1 KNN的介绍和应用
1.1 KNN的介绍
kNN(k-nearest neighbors),中文翻译K近邻。我们常常听到一个故事:如果要了解一个人的经济水平,只需要知道他最好的5个朋友的经济能力, 对他的这五个人的经济水平求平均就是这个人的经济水平。这句话里面就包含着kNN的算法思想。
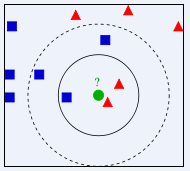
示例 :如上图,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
1) KNN建立过程
1 给定测试样本,计算它与训练集中的每一个样本的距离。
2 找出距离近期的K个训练样本。作为测试样本的近邻。
3 依据这K个近邻归属的类别来确定样本的类别。
2) 类别的判定
①投票决定,少数服从多数。取类别最多的为测试样本类别。
②加权投票法,依据计算得出距离的远近,对近邻的投票进行加权,距离越近则权重越大,设定权重为距离平方的倒数。
1.2 KNN的应用
KNN虽然很简单,但是人们常说"大道至简",一句"物以类聚,人以群分"就能揭开其面纱,看似简单的KNN即能做分类又能做回归, 还能用来做数据预处理的缺失值填充。由于KNN模型具有很好的解释性,一般情况下对于简单的机器学习问题,我们可以使用KNN作为 Baseline,对于每一个预测结果,我们可以很好的进行解释。推荐系统的中,也有着KNN的影子。例如文章推荐系统中, 对于一个用户A,我们可以把和A最相近的k个用户,浏览过的文章推送给A。
机器学习领域中,数据往往很重要,有句话叫做:"数据决定任务的上限, 模型的目标是无限接近这个上限"。 可以看到好的数据非常重要,但是由于各种原因,我们得到的数据是有缺失的,如果我们能够很好的填充这些缺失值, 就能够得到更好的数据,以至于训练出来更鲁棒的模型。接下来我们就来看看KNN如果做分类,怎么做回归以及怎么填充空值。