前言
近邻学习是一种常用的监督学习方法。
近邻法的输入为实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类。
近邻法的工作机制很简单:给定测试样本,基于某种距离度量(关于距离度量可以点击此处)找出训练集中与其最靠近的 个训练样本,然后基于这 个“邻居”的信息来进行预测。
分类时,对新的实例,根据其 个最邻近的训练实例的类别(通过距离度量求得),通过多数表决等方式进行预测,也即“投票法”(选择着 个样本中出现次数最多的类别标记作为预测结果)。因此, 近邻法不具有显示的学习过程,事实上,它是“懒惰学习”的著名代表。
近邻法实际上利用训练数据集对特征空间进行划分,并作为其分类的“模型”; 值的选择、距离度量及分类决策规则是 近邻法的三个基本要素。
近邻算法
输入:训练数据集 ,其中, 为实例的特征向量, 为实例的类别, ;实例特征向量 ;
输出:实例 所属的类的 。
(1)根据给定的距离度量,在训练数据集
中找出与
最邻近的
个点,涵盖这
个点的
的领域记作
;
(2)在
中根据分类决策规则(如多数表决)决定
的类别
:
其中, 为指示函数,即当 时 为1,否则为0
k邻近法的特殊情况是 的情形,称为最近邻算法;对于输入的实例点(特征向量 ),最近邻法将训练数据集中与 最邻近的点的类作为 的类。
近邻模型
近邻法中,当训练集、距离度量、 值以及分类决策规则确定后,对于任何一个新的输入实例,它所属的类唯一地确定。这相当于根据上诉要素将特征空间划分为一些子空间,确定子空间里的每个点的属性的类。
下面我们来看看 近邻分类器的一个示意图。
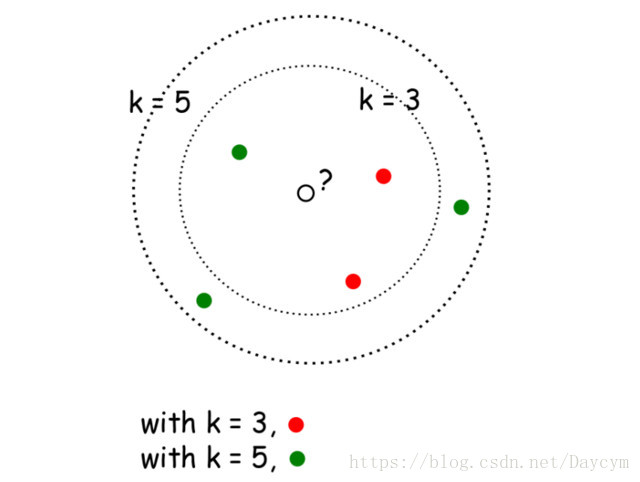
图中可以看出,当 时,根据多数表决规则,则分类结果为红点;当 时,则分类结果为绿色。显然, 是一个重要的参数,当 的取不同值时,分类结果会有显著不同。另一方面,如采用不同的距离度量方式,则找出的“近邻”也可能会有显著差别,从而导致不同的分类结果。
注:对于距离度量、 值选择以及分类决策规则,下篇博客中更新。
参考文献 :李航《统计学习分析》、图灵书籍《机器学习实战》