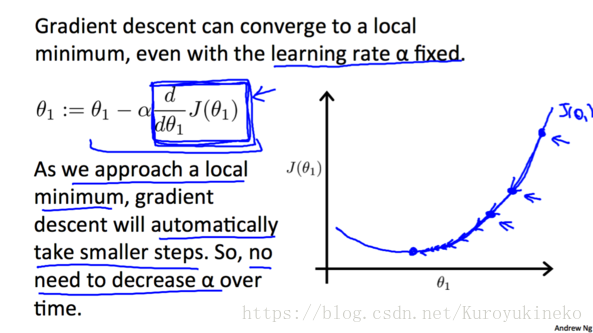
由于随着越来越接近最低点, 相应的梯度(绝对值)也会逐渐减小,所以每次下降程度就会越来越小, 我们并不需要减小α的值来减小下降程度。
那么,在这两章的学习后让我们理一下思路:
1. 我们应用一个线性回归模型来预测一个具体的数字输出值(回归问题,eg.房价预测)
构造一个假设函数:hθ(x) = θ0 + θ1·x
可以看到这是一个单变量(x)线性函数,因此这是一个单变量线性回归模型;
2. 希望得到最优的θj(j = 0, 1),我们需要构造一个代价函数:
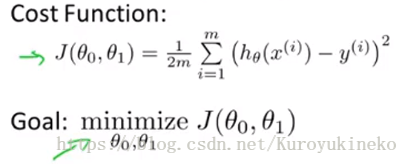
取到最小J值的θj即是我们需要的参数;
3. 为了求得参数θj,我们使用BatchGradientDescent:

4. 最终运用得到的最优参数θj,画出假设函数曲线,预测房价: