文章目录
前言
上一章我们学习了机器学习的应用领域、定义以及算法的分类,这一章来学习最简单的一个机器学习算法——单变量线性回归算法,它是一种监督学习的算法,而且输出值是连续变化的值,因此是一种“回归”算法。
一、符号定义
我们通过吴老师课堂上给出的练习题中的例子来学习单变量线性回归算法。
在进行监督学习算法的时候,我们首先要有一个训练集,这里的训练集就是人们统计的50名不同年龄的儿童和他们相应的身高,如下图所示。
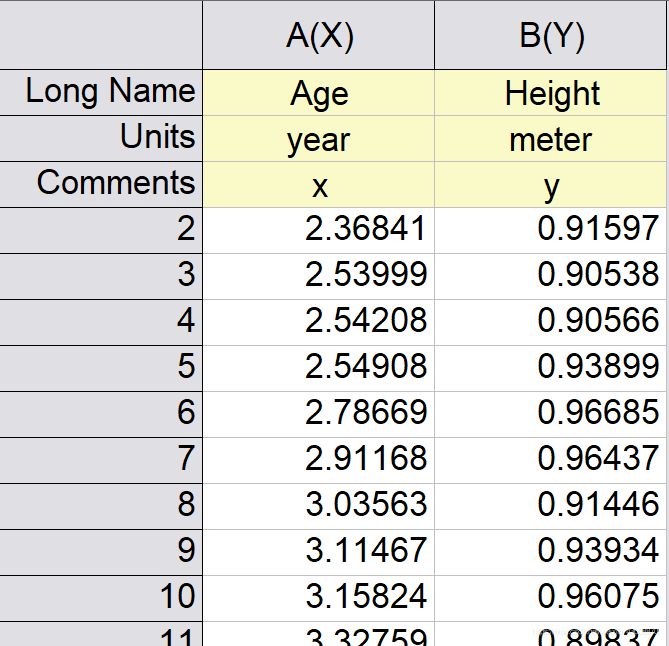
这里我们开发机器学习算法的目的就是找出身高与年龄的大致对应关系,从而可以预测特定年龄小孩的大致身高。
因此,这个训练集中,我们的输入值是年龄,输出值是身高。通常来讲,我们将输入值定义为
,输出值定义为
,这里的
就是小孩的年龄了,因为只有这么一个输入变量,因此这个问题是一个单变量的问题。我们用
表示训练样本的数量,在本例中,
就是小孩的数量,也就是
。我们用符号(
,
)表示第
个小孩的年龄和身高,
。
接下来,为了找出x和y之间的关系,我们把x和y画成散点图,如下所示
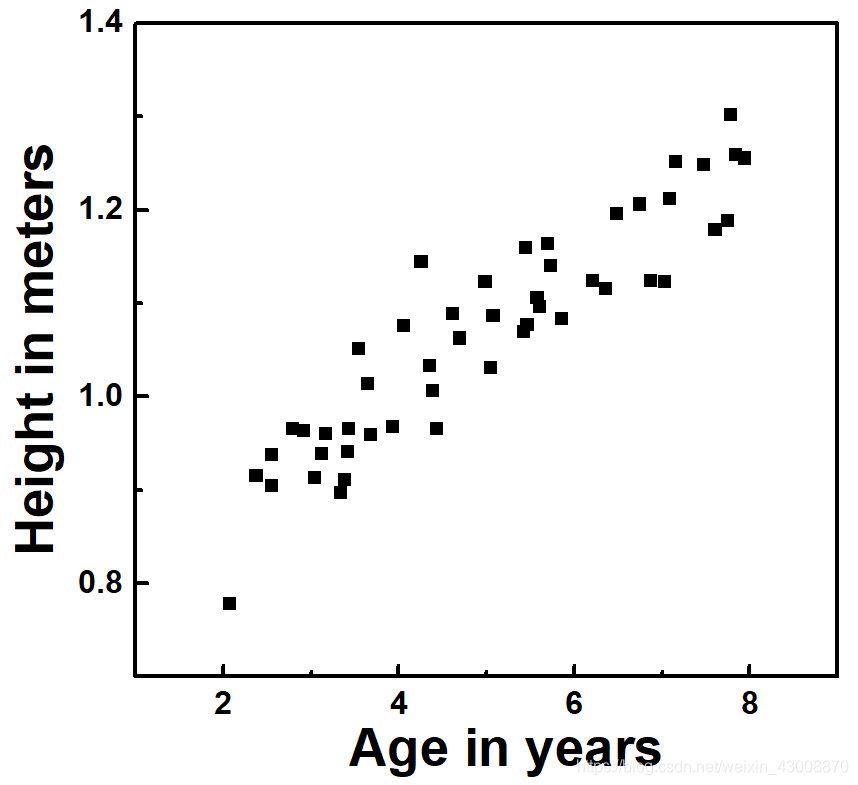
从数据点的分布可以看出,身高和年龄之间大致呈线性关系,因此假设身高与年龄之间的函数关系是一个线性函数。这个假设函数(hypothesis)我们将其命名为
,即
,机器学习算法的目的就是找出
的具体表达式。在本例中,我们认为假设函数是一条直线,于是有
,这样,我们的目标就转化为寻找最优的
和
。等学习了后面的内容后,我们就会发现,监督学习算法的最终目的通常就是寻找最优参数。
接下来,为了让我们的表达方法更具有普适性和简洁性,我们把变量都用向量的方式来表示。我们定义函数
的参数为向量
,同时,我们将
也写成向量的形式,为了让
和
对应起来,我们给每一个样本的
增加一个常数1,变成一个
的矩阵:
,
的向量表示形式就是
。这样一来我们的整个训练集就可以用向量表示为
,这里的
是向量的乘积,我们也可以省略这个乘号,写成
。这种表达方式对后面的多变量回归乃至逻辑回归都是适用的,同时也可以方便地转化为Matlab代码。
至此,我们就完成了单变量线性回归的准备工作了,下面开始考虑如何寻找最优的参数
。
二、代价函数
为了寻找最优的参数
,我们首先要确定一个标准,即什么样的参数是“优”的。直观地理解,对于每一个样本,我们的函数值
与实际的输出值
符合得越好,我们认为对应的参数越“好”。我们可以使用方差
来定量地描述这两个值的符合程度,方差越大,说明这两个值的差异越大,方差为零时这两个值完全相同。
综合考虑所有的样本,我们可以定义这样一个函数
来表征函数
与样本集整体的符合程度,
越小,符合程度越高。从函数
的定义可以看出它的大小只与参数
有关,即
,我们称
为函数
的代价函数。这样一来,我们的目标就再一次转化为寻找使代价函数值
最小的参数
。
三、梯度下降算法
那么,如何寻找
最小时的参数
呢?这就要用到梯度下降算法了。
梯度下降算法的思想很简单,
实际上是一个关于
的二维曲面,每一对
都对应于曲面上的一个点,如下图所示。

我们先任意初始化一个
值,然后找出该点处的
下降最快的方向,然后将
向这个方向移动一小步,然后再重新寻找
下降最快的方向,再向新的方向移动一小步,如此循环,直到
达到最小值。而函数
的梯度就代表着它在任意一点
处的下降方向和下降速度。
根据函数梯度的定义,
,其中,
和
分别代表沿
和
正方向的单位向量,为了使
往
下降最快的方向移动,应该使
和
分别加
和
,其中
(>0)代表移动的步长。于是,梯度下降算法的计算过程如下所示:
Step1、初始化
:例如令
;
Step2、计算当前
值对应的
的梯度:
,
的值;
Step3、更新
:
;
;
Step4、判断是否结束循环,若为否则回到Step2。
当
离最小值较远时,对应的梯度值较大,
移动的较快;
越接近最小值,
移动步长越小,最终逐渐收敛到
最小处。
而第二步中偏导数
,
的值可以将
代入
中计算得出。根据偏导数的运算规则,可以得出:
;
,实际执行时,会在前面乘上一个系数
,并不会影响最终的优化结果。
四、Matlab算法实现
%导入训练集;
x=load('ex2x.dat');
y=load('ex2y.dat');
%画出训练集的散点图
figure,
subplot(121),
plot(x,y,'o');
ylabel('Height in meters');
xlabel('Age in years');
hold on;
%step1、初始化相关参数
m=length(y);
x=[ones(m,1),x];
n=2;
theta=zeros(n,1);
alpha=0.07;
%开始单变量梯度下降循环,并实时显示J的变化
subplot(122);
for step=1:800
%先计算h-y的值,h-y是一个m×1的向量
h_y=x*theta-y;
%step2、3 计算梯度并更新θ的值,通过向量乘法实现样本的求和。
theta(1)=theta(1)-alpha/m*(h_y'*x(:,1));
theta(2)=theta(2)-alpha/m*(h_y'*x(:,2));
%计算并显示代价函数值
J=sum(h_y.^2)/m/2;
if mod(step,10)==9
plot(step,log10(J),'o');
axis([0,800,-inf,inf]);
ylabel('log(J)');
xlabel('Step');
hold on;
drawnow;
end
end
%准备数据,画出代价函数曲面
subplot(121),
tempx=linspace(2,8,100);
tempy=theta(1)+tempx*theta(2);
Jval=zeros(100,100);
theta0=linspace(-3,3,100);
theta1=linspace(-1,1,100);
for xs=1:length(theta0)
for ys=1:length(theta1)
theta=[theta0(xs);theta1(ys)];
h_y=x*theta-y;
Jval(xs,ys)=sum(h_y.^2)/m/2;
end
end
figure,
surf(theta0,theta1,Jval');
axis([-3,3,-1,1]);
xlabel('\theta_0'); ylabel('\theta_1')
数据和代码可以在这里下载,提取码m806