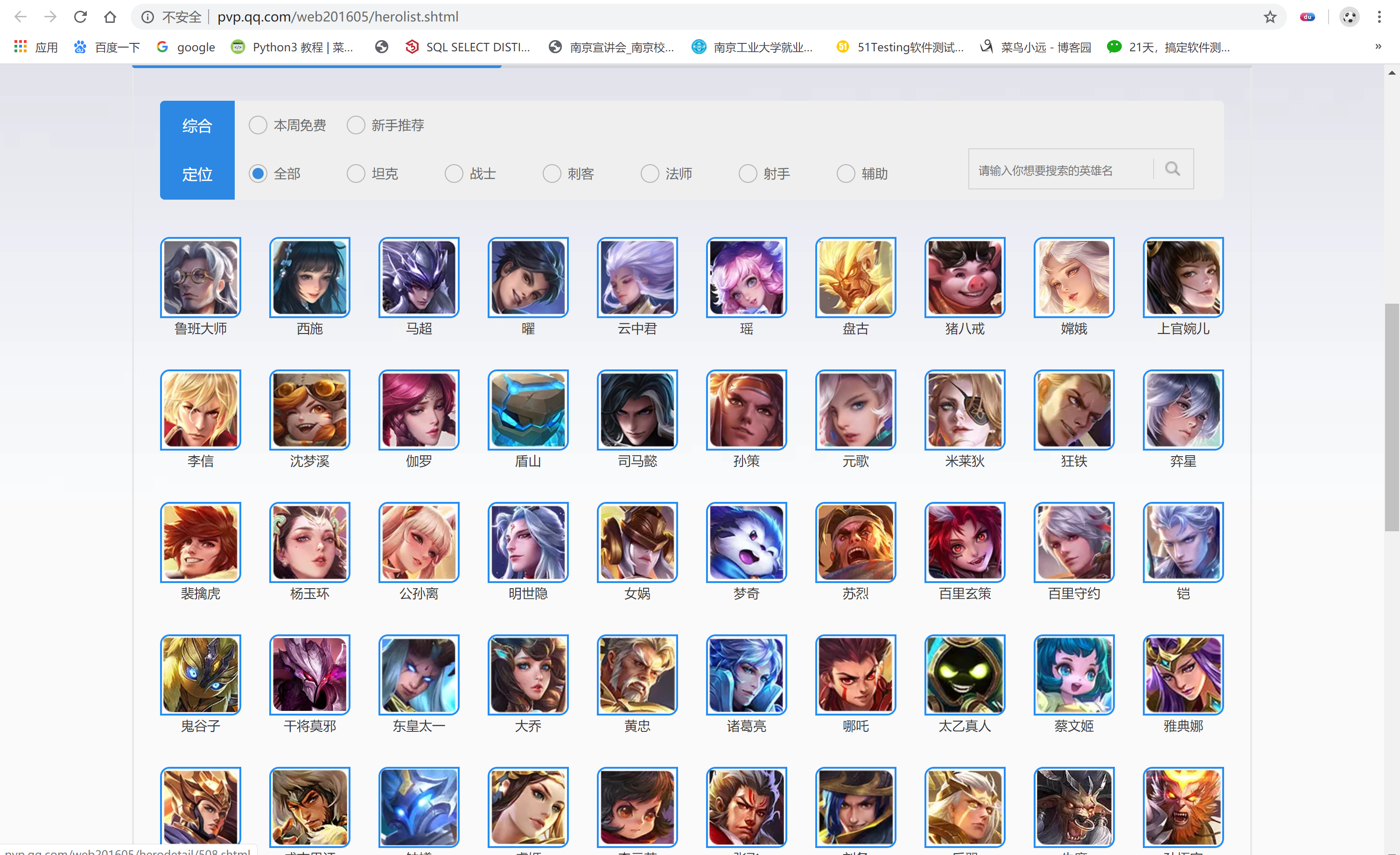
url地址:http://pvp.qq.com/web201605/herolist.shtml
运行结果:
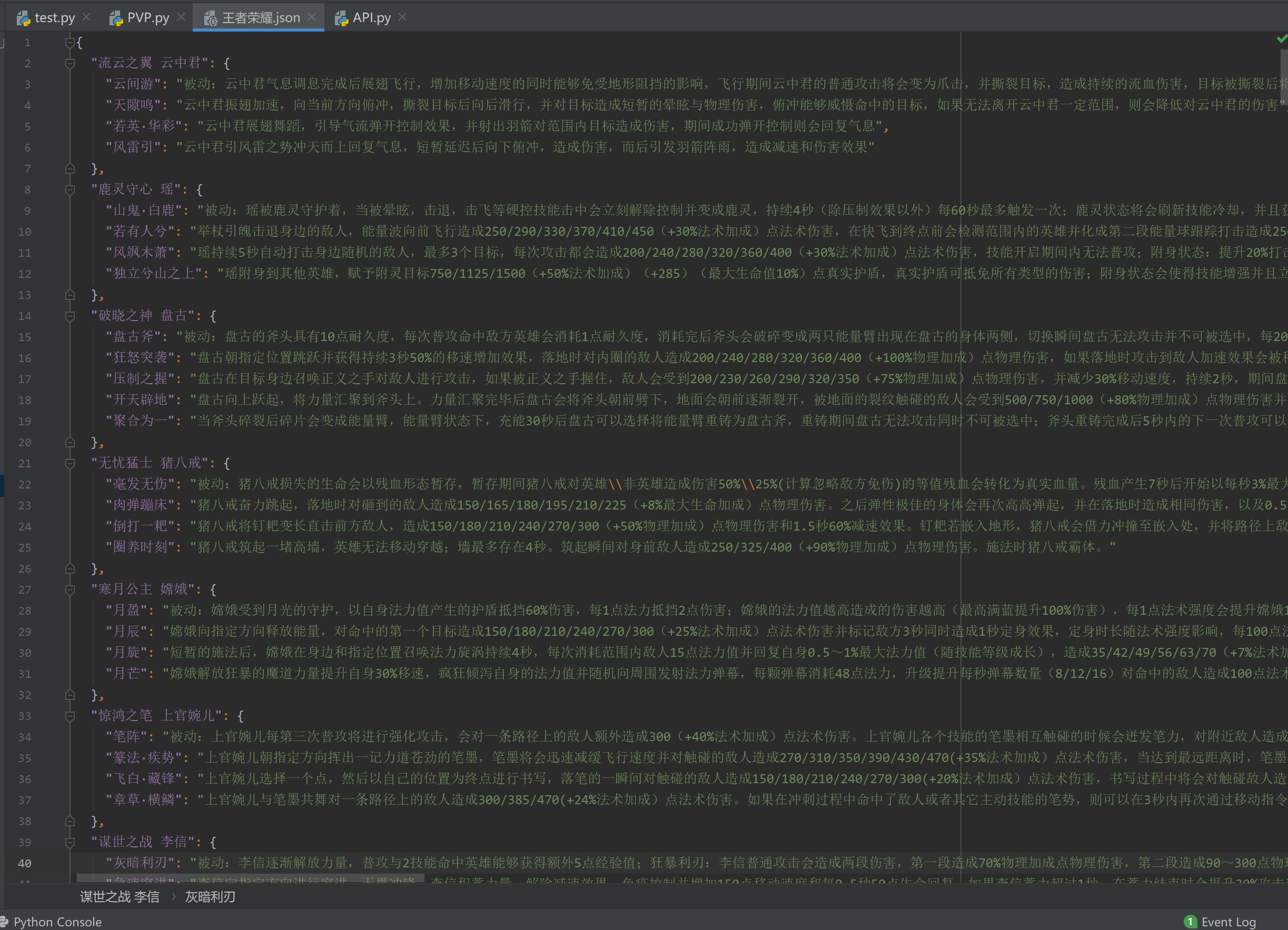
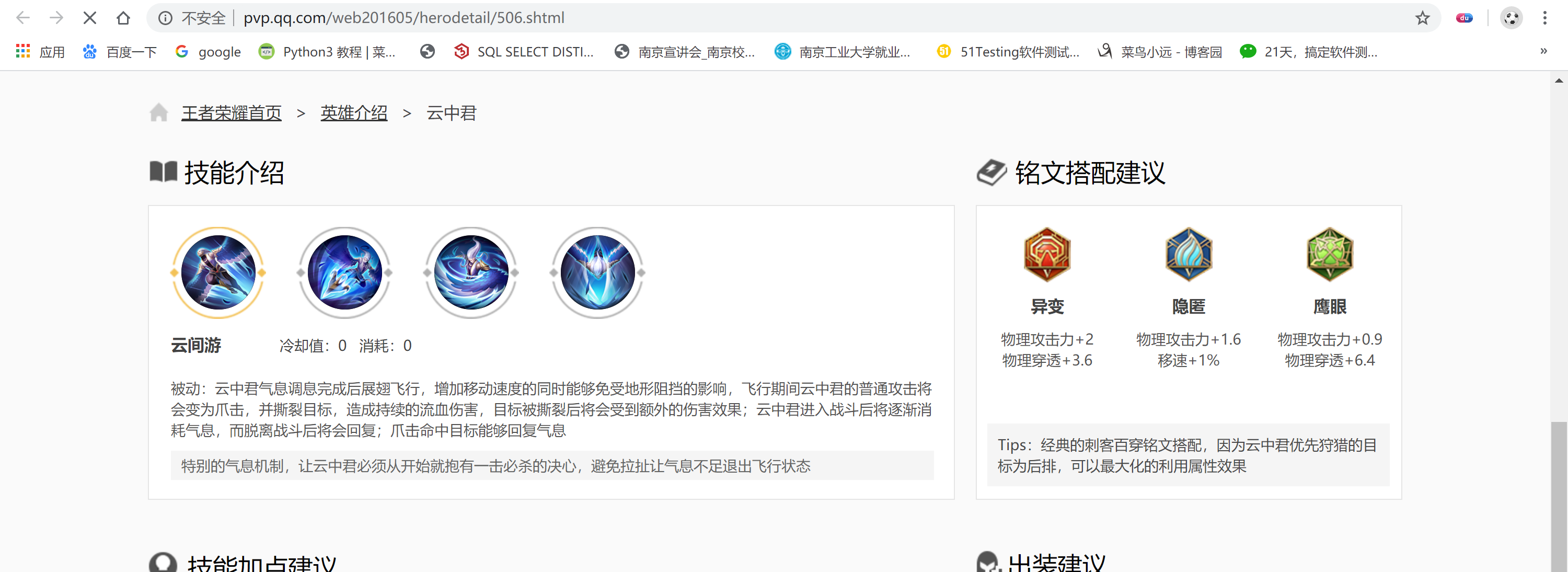
import json import requests from lxml import etree class PVP: def __init__(self): self.url = 'http://pvp.qq.com/web201605/herolist.shtml' # 一级地址 self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0'} # 创建文件对象 self.file = open('王者荣耀.json', 'w', encoding='utf8') def parse_url(self, url): """ 发送请求并解析数据 :param url: 要解析的地址 :return: 得到的页面 """ response = requests.get(url=url, headers=self.headers) return response.content.decode('gbk') def get_url_list(self, html): """ 构造url列表 :param html: 一级地址页面的数据 :return: url列表 """ # 获取二级地址参数 page = etree.HTML(html.lower()) href_list = page.xpath("//ul[contains(@class,'herolist clearfix')]/li/a/@href") # 构造二级地址列表 url_list = [] for href in href_list: url_list.append('http://pvp.qq.com/web201605/' + href) # print(url_list) return url_list def get_data(self, url_list): """ 获取二级地址列表的页面数据 :param url_list: 二级地址列表 :return: """ skill_dict = {} for url in url_list: page = self.parse_url(url) page2 = etree.HTML(page.lower()) # 1.提取英雄名列表 title = page2.xpath("//h3[contains(@class,'cover-title')]/text()") name = page2.xpath("//h2[contains(@class,'cover-name')]/text()") print("正在获取" + name[0] + "的数据") champion = (title[0] + ' ' + name[0]) # print(champion) # 2.提取英雄技能名列表 skill = page2.xpath("//div[contains(@class,'skill-show')]/div/p/b/text()") # 3.提取英雄技能描述列表 detail = page2.xpath("//div[contains(@class,'skill-show')]/div/p[contains(@class,'skill-desc')]/text()") # 4.将英雄名、技能名和技能描述列表组合成一个字典 temp_dict = dict(zip(skill, detail)) # print(temp_dict) temp_skill = {champion: temp_dict} # print(type(temp_skill)) skill_dict.update(temp_skill) # print(skill_dict) print('数据获取完成') return skill_dict def save_data(self, skill_dict): """ 将数据以json格式保存到“王者荣耀.json”中 :param skill_dict: 技能数据 :return: """ str_data = json.dumps(skill_dict, ensure_ascii=False) + '\n' # print(type(str_data)) self.file.write(str_data) self.file.close() # 关闭文件对象 def __del__(self): self.file.close() def run(self): """ 程序启动方法 :return: """ url_list = self.get_url_list(self.parse_url(url=self.url)) skill_data = self.get_data(url_list) # print(skill_data) print('正在将数据保存到本地') self.save_data(skill_data) print('已完成') if __name__ == '__main__': PVP().run()