一.原理
K-近邻算法采用测量不同特征值之间的距离方法进行分类。存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据 与所属分类的对应关系。输人没有标签的新数据后,将新数据的每个特征与样本集中数据对应的 特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们 只选择样本数据集中前K个最相似的数据,这就是K-近邻算法中K的出处,通常K是不大于20的整数。 最后 ,选择K个最相似数据中出现次数最多的分类,作为新数据的分类。
(2)几何原理
欧氏距离(欧几里得距离)是最常见的距离度量,衡量的是多维空间中各个点之间的绝对距离。
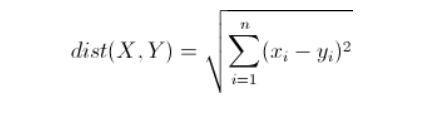
举例:
#一维空间
#x1 = 1 x2 = 9
#8
(1- 9)^2 整体的开平方
#二维空间
两个点的距离
x(1,3) y(4,3)
(1-4)^2 + (3-3)^2 整体的开平方
#三维空间
x(1,2,3) y(4,5,6)
(1-4)^2 + (2-5)^2 + (3-6)^2 整体开平方
#封装的是欧式距离
(3)优缺点
优点:精度高、对异常值不敏感、无数据输入假定。
缺点:时间复杂度高、空间复杂度高。
适用数据范围:数值型和标称型。
二.在scikit-learn库中使用k-近邻算法
导包
分类问题:from sklearn.neighbors import KNeighborsClassifier
回归问题:from sklearn.neighbors import KNeighborsRegressor
注:sklearn:google夏令营的产品
举例:
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
#训练样本集
#提高准确率,多加点属性 头发的长短,心率,体温, 血压,血糖,荷尔蒙
X_train = np.array([[175,60,43],
[160,48,36],
[226,120,49],
[155,43,35],
[180,78,44]])
labels = ["男","女","男","女","男"]
knn = KNeighborsClassifier()
#训练数据
knn.fit(X_train, labels)
#测试数据
x_test = np.array([[171,65,40]])
#开始进行预测
knn.predict(x_test)
1.用于分类
导包,机器学习的算法KNN、数据蓝蝴蝶
#鸢尾花, 系统给咱们提供了一部分训练样本(数据集datasets)
import sklearn.datasets as datasets
#数据随机打乱并拆分
from sklearn.model_selection import train_test_split
iris_data = datasets.load_iris()
iris_data
#从字典里面拿出来数据
data = iris_data.data
data.shape
#目标值:这里标签叫目标值
target = iris_data.target
target.shape
#拆分包, 会把datab 按照比例0.1 拆分成 X_train ,X_test data 150个数据
#X_train (训练样本集) 135个 X_test (测试数据)15个
#会把target 按照比例0.1 拆分成 y_train 135, y_test 15
X_train,X_test,y_train,y_test = train_test_split(data, target, test_size = 0.1)
X_train.shape
X_test.shape
y_train.shape
#目标值
fit(X_train, y_train)
#真实的值
y_test
#声明算法,开始进行训练
knn = KNeighborsClassifier()
knn.fit(X_train,y_train)
#进行预测
y_= knn.predict(X_test)
y_
#看得分:score函数 传参必须传 测试数据和真实的目标值
#测试数据的得分
knn.score(X_test, y_test)
#模型的得分
knn.score(X_train,y_train)
2.用于回归
回归用于对趋势的预测
导包
生成样本数据
生成测试数据的结果
