思路分析
首先,进入王者荣耀官网,再进入英雄资料页面。

随便找个英雄打开,进入详情页面。
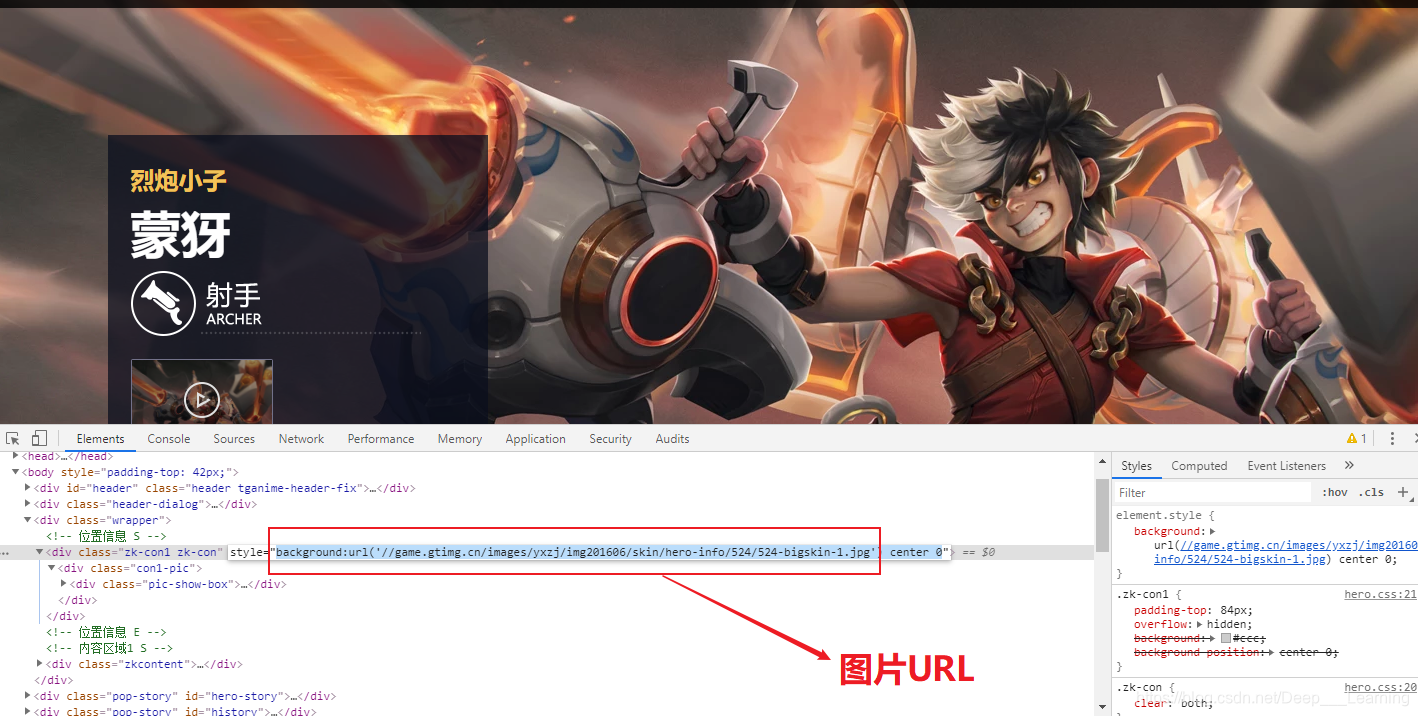
分析图片的URL,我们可以发现链接的前半部分都一样,后半部分加上了英雄的序号,因此,我们只需要找到每个英雄的序号,就可以构造URL进行图片爬取了。
对于英雄的序号,我们可以通过英雄资料页面获取到。


通过请求这个URL,我们就可以获取到英雄的序号。
最后,还有一个问题就是如何确定每一个英雄有多少个皮肤,这里我是这样处理的,由于王者荣耀每个英雄的皮肤数量较少,一般没有超过10个的吧!(截止到目前为止,以后那就不好说了。)
因此,我直接循环10次,看请求的返回码,如果是200就证明存在该皮肤图片,否则就是不存在该皮肤图片。
完整代码
# !/usr/bin/env python
# —*— coding: utf-8 —*—
# @Time: 2020/1/29 8:42
# @Author: Martin
# @File: King_Skin.py
# @Software:PyCharm
import requests
import json
import os
url1 = 'https://pvp.qq.com/web201605/js/herolist.json'
raw_url2 = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/%d/%d-bigskin-%d.jpg'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'}
response = requests.get(url1, headers=headers)
hero_list = json.loads(response.text)
for it in hero_list:
ename = it['ename']
cname = it['cname']
if not os.path.exists('./result/KingSkin/'+cname):
os.makedirs('./result/KingSkin/'+cname)
for i in range(0, 10):
url2 = raw_url2 % (ename, ename, i)
r = requests.get(url2, headers=headers)
if r.status_code is 200:
with open('./result/KingSkin/' + cname + '/' + cname + str(i) + '.jpg', 'wb') as f:
f.write(r.content)
print(cname+str(i))
效果展示




