1、k近邻算法
k近邻学习是一种常见的监督学习方法,其工作机制非常简单:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这K个"邻居"的信息来进行预测。
通常,在分类任务中可使用"投票法",即选择这K个样本中出现最多的类别标记作为预测结果;在回归任务中可使用"平均法”,即将这K个样本的实际值输出标记的平均值作为预测结果,还可以基于距离远近进行加权平均或加权投票。距离越近的样本权重越大。
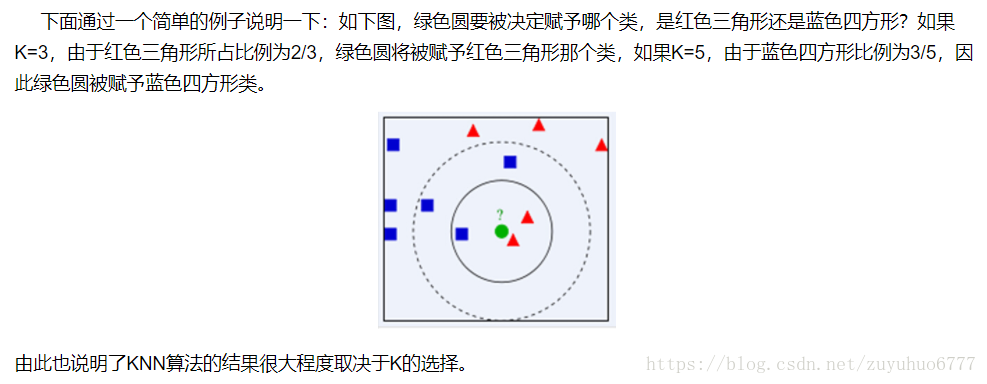

同时,KNN通过依据k个对象中占优的类别进行决策,而不是单一的对象类别决策。这两点就是KNN算法的优势。
接下来对KNN算法的思想总结一下:就是在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为:
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
二、python 实现
from __future__ import print_function
from sklearn import datasets
from sklearn.cross_validation import train_test_split
from sklearn.neighbors import KNeighborsClassifier
iris = datasets.load_iris()
iris_X = iris.data
iris_y = iris.target
#print(iris_X[:2, :])
#print(iris_y)
X_train, X_test, y_train, y_test = train_test_split(
iris_X, iris_y, test_size=0.3)
knn = KNeighborsClassifier()
knn.fit(X_train, y_train) #训练
#print(knn.predict(X_test))
#print(y_test)
a=knn.score(X_test,y_test)
print(a)
运行结果是:a=0.9777
3、KNN算法中超参数的搜索
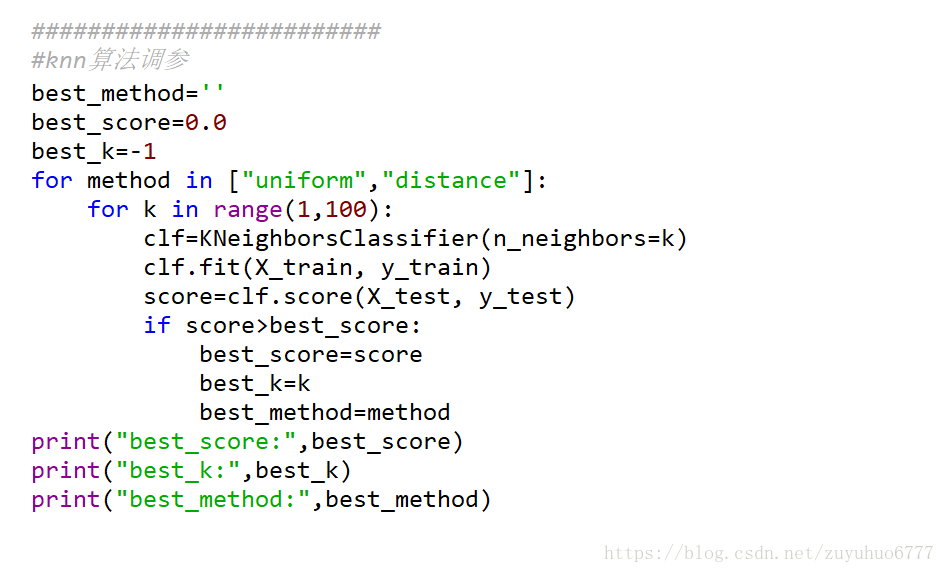
补充1:
为了进一步理解knn算法的本质,用python 将其实现了一下,而不仅仅是在sklearn包中调用
from sklearn.neighbors import KNeighborsClassifer
knn=KNeighborsClassifer来实现。
Python代码如下,且有解释:
from numpy import *
import operator
def createDataSet():
group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels=['A','A','B','B']
return group,labels
#from sklearn.neighbors import KNeighborsClassifer
#knn=KNeighborsClassifer
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]#行
diffMat = tile(inX, (dataSetSize,1)) - dataSet#dataSetSize*1
sqDiffMat = diffMat**2#平方
sqDistances = sqDiffMat.sum(axis=1)#x轴方向求和
distances = sqDistances**0.5#开根号
sortedDistIndicies = distances.argsort()#从小到大排序,返回索引值
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#返回指定键值,none返回0,value为出现的个数
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
#dict.items() :以列表返回可遍历的(键、值)元组数组
#key=operator.itemgetter(1) 以第二个数字排序
#reverse=True 相反的方向
return sortedClassCount[0][0]
之后再输入:
group,labels=createDataSet();
print(classify0([0,0],group,labels,3))
预测成功,完成分类
有问题,欢迎留言,一起讨论。