No.1. k-近邻算法的特点

No.2. 准备工作,导入类库,准备测试数据

No.3. 构建训练集

No.4. 简单查看一下训练数据集大概是什么样子,借助散点图
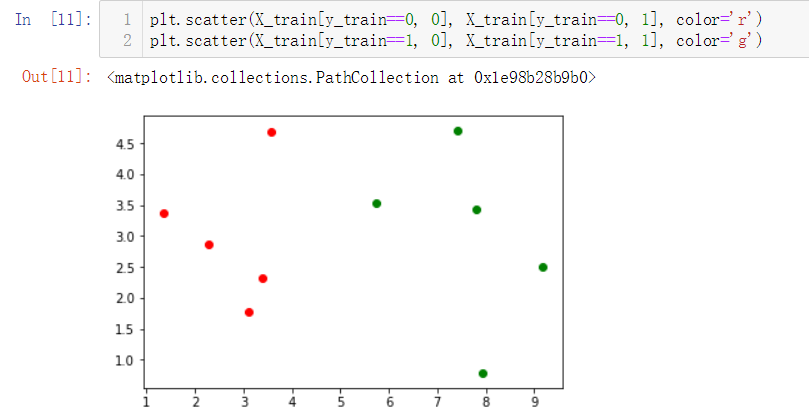
No.5. kNN算法的目的是,假如有新的数据加入,需要判断这个新的数据属于数据集中的哪一类
我们添加一个新的数据,重新绘制散点图

No.6. kNN的实现过程——计算x到训练数据集中每个点的距离
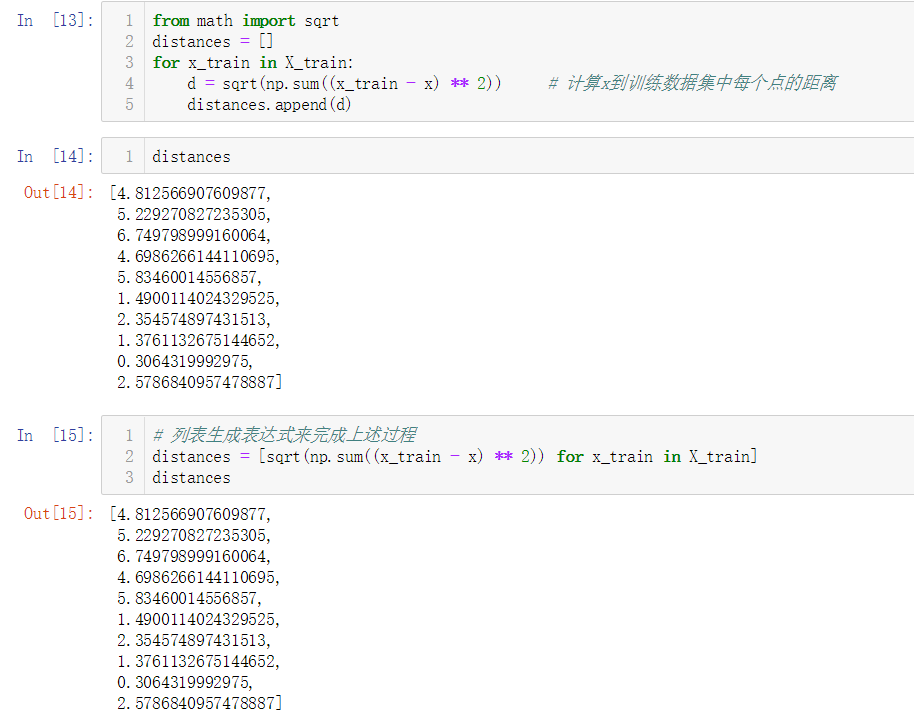
No.7. kNN的实现过程——使用argsort来获取距离x由近到远的点的索引组成的向量,进行保存

No.8. kNN的实现过程——指定需要考虑的最近的点的个数k,并获取距离x最近的k个点的y_train中的数据

No.9. kNN的实现过程——统计出属于不同类别的点的个数,并选择票数最多的类别
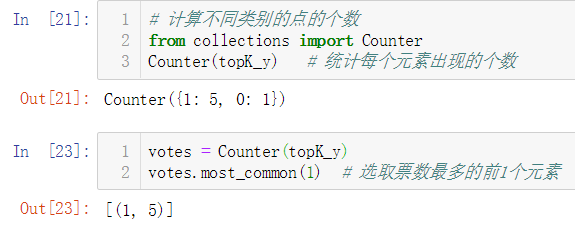
No.10. kNN的实现过程——对预测结果进行保存,结束。
