先上成果图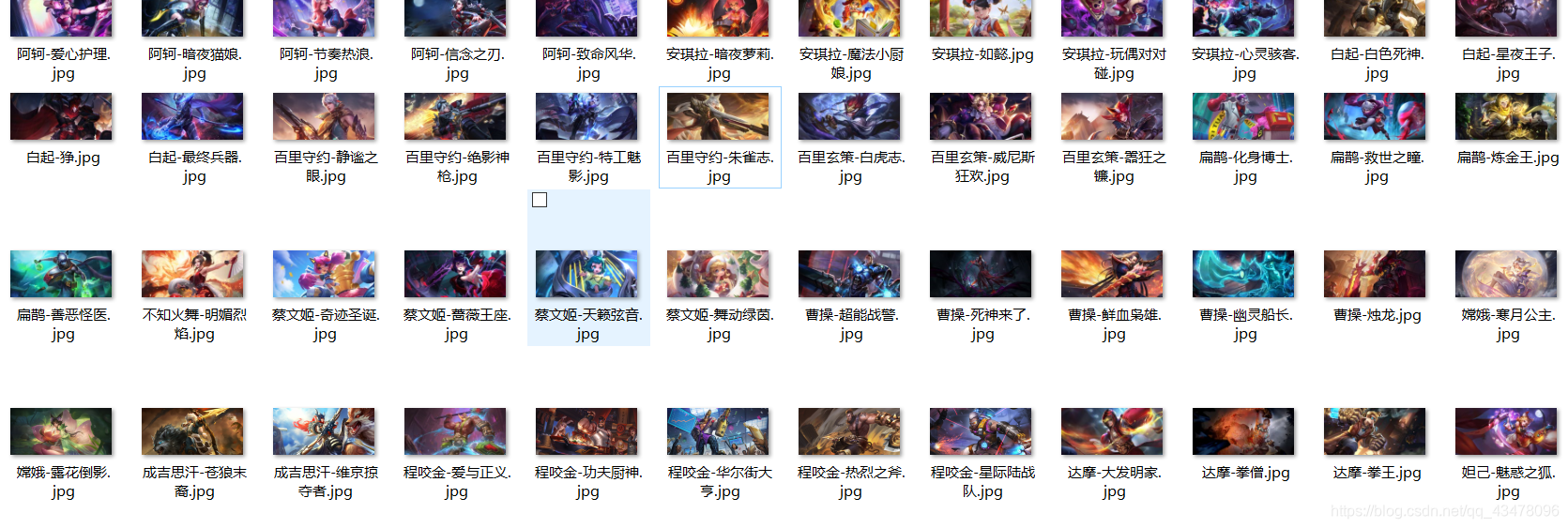
模块安装:
requests: pip install requests
json:json好像不是第三方库,如果没有pip install json应该也能安装
pycharm用户可以忽略上面两行
上脚本
使用脚本前先要在根目录下新建一个img文件夹,用以保存文件。
# 标题:爬取王者荣耀全英雄皮肤图片
# requests
# json
# 爬虫的一般思路
# 1、确定爬取的url路径,headers参数
# 2、发送请求 -- requests 模拟浏览器发送请求,获取响应数据
# 3、解析数据 -- json模块:把json字符串转化成python可交互的数据类型
# 4、保存数据 -- 保存在目标文件夹中
import requests
import json
import time
start_time = time.time() # 记录开始时间
# 1、确定爬取的url路径,headers参数
base_url = 'https://pvp.qq.com/web201605/js/herolist.json'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36'}
# 2、发送请求 -- requests 模拟浏览器发送请求,获取响应数据
response = requests.get(base_url, headers=headers)
data_str = response.text # --字符串
# print(type(data_str))
# 3、解析数据 -- json模块:把json字符串转化成python可交互的数据类型
# 3、1 转换数据类型
data_list = json.loads(data_str) # --列表
# 3、2 数据解析
for data in data_list:
# 提取图片所需参数
ename = data['ename'] # 英雄编号
cname = data['cname'] # 英雄名字
try:
skin_name = data['skin_name'].split('|') # 切割皮肤的名字,用于计算每个英雄有多少个皮肤
except Exception as e:
print(e)
# print(ename,cname,skin_name)
# http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/524/524-bigskin-1.jpg
# http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/ + 英雄编号 + "/" + 英雄编号-bigskin-皮肤序号 + ".jpg"
# 构建皮肤数量的循环
for skin_num in range(1, len(skin_name) + 1):
skin_url = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' + str(ename) + '/' + str(
ename) + '-bigskin-' + str(skin_num) + '.jpg'
# print(skin_url)
# 请求图片数据
skin_data = requests.get(skin_url, headers=headers).content
# 4、保存数据 -- 保存在目标文件夹中
with open('img\\' + cname + "-" + skin_name[skin_num - 1] + '.jpg', 'wb') as f:
print('正在下载皮肤:', cname + "-" + skin_name[skin_num - 1])
f.write(skin_data)
# time.sleep(0.1)
end_time = time.time() # 记录结束时间
all_time = end_time - start_time # 执行时间
print('共花费时间(单位秒):', all_time, '秒')
print('皮肤图片下载完成。。。。。。')
再附上一篇爬英雄联盟的脚本(由于两个网站标签不同,这个脚本难度强于上一个)
#英雄联盟皮肤爬取
import requests
import re
import json
import time
star_time = time.time()
base_url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'}
#url = ['https://lol.qq.com/data/info-defail.shtml?id={}'.format(str(i)) for i in range(1,10)]
#皮肤链接 src="https://game.gtimg.cn/images/lol/act/img/skin/big1000.jpg"
response = requests.get(base_url , headers = headers)
data_str = response.text
#print(data_str)
data_list = json.loads(data_str)
#print(data_list)
for data in data_list['hero']:
#print(data)
name = data['name']
title = data['title']
skin_nums = data['attack']
heroId = data['heroId']
#url = ['https://game.gtimg.cn/images/lol/act/img/skin/big' + str(heroId) + '0{}.jpg'.format(str(i)) for i in range(0 , len(skin_num + 1))]
for skin_num in range(0 , 20):
'''
skin = str(skin_num)
skin = heroId.zfill(2) #单数变双数
'''
if skin_num < 10:
url = 'https://game.gtimg.cn/images/lol/act/img/skin/big' + str(heroId) + '0' + '0' + str(skin_num) + '.jpg'
#print('aaaaaaa')
else:
url = 'https://game.gtimg.cn/images/lol/act/img/skin/big' + str(heroId) + '0' + str(skin_num) + '.jpg'
#print('bbbbbb')
skin_data = requests.get(url, headers=headers)
if skin_data.status_code == 200:
skin_data = requests.get(url, headers=headers).content # 获取二进制图片数据
with open('img\\' + title + '-' + str(skin_num) + '.jpg' , 'wb') as f:
f.write(skin_data)
print(url)
print('downloading:' + title + '-' + str(skin_num)) #json库里面没有皮肤名 草
time.sleep(1)
end_time = time.time()
all_time = end_time-star_time
print('this project takes' , all_time , 'seconds')
脚本详详详解以后再写。