大数据技术之机器学习K 近邻(k-nearest neighbors)算法
1、KNN的介绍和应用
1.1 knn的介绍
kNN(k-nearest neighbors),中文翻译K近邻。我们常常听到一个故事:如果要了解一个人的经济水平,只需要知道他最好的5个朋友的经济能力, 对他的这五个人的经济水平求平均就是这个人的经济水平。这句话里面就包含着kNN的算法思想。
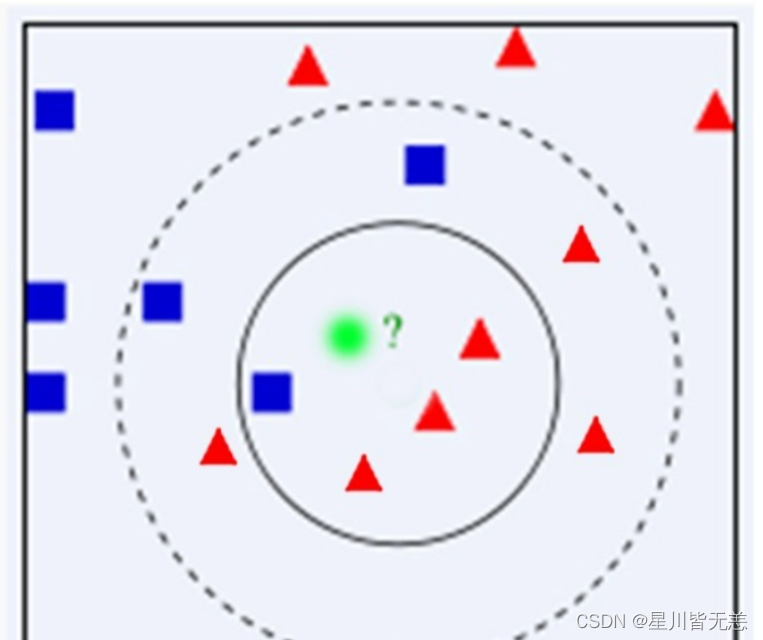
示例 :如上图,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
(1) KNN建立过程
1 给定测试样本,计算它与训练集中的每一个样本的距离。
2 找出距离近期的K个训练样本。作为测试样本的近邻。
3 依据这K个近邻归属的类别来确定样本的类别。
(2) 类别的判定
①投票决定,少数服从多数。取类别最多的为测试样本类别。
②加权投票法,依据计算得出距离的远近,对近邻的投票进行加权,距离越近则权重越大,设定权重为距离平方的倒数。
1.2 KNN的应用
KNN虽然很简单,但是人们常说"大道至简",一句"物以类聚,人以群分"就能揭开其面纱,看似简单的KNN即能做分类又能做回归, 还能用来做数据预处理的缺失值填充。由于KNN模型具有很好的解释性,一般情况下对于简单的机器学习问题,我们可以使用KNN作为 Baseline,对于每一个预测结果,我们可以很好的进行解释。推荐系统的中,也有着KNN的影子。例如文章推荐系统中, 对于一个用户A,我们可以把和A最相近的k个用户,浏览过的文章推送给A。
机器学习领域中,数据往往很重要,有句话叫做:“数据决定任务的上限, 模型的目标是无限接近这个上限”。 可以看到好的数据非常重要,但是由于各种原因,我们得到的数据是有缺失的,如果我们能够很好的填充这些缺失值, 就能够得到更好的数据,以至于训练出来更鲁棒的模型。接下来我们就来看看KNN如果做分类,怎么做回归以及怎么填充空值。
2、knn原理介绍
k近邻方法是一种惰性学习算法,可以用于回归和分类,它的主要思想是投票机制,对于一个测试实例x, 我们在有标签的训练数据集上找到和最相近的k个数据,用他们的label进行投票,分类问题则进行表决投票,回归问题使用加权平均或者直接平均的方法。knn算法中我们最需要关注两个问题:k值的选择和距离的计算。 kNN中的k是一个超参数,需要我们进行指定,一般情况下这个k和数据有很大关系,都是交叉验证进行选择,但是建议使用交叉验证的时候,k∈[2,20],使用交叉验证得到一个很好的k值。
k值还可以表示我们的模型复杂度,当k值越小意味着模型复杂度表达,更容易过拟合,(用极少树的样例来绝对这个预测的结果,很容易产生偏见,这就是过拟合)。我们有这样一句话,k值越多学习的估计误差越小,但是学习的近似误差就会增大。
接下来我们通过一个简单的实例来学习一下knn算法:
knn算法的基本步骤:
1、先载入iris数据集 Load Iris data
2、分离训练集和设置测试集split train and test sets
3、对数据进行标准化处理Normalize the data
4、使用knn模型进行训练Train using KNN
5、然后进行可视化处理Visualization
6、最后通过绘图决策平面plot decision plane
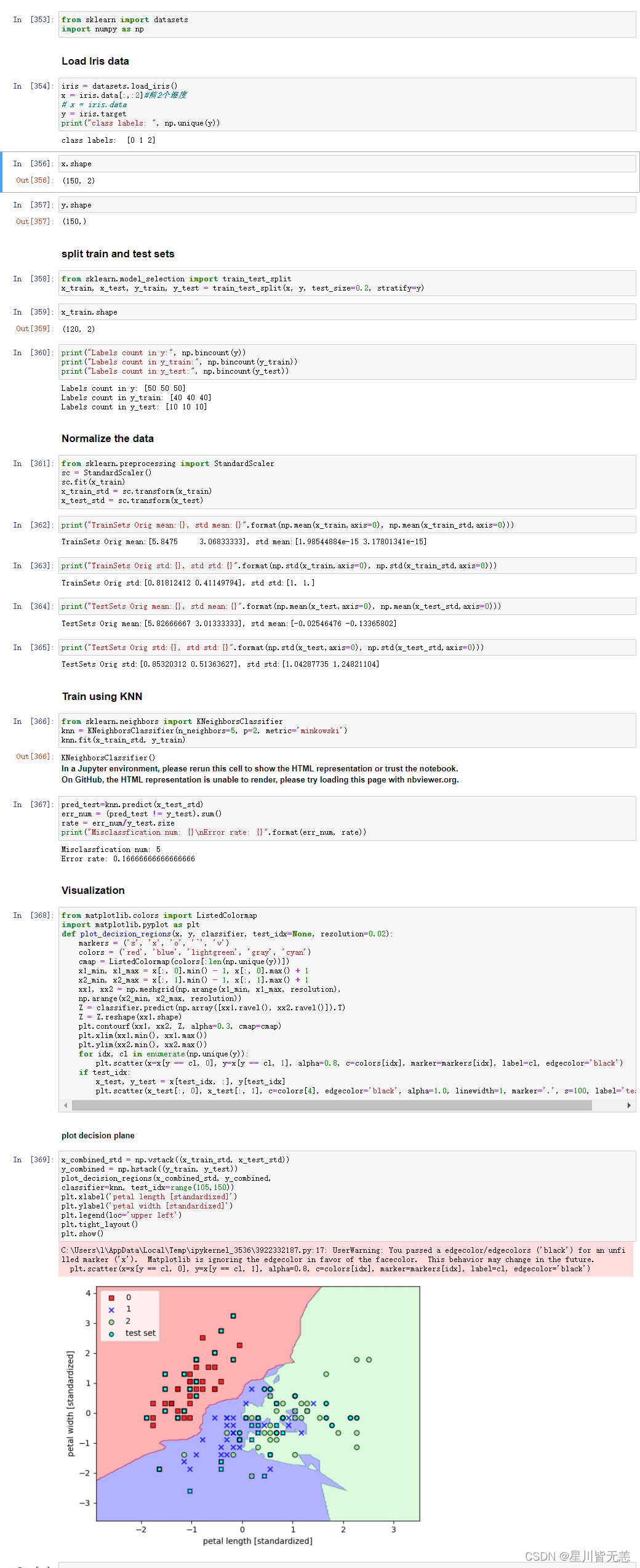
通过knn算法对iris数据集前两个维度的数据进行模型训练并求出错误率,最后进行可视化展示数据区域划分:
from sklearn import datasets
import numpy as np
### Load Iris data
iris = datasets.load_iris()
x = iris.data[:,:2]#前2个维度
# x = iris.data
y = iris.target
print("class labels: ", np.unique(y))
x.shape
y.shape
### split train and test sets
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, stratify=y)
x_train.shape
print("Labels count in y:", np.bincount(y))
print("Labels count in y_train:", np.bincount(y_train))
print("Labels count in y_test:", np.bincount(y_test))
### Normalize the data
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit(x_train)
x_train_std = sc.transform(x_train)
x_test_std = sc.transform(x_test)
print("TrainSets Orig mean:{}, std mean:{}".format(np.mean(x_train,axis=0), np.mean(x_train_std,axis=0)))
print("TrainSets Orig std:{}, std std:{}".format(np.std(x_train,axis=0), np.std(x_train_std,axis=0)))
print("TestSets Orig mean:{}, std mean:{}".format(np.mean(x_test,axis=0), np.mean(x_test_std,axis=0)))
print("TestSets Orig std:{}, std std:{}".format(np.std(x_test,axis=0), np.std(x_test_std,axis=0)))
### Train using KNN
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5, p=2, metric='minkowski')
knn.fit(x_train_std, y_train)
pred_test=knn.predict(x_test_std)
err_num = (pred_test != y_test).sum()
rate = err_num/y_test.size
print("Misclassfication num: {}\nError rate: {}".format(err_num, rate))#计算错误率
### Visualization
x_combined_std = np.vstack((x_train_std, x_test_std))
y_combined = np.hstack((y_train, y_test))
plot_decision_regions(x_combined_std, y_combined,
classifier=knn, test_idx=range(105,150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
plt.show()
#### plot decision plane
x_combined_std = np.vstack((x_train_std, x_test_std))
y_combined = np.hstack((y_train, y_test))
plot_decision_regions(x_combined_std, y_combined,
classifier=knn, test_idx=range(105,150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
plt.show()
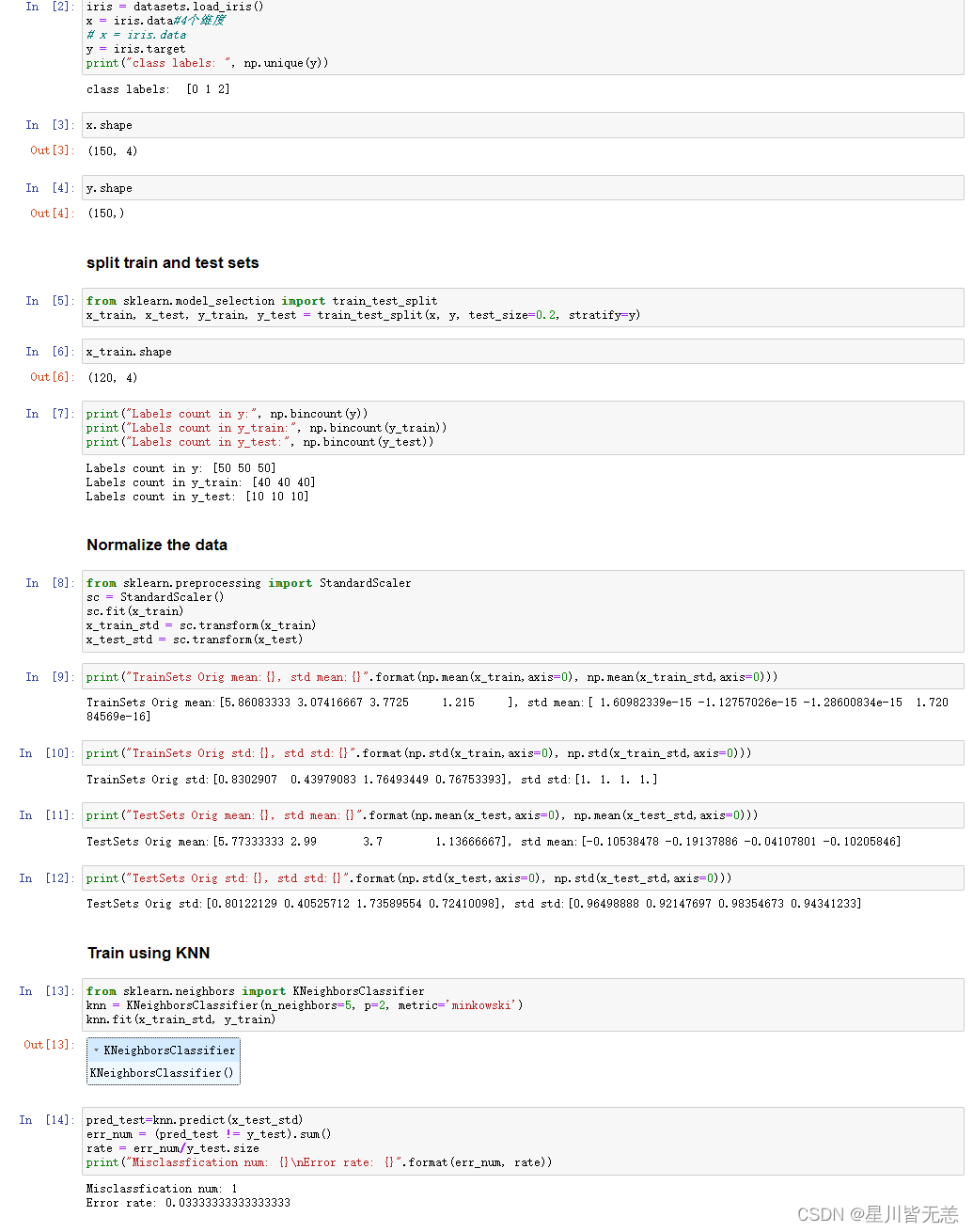
然后我们再通过knn算法对iris数据集总共四个维度的数据进行模型训练并求出错误率:
from sklearn import datasets
import numpy as np
iris = datasets.load_iris()
x = iris.data #4个维度
# x = iris.data
y = iris.target
print("class labels: ", np.unique(y))
x.shape
y.shape
### split train and test sets
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, stratify=y)
x_train.shape
print("Labels count in y:", np.bincount(y))
print("Labels count in y_train:", np.bincount(y_train))
print("Labels count in y_test:", np.bincount(y_test))
### Normalize the data
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit(x_train)
x_train_std = sc.transform(x_train)
x_test_std = sc.transform(x_test)
print("TrainSets Orig mean:{}, std mean:{}".format(np.mean(x_train,axis=0), np.mean(x_train_std,axis=0)))
print("TrainSets Orig std:{}, std std:{}".format(np.std(x_train,axis=0), np.std(x_train_std,axis=0)))
print("TestSets Orig mean:{}, std mean:{}".format(np.mean(x_test,axis=0), np.mean(x_test_std,axis=0)))
print("TestSets Orig std:{}, std std:{}".format(np.std(x_test,axis=0), np.std(x_test_std,axis=0)))
### Train using KNN
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5, p=2, metric='minkowski')
knn.fit(x_train_std, y_train)
pred_test=knn.predict(x_test_std)
err_num = (pred_test != y_test).sum()
rate = err_num/y_test.size
print("Misclassfication num: {}\nError rate: {}".format(err_num, rate))#计算错误率
距离/相似度的计算:
样本之间的距离的计算,我们一般使用对于一般使用Lp距离进行计算。当p=1时候,称为曼哈顿距离(Manhattan distance),当p=2时候,称为欧氏距离(Euclidean distance),当p=∞时候,称为极大距离(infty distance), 表示各个坐标的距离最大值,另外也包含夹角余弦等方法。
一般采用欧式距离较多,但是文本分类则倾向于使用余弦来计算相似度。
对于两个向量( , )
,一般使用 距离进行计算。 假设特征空间 是n维实数向量空间 , 其中, , ∈ , =( (1) , (2) ,…, ( ) ), =( (1) , (2) ,…, ( ) ) , 的 距离定义为:
( , )=(∑ =1 ||| ( ) − ( ) ||| )1
这里的 ≥1
. 当 =2时候,称为欧氏距离(Euclidean distance):
2( , )=(∑ =1 ||| ( ) − ( ) |||2)12
当 =1
时候,称为曼哈顿距离(Manhattan distance):
1( , )=∑ =1 ||| ( ) − ( ) |||
当 =∞时候,称为极大距离(infty distance), 表示各个坐标的距离最大值:
( , )=max ||| ( ) − ( ) |||
看似简单的KNN即能做分类又能做回归, 还能用来做数据预处理的缺失值填充。由于KNN模型具有很好的解释性,一般情况下对于简单的机器学习问题,我们可以使用KNN作为 Baseline,对于每一个预测结果,我们可以很好的进行解释。