编码前准备:
导入maven依赖:
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
获取全英雄全皮肤,思路以及方法方式都跟上一篇博客差不多
没有思路的小伙伴可以先看看我的上一篇博客:Java爬取王者荣耀英雄壁纸
但是爬取全皮肤的话,会稍微麻烦一点。
利用Java爬虫的话,分析HTML文档结构是十分有必要的,你会发现它全是利用dom文档里面的属性和文本来获取数据。
而 jsoup.jar包的作用说白了就是提供了操作文档对象的api,让我们的使用Java代码可以获取dom元素的一些信息。
java爬虫的难点,很大程度上在于如何利用 jsoup获取我们要爬取的内容,比如获取图片在互联网上的绝对路径,有了这个路径,再使用I/O对它进行下载就不是什么难事了。
代码
package test;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
public class ReptilePicImgs {
public static void main(String[] args) throws IOException {
long t1 = System.currentTimeMillis();
Connection connection = Jsoup.connect("https://pvp.qq.com/web201605/herolist.shtml");
long t2 = System.currentTimeMillis();
System.out.println("创建连接的时间:"+(t2-t1)+"毫秒");
Document document = connection.get();
long t3 = System.currentTimeMillis();
System.out.println("读取document信息所用时间:"+(t3-t2)+"毫秒");
Element elementUL = document.selectFirst("[class=herolist clearfix]");
Elements elementsLis = elementUL.select("li");
int size = 0;
for(Element elementLi : elementsLis) {
Element elementA = elementLi.selectFirst("a");
String href = elementA.attr("href");
String heroName = elementA.text();
String netPath = "https://pvp.qq.com/web201605/" + href;
Connection newConnection = Jsoup.connect(netPath);
Document newDocument = newConnection.get();
Element div = newDocument.selectFirst("[class=zk-con1 zk-con]");
String divStyle = div.attr("style");
String backgroundUrl = divStyle.substring(divStyle.indexOf("'") + 1, divStyle.lastIndexOf("'"));
//System.out.println(backgroundUrl);
Element picUl = newDocument.selectFirst("[class=pic-pf-list pic-pf-list3]");
String allName = picUl.attr("data-imgname");
allName = allName.replace("|","-");
String[] preNames = allName.split("-");
for(int i = 0;i<preNames.length;i++){
if(preNames[i].contains("&")){
preNames[i] = preNames[i].substring(0,preNames[i].lastIndexOf("&"));
}
}
String[] urldatas = new String[preNames.length];
int skinNum = preNames.length;
for (int i = 0;i<skinNum;i++){
urldatas[i] = backgroundUrl.replace("1.jpg",String.valueOf(i+1)+".jpg");
//System.out.println(urldatas[i]);
}
//开始下载:
for(int i = 0;i<preNames.length;i++){
String lastName = heroName+"-"+preNames[i];
System.out.println("下载:<<"+lastName+">>,图片路径:-->"+urldatas[i]);
URL url = new URL("https:"+urldatas[i]);
//根据这个url地址,创建一个输入流
InputStream inputStream = url.openStream();
FileOutputStream fileOutputStream = new FileOutputStream("F://img//"+lastName+".jpg");
//需要创建一个byte数组
byte[] b = new byte[1024];
//读取到的数据临时存放在b字节数组内
int count = inputStream.read(b);//count 指的是读取的有效字节个数
while (count!=-1){
fileOutputStream.write(b,0,count);
fileOutputStream.flush();
count = inputStream.read(b);
}
fileOutputStream.close();
inputStream.close();
size++;//记录总共下载的图片个数
}
}
long t4 = System.currentTimeMillis();
double time = (double) (t4-t1)/1000;
System.out.println("恭喜您已完成全部下载,共耗时:"+time+"秒,下载图片"+size+"张");
}
}
看了一些人利用python爬取王者荣耀全皮肤的,有的人他们直接使用的一个json文件,里面存储好了图片的各种信息,然后在代码中拼接起来图片的完整路径。但是那样做的话,当王者有新皮肤时,就还要更改json文件,否则下载的皮肤不全。数据都是自己准备的,就很麻烦。
结果:
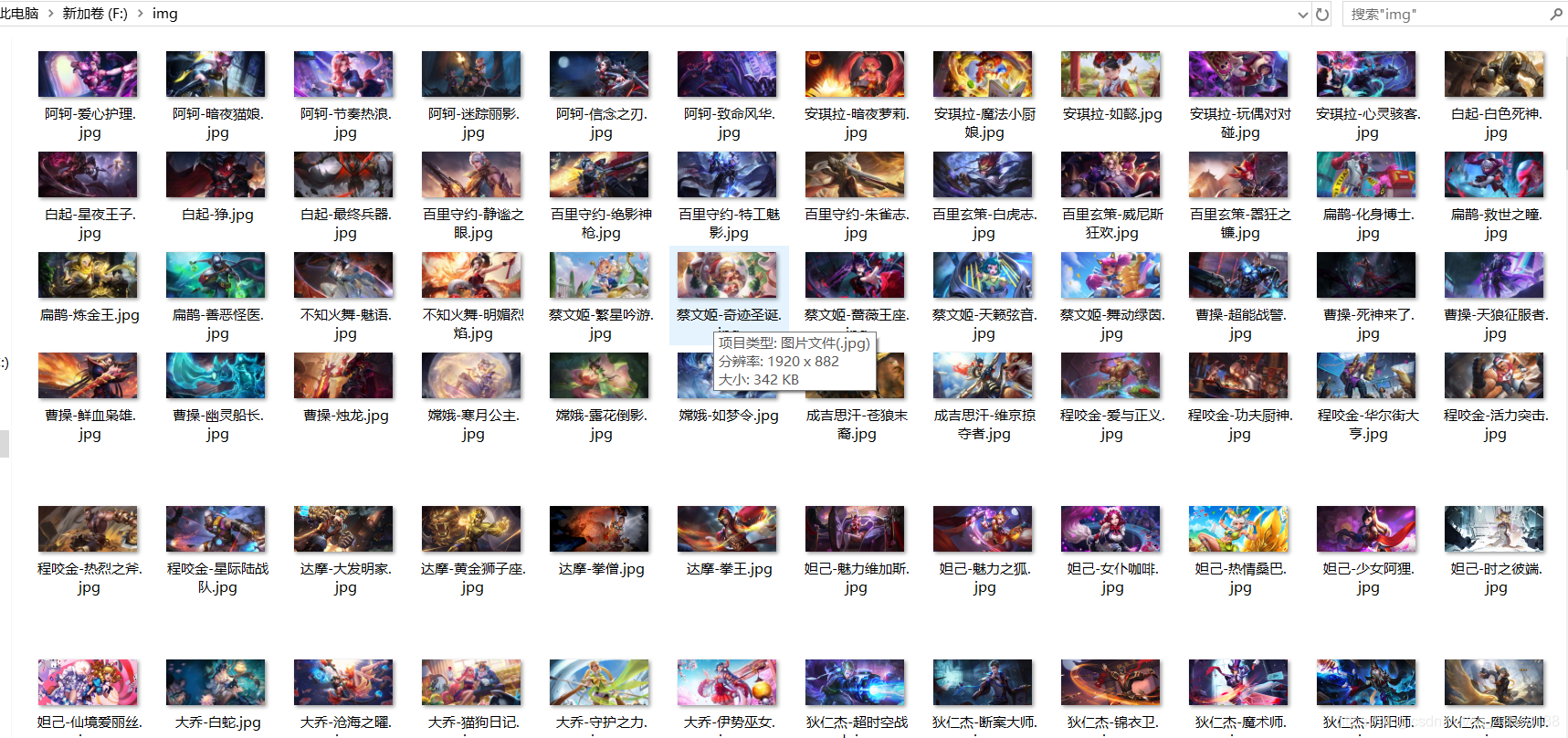
当然,这种爬虫方式严重依赖王者荣耀官网的页面设计人员的对于图片的命名规则,因为你会发现,每个皮肤的路径都是只修改了最后的那个序号,第一个皮肤是1号(也就是原皮肤),后面的依次类推。
倘若它的命名没有任何规范,我们的写的程序也就无能为力了。
关于反爬虫,我不太了解,但是当我在爬取王者荣耀官网上的全皮肤时,有时候选中的div元素里面明明有内容,但是代码获取到的div元素里,内容全部被注释了,我们根本无法获取到里面的内容,我想这就是反爬虫的一种吧。
