昨天在某公众号看见一篇关于用python爬王者荣耀中所有英雄的皮肤的文章,
https://mp.weixin.qq.com/s/UgF5FYJ5dX1aNw6K0E_Jjw
感觉挺有趣的,下载来当壁纸也不错,就动手一波,环境用的是python3。过程中也遇到了一点问题,所以记录下来
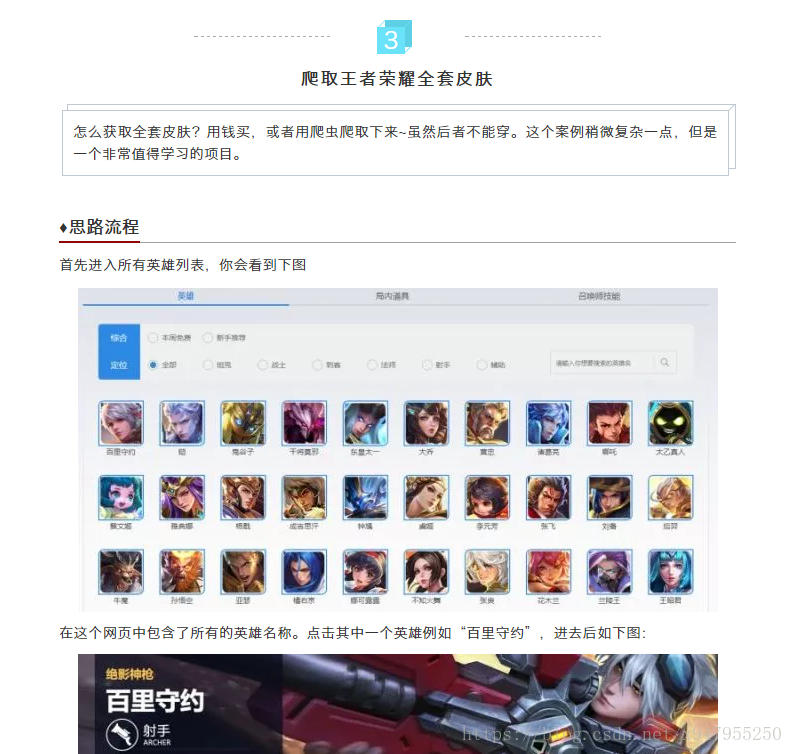
第一步首先打开
http://pvp.qq.com/web201605/herolist.shtml F12分析一波网页结构。。。
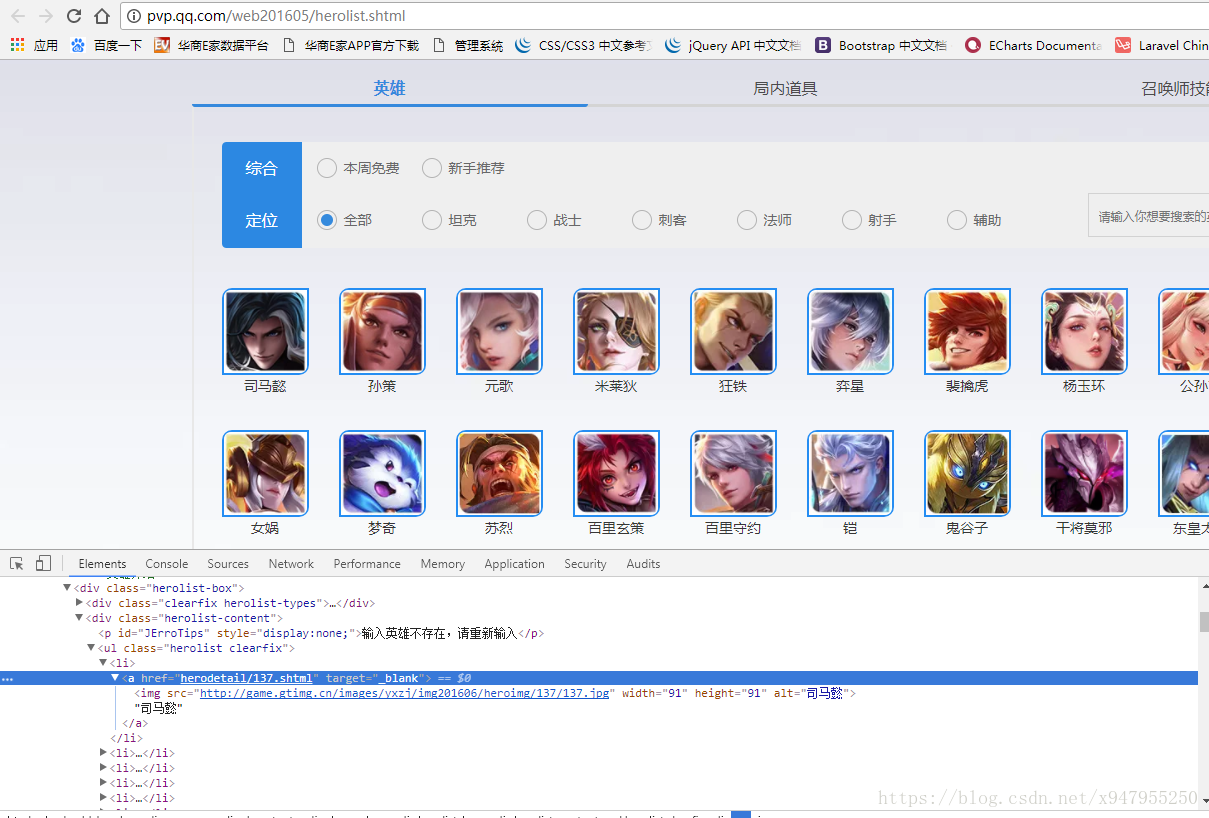
通常写这种爬虫,一般都是先分析结构,简单判断下是否有反爬机制。。看下正则表达式怎么写或者使用beatifulsoup的解析器然后再用urllib的套件下载。。。但是在经过数次尝试后发现其中有点坑。。。原因是这个页面有些英雄的链接及图片是通过js加载出来的,源代码里面根本没有。。比如这个新出的英雄司马懿。。。右键直接查看源代码。。发现第一个显示的英雄是狂铁。。(扎心)

后来搜索了一下几位前辈的文章。。发现他们都提到了一个herolist.json。。。于是重新刷新之后在控制台的network找到这个json文件。。。


这个json文件存放的是所有英雄的编号、名字、和皮肤的名字。。。
有了这些。。接下来需要要找到的是所有皮肤图片的地址。。。
点击进入英雄的详情页。。继续F12
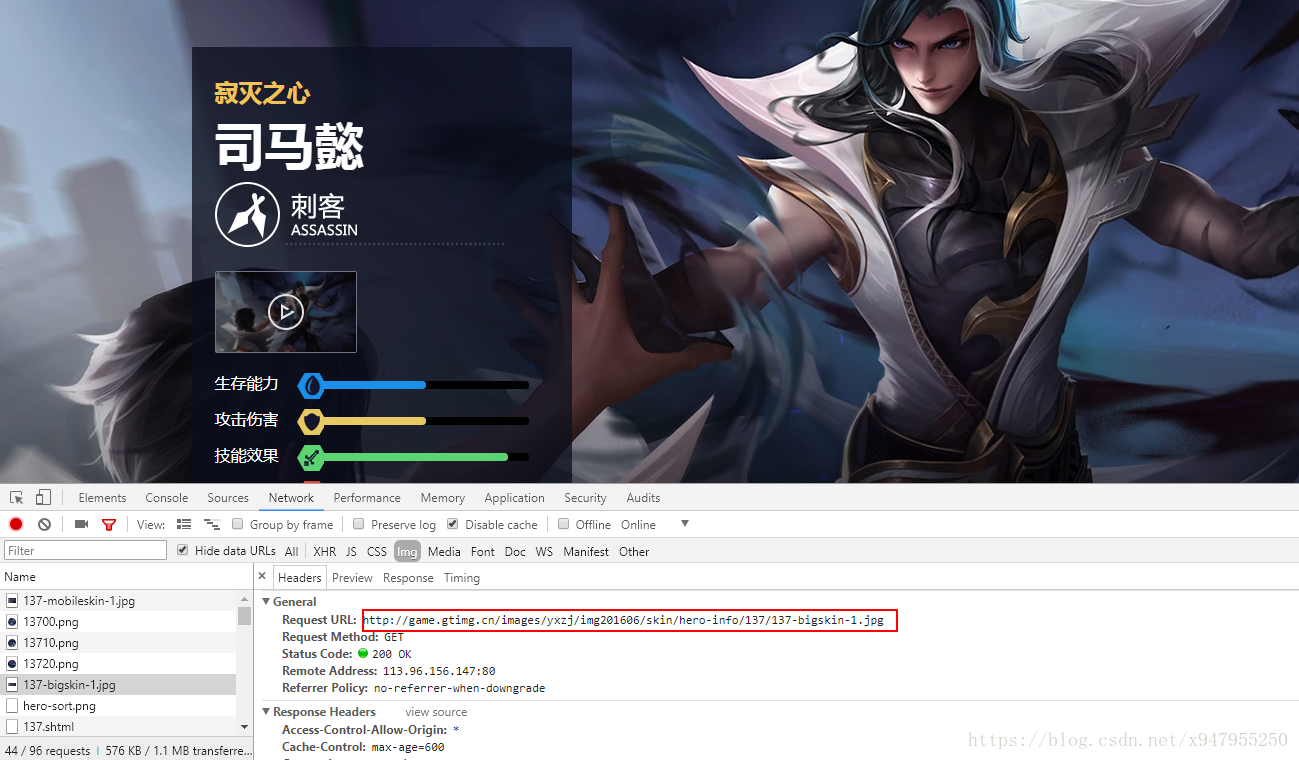
多点几个分析。。发现皮肤的图片地址都是类似这种格式
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/(英雄编号)/(英雄编号)-bigskin-(第几个皮肤).jpg
而编号和皮肤数都在刚才的json文件中。。。
下面就开始写代码了。。。完整代码如下
#-*- coding:utf-8 -*-
import requests
import json
import os
import time
start = time.time() #程序开始时间
url=requests.get('http://pvp.qq.com/web201605/js/herolist.json').content
jsonFile=json.loads(url) #提取json
#print(jsonFile)
x = 0 #用于记录下载的图片张数
#目录不存在则创建
hero_dir='E:\code\python\skin\\'
if not os.path.exists(hero_dir):
os.mkdir(hero_dir)
for m in range(len(jsonFile)):
ename = jsonFile[m]['ename'] #编号
cname = jsonFile[m]['cname'] #英雄名字
skinName = jsonFile[m]['skin_name'].split('|') #切割皮肤的名字,用于计算每个英雄有多少个皮肤
skinNumber = len(skinName)
#下载图片,构造图片网址
for bigskin in range(1,skinNumber+1):
urlPicture = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/'+str(ename)+'/'+str(ename)+'-bigskin-'+str(bigskin)+'.jpg'
picture = requests.get(urlPicture).content #获取图片的二进制信息
with open(hero_dir+cname+"-"+skinName[bigskin-1]+'.jpg','wb') as f: # 保存图片
f.write(picture)
x=x+1
print("正在下载....第"+str(x)+"张")
end = time.time() #程序结束时间
time_second = end-start #执行时间
print("共下载"+str(x)+"张,共耗时"+str(time_second)+"秒")
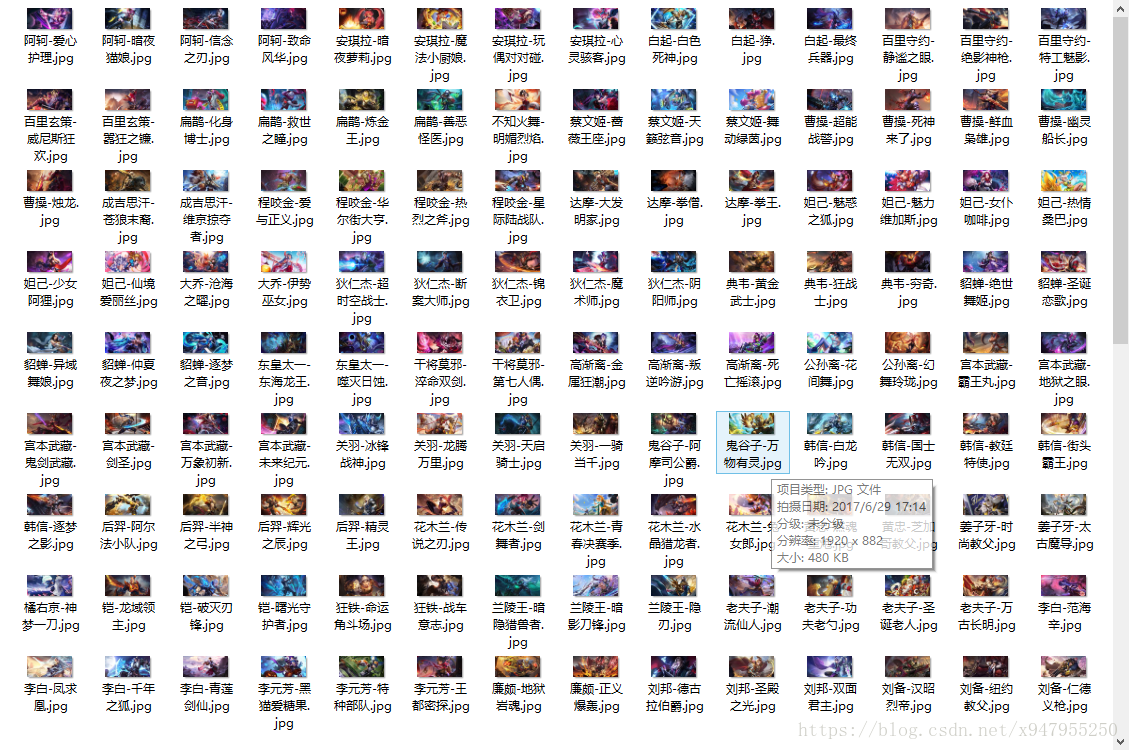
效果:


{kind=link}
在这里并没有使用urllib的包。。也没有多线程或者多进程来下载。。而且用urlretrieve有时候很容易出现假死的现象,也有可能是网络问题(手动捂脸)
下面这个是用urlretrieve下载的,为了防止假死的现象,使用了sleep。。也不知行不行。。(再次捂脸)。。也放上来,有需要可以测试下
#-*- coding:utf-8 -*-
import urllib.request
import json
import time
import os
start = time.time()
respond = urllib.request.urlopen("http://pvp.qq.com/web201605/js/herolist.json")
respond = respond.read().decode('utf-8') #防止出现编码问题
respond = respond.encode('utf-8')[3:].decode('utf-8')
json_hero = json.loads(respond)
hero_num = len(json_hero)
hero_dir='E:\code\python\skin\\'
if not os.path.exists(hero_dir):
os.mkdir(hero_dir)
x=0
for i in range(hero_num):
skin_names = json_hero[i]['skin_name'].split('|')
for cnt in range(len(skin_names)):
save_file_name = ( hero_dir+ str(json_hero[i]['ename']) + '-' + json_hero[i]['cname'] + '-'
+ skin_names[cnt] + '.jpg')
skin_url = ('http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' + str(json_hero[i]['ename']) + '/'
+ str(json_hero[i]['ename']) + '-bigskin-' + str(cnt+1) + '.jpg')
urllib.request.urlretrieve(skin_url, save_file_name)
time.sleep(1)
x+=1
print("正在下载...第"+str(x)+"张")
end = time.time()
time_second = end-start
print("共下载"+str(x)+"张,共耗时"+str(time_second)+"秒")