一、概念
KNN主要用来解决分类问题,是监督分类算法,它通过判断最近K个点的类别来决定自身类别,所以K值对结果影响很大,虽然它实现比较简单,但在目标数据集比例分配不平衡时,会造成结果的不准确。而且KNN对资源开销较大。
二、计算
通过K近邻进行计算,需要:
1、加载打标好的数据集,然后设定一个K值;
2、计算预测对象与打标对象的欧式距离,
欧氏距离是最易于理解的一种距离计算方法,源自欧氏空间中两点间的距离公式:
二维平面上两点a(x1,y1)与b(x2,y2)间的欧氏距离:
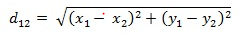
三维空间两点a(x1,y1,z1)与b(x2,y2,z2)间的欧氏距离:

两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的欧氏距离:
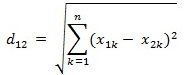
然后将计算的结果进行排序选取前K个组成决策集合,然后在其中选取最多的作为预测对象类别
三、实现
#!/usr/bin/env python # -*- coding: utf-8 -*- import numpy import os file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'test_file/k_means_data.txt') iris = [] with open(file_path, 'r') as fp: for line in fp.readlines(): iris.append(list(map(float, line.split()))) iris = numpy.mat(iris) # arr[i, :] #取第i行数据 # arr[i:j, :] #取第i行到第j行的数据 # in:arr[:,0] # 取第0列的数据,以行的形式返回的 # in:arr[:,:1] # 取第0列的数据,以列的形式返回的 def k_mean(data_set, k): shape = numpy.shape(data_set) # 获取维度 print(shape) m, n = shape[0], shape[1] # 行数,列数 cluster_assignment = numpy.mat(numpy.zeros((m, 2))) # 转换为矩阵, zeros生成指定维数的全0数组 centroids = numpy.mat(numpy.zeros((k, n))) for index in range(k): # 随机生成中心点, numpy.random.rand(Random values in a given shape) centroids[:, index] = numpy.mat(5 + 5 * numpy.random.rand(k, 1)) cluster_changed = True while cluster_changed: cluster_changed = False for i in range(m): min_distance = numpy.inf # 无限大的正数 min_index = -1 vec_b = numpy.array(data_set)[i, :] # i行数据,数据集内的点的位置 for j in range(k): vec_a = numpy.array(centroids)[j, :] # j行数据, 中心点位置 distance = numpy.sqrt(sum(numpy.power(vec_a - vec_b, 2))) # power(x1, x2) 对x1中的每个元素求x2次方。不会改变x1上午shape。 if distance < min_distance: min_distance = distance min_index = j if cluster_assignment[i, 0] != min_index: cluster_changed = True cluster_assignment[i, :] = min_index, min_distance ** 2 for cent in range(k): # numpy.nonzero取出矩阵中非0的元素坐标 pts_in_cluster = data_set[numpy.nonzero(numpy.array(cluster_assignment)[:, 0] == cent)] # print(pts_in_cluster) # mean() 函数功能:求取均值 # 经常操作的参数为axis,以m * n矩阵举例: # axis : 不设置值, m * n 个数求均值,返回一个实数 # axis = 0:压缩行,对各列求均值,返回1 * n矩阵 # axis = 1 :压缩列,对各行求均值,返回m * 1矩阵 if len(pts_in_cluster) > 0: centroids[cent, :] = numpy.mean(pts_in_cluster, axis=0) for cent in range(k): ret_id = numpy.nonzero(numpy.array(cluster_assignment)[:, 0] == cent) print(ret_id) k_mean(iris, 3)