前言
以前写过类似的博客,利用Java爬取王者荣耀全英雄全皮肤图片,当时是利用 jsoup包来对目标网页进行解析。
可笑的是当时找图片的链接找了好久,处理字符串,拼接完整图片路径弄了半天,感觉还是比较麻烦的,原因之一就是当时找的链接地址是找的背景图:
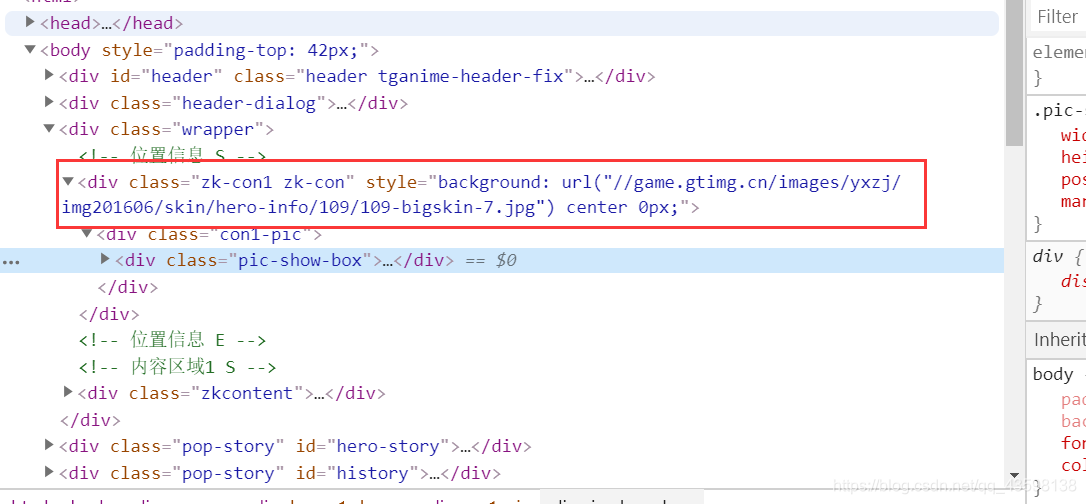
殊不知,链接地址不用这么麻烦,王者荣耀官网提供得明明白白,右键单击检查某个皮肤的头像:
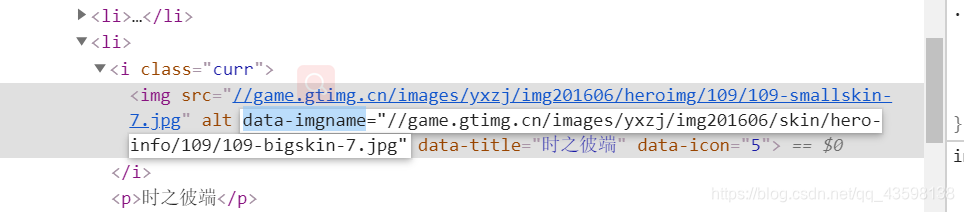
图片的地址其实就是这个data-imgname,每个英雄有几个皮肤,则链接最后的那个数字就是几,随着末尾数字的改变可以使得皮肤切换。这样一来问题就变得非常得简单了。
当时要是知道这一点,代码也会少些很多行。
这次我打算使用python,来实现王者图片的爬取,当然这次我会尽量详细得记录整个过程。
emm,程序员小白一门,大佬们见笑了
好了进入正题。
思路
python爬虫的一般思路
- 分析目标网页,确定爬取的url路径
- 发送请求 — requests 模拟浏览器发送请求,获取响应数据
- 解析数据 — json模块:把json字符串转化成python可交互数据类型
- 保存数据 — 保存在目标文件夹中
分析
我们接着上面提到的继续分析,首先比较一下妲己两个不同皮肤的url:

可以发现仅仅是末尾的数字编号不同。
然后,比较一下妲己和貂蝉两个不同英雄皮肤的url:

可以发现前面的部分是相同的,只是后面的编号不同。
由此我们可以猜测,每一个英雄都有一个自己对应的编号,有多少个英雄,就有多少个编号。
而且前面我们还知道了,英雄有多少个皮肤,末尾的数字就是几,url的末尾数字对应了英雄的皮肤。
在这样一个英雄的列表页:
它肯定是一个动态页面,因为英雄的数量不是固定的,每隔一段时间,都会有新英雄或者新皮肤的加入,我们需要找到一个数据包,这个数据包中涵盖了所有英雄和皮肤的编号值。
我们在这里的空白区域,右键单击检查,选择network,刷新页面,在数据包过滤器中选择ALL。(针对谷歌浏览器)
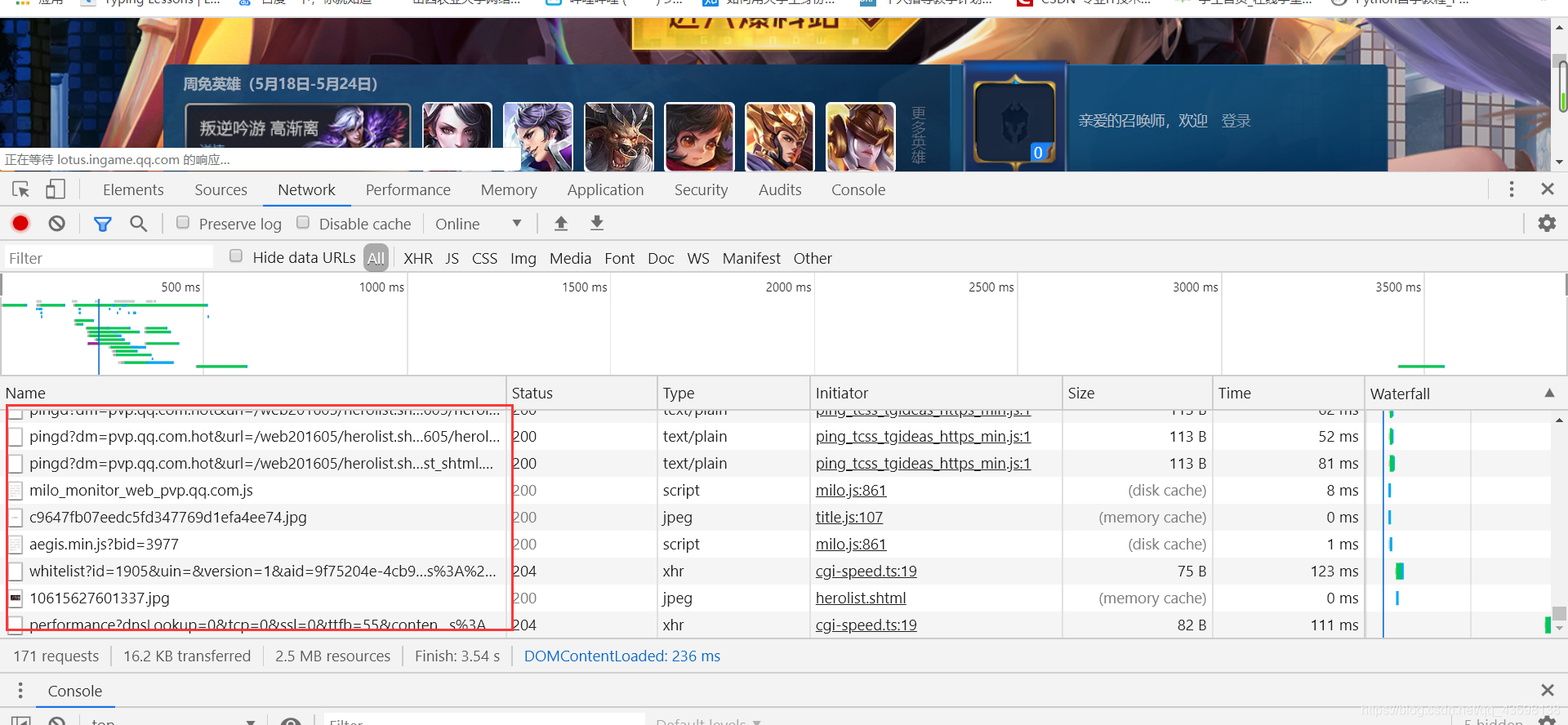
然后我们可以一个数据包一个数据包找,看哪个包含所有英雄的 id号和皮肤数量信息。
而这些数据很可能就是动态加载的,针对动态加载的这些数据,我们在数据包过滤器中选择 XHR 对其进行过滤:
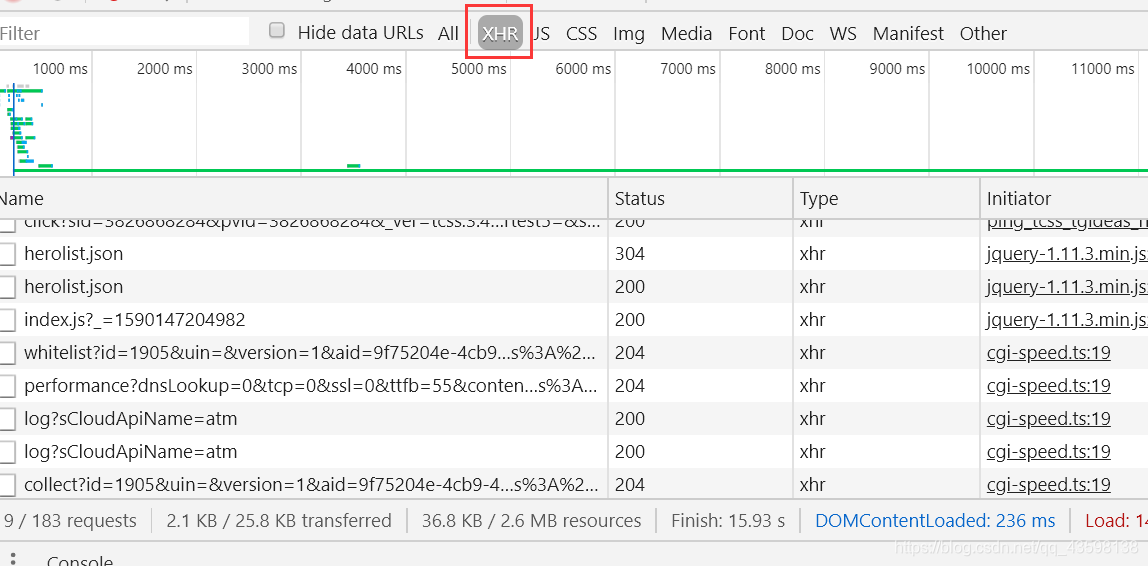
过滤之后,下面的数据包就少了很多。
接下来就是我们要干的体力活了,挨个找寻数据包,检查它是否包含我们需要的信息。
第一个数据包:
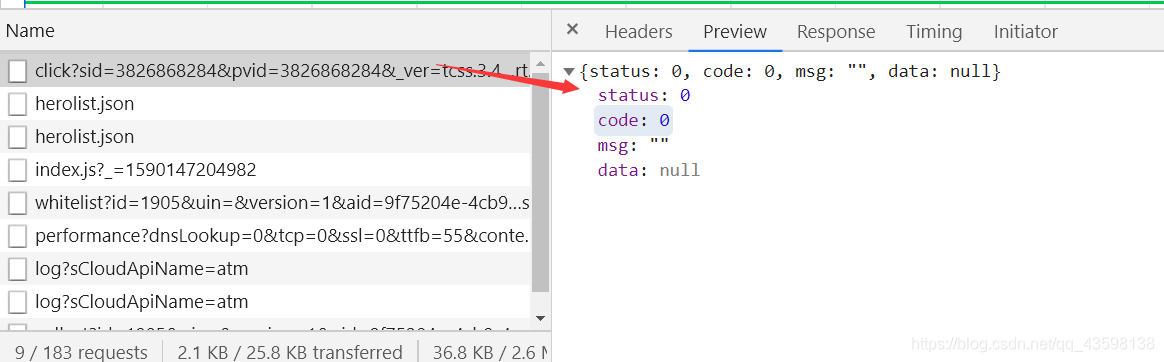
太简陋,基本没啥数据,过。
第二个数据包:

我们发现它一共有0~98,也就是99个数据项,我数了一下,发现正好对应了目前王者荣耀99个英雄。
数量是对上了,但是我们发现其中有一些乱码,英文没有乱而中文乱码了。
查看它的编码方式:
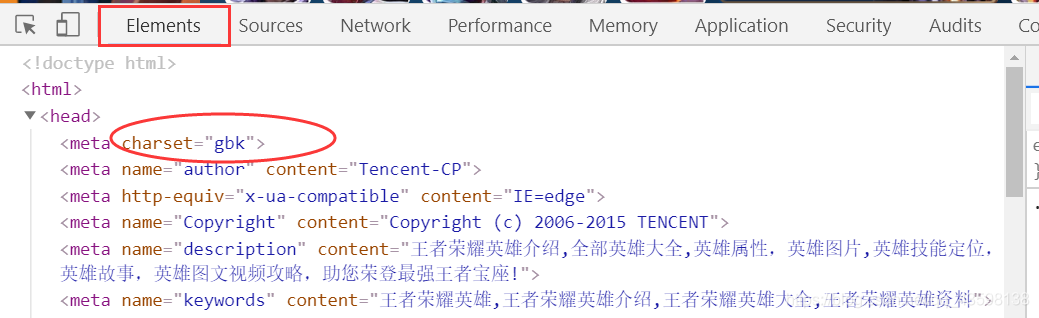
我们发现当前这个网站它使用的是GBK编码。
而谷歌浏览器默认使用的是UTF-8编码。
编码方式的不同使得中文的解码发生乱码。
在往下看,我们发现其他的数据包都不是我们想要的。
那就这个hellolist.json了。
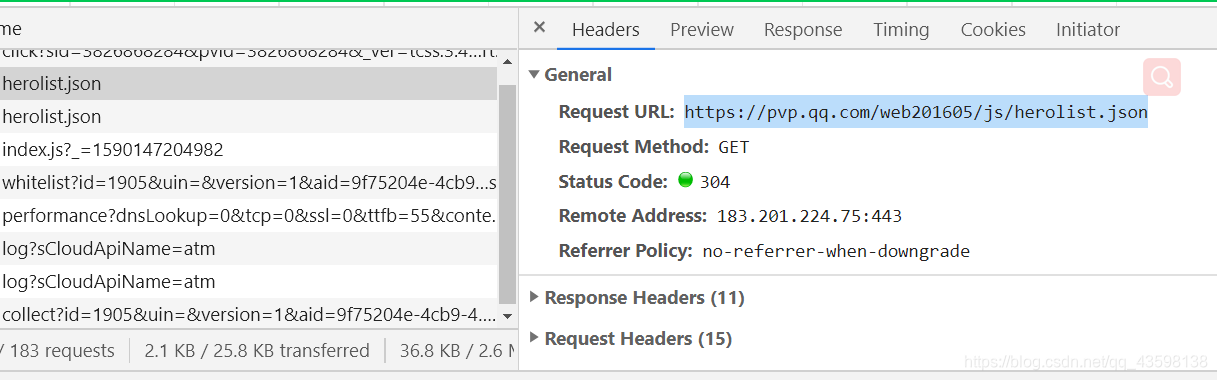
我们定位到这个数据包,选择Headers,查看当前数据包的请求地址和请求方式以及其他信息:
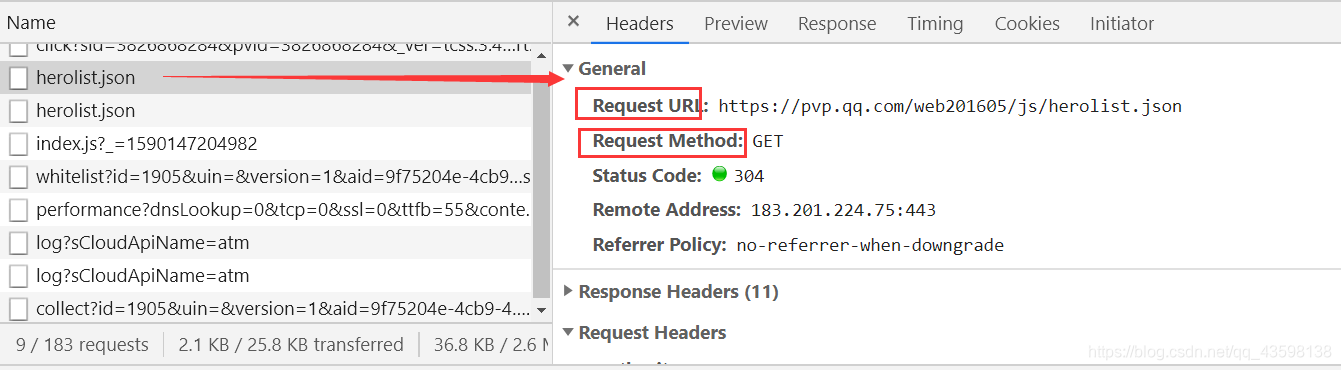
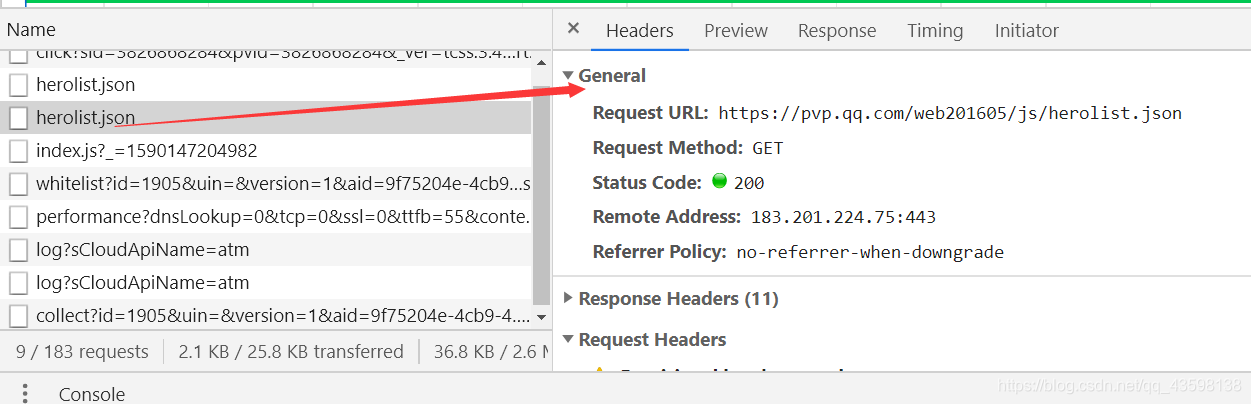
我们可以看到其中有两个hellolist.json
一个状态码(Status Code)是304,代表重定向,另一个是200,代表请求成功。
两个hellolist.json的request url都是相同的,我们就拿第一个hellolist.json来做就好。
包括后面有响应头字段和请求头字段:
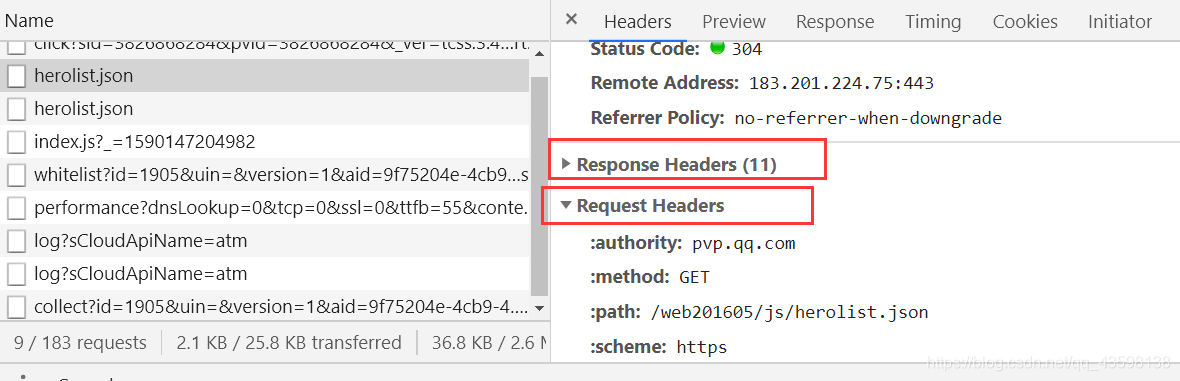
编码
复制这个数据包的请求地址:
首先,导入requests
import requests
1、分析目标网页,确定爬取的url路径:
base_url = 'https://pvp.qq.com/web201605/js/herolist.json'
然后,我们还需要一个herders请求字段,为的是模拟用户的请求。
本案例中,我们仅仅使用到herders中的一个请求字段—user-agent
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
user-agent是最常见的反爬字段,可以很好地把我们的代码伪装成浏览器用户
user-agent是用户身份的标识,它包含浏览器的名称,版本,操作系统信息,浏览器内核信息
2、发送请求 — requests 模拟浏览器发送请求,获取响应数据
response = requests.get(url=base_url,headers=headers)
然后我们打印一下response中的文本内容:
print(response.text)

可以看到里面的内容,并且它是一个json数组。
而且浏览器中的是乱码的,在pycharm中打印的内容没有乱码。(这是由于我所使用的windows操作系统默认使用的GBK编码)
json是一种轻量级的数据传输格式,具有层次清晰,结构明了的特征,非常方便我们在后台进行数据传递。
针对 json格式的数据,我们可以采用response.json()方法,提取 json格式的数据,转化为一个列表:
data_list = response.json()
print(type(data_list)) #<class 'list'>
print(type(data_list[0])) #<class 'dict'>
# 列表的每一项是一个字典
字典和json看起来很像,都是一个大括号,里面是键值对,但是它们是完全不同的两种数据类型,python可以直接操作字典,但是不能直接操作 json,所以需要类型转化。
在pycharm中字典打印的效果没有层次感,是一行的:

而上面打印的 json数据就很有层次。
那么问题来了:我们既想使用python能操作的数据类型 字典和列表,又要使其打印出来的效果直观清晰明了,该如何?
我们就需要导入python的一个内置模块,pprint:
import pprint
pprint是一个格式化输出模块,我们需要使用它的pprint方法:
pprint.pprint(data_list)
这样打印出来的效果就很清晰明了:

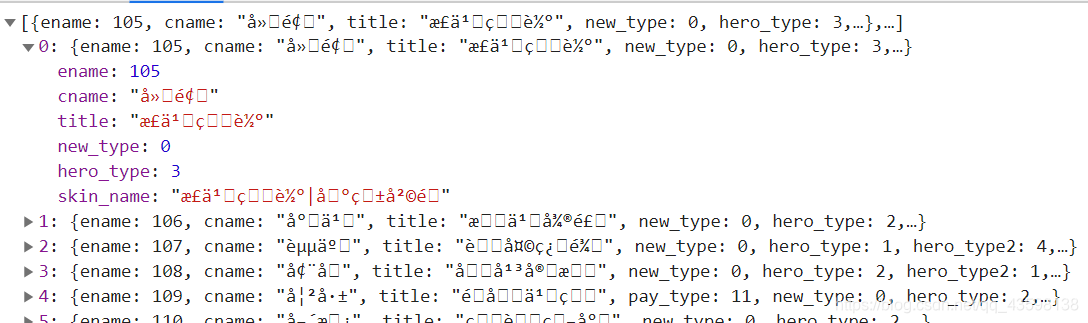
它其中有这么几个字段:cname英雄名称,ename是英雄的编号,剩下的英雄类型,我们就不用关注,它肯定是代表什么坦克,辅助,刺客法师之类的,还有就是skin_name皮肤名称,title英雄别名。
最主要的就是ename字段,我们拿赵云的ename = 107举例,把妲己的url地址(//game.gtimg.cn/images/yxzj/img201606/skin/hero-info/109/109-bigskin-1.jpg)中的英雄编号替换成赵云的编号:
//game.gtimg.cn/images/yxzj/img201606/skin/hero-info/107/107-bigskin-1.jpg

可以证实ename的确是英雄的编号,它的英雄图片的确是有ename所决定的。
解析思路:
我们就可以把数据包中的ename字段提取出来,使用字符串拼接,就可以拿到所有英雄的图片地址。
保存图片时,我们需要使用到英雄名称cname以及皮肤名称skin_name。
并且,有了skin_name我们通过它就可以知道该英雄一共有多少个皮肤。这样不就可以获取到全英雄全皮肤图片的url地址嘛。
数据解析:
for data in data_list:
heroName = data['cname'] #英雄名称
heroId = data['ename'] #英雄的id值
heroSkinList = data['skin_name'].split('|') #英雄的所有皮肤名称
print(heroName,heroId,heroSkinList)
我们打印出每个英雄的heroName 、heroId 、heroSkinList :
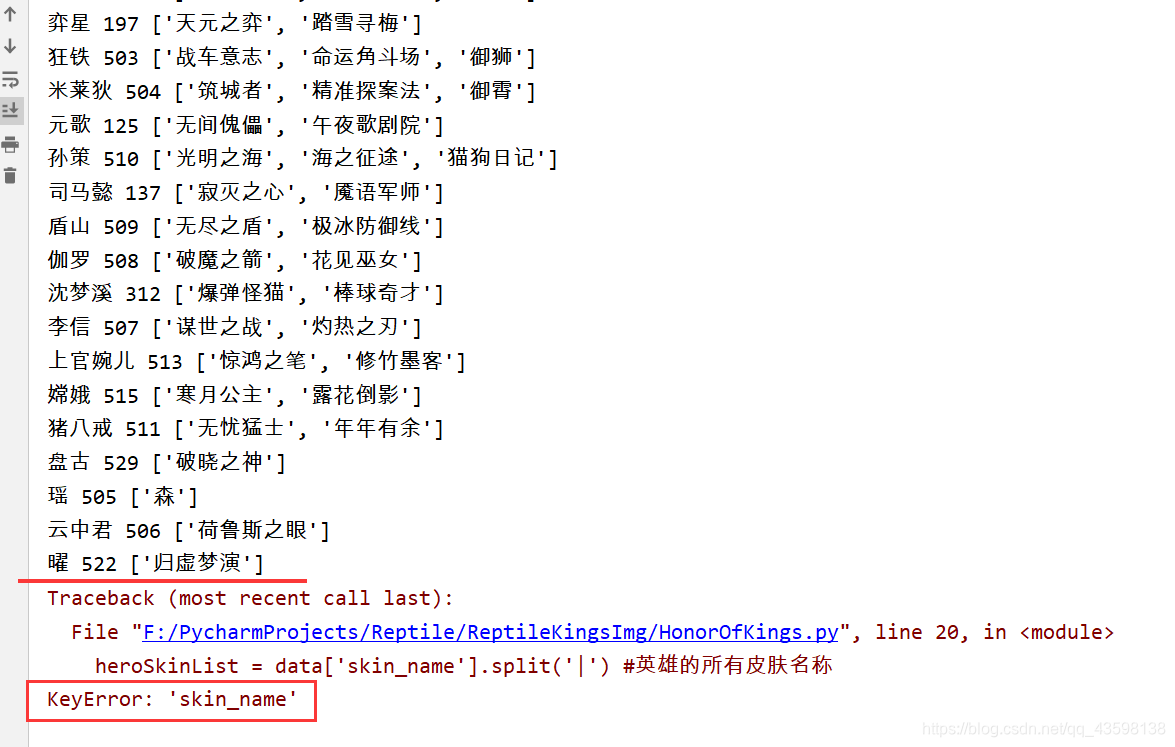
我们可以发现,当打印到英雄“曜”的下一个英雄时候,出现报错:
heroSkinList = data['skin_name'].split('|') #英雄的所有皮肤名称 KeyError: 'skin_name'
提示键名错误 KeyError。
我们看看以前使用pprint.pprint打印的数据,搜索“曜”:

我们发现“曜”的下一个英雄是马超,而马超却没有skin_name字段。
我们继续往下看:

发现马超的后面“西施”和“鲁班大师”都有skin_name字段,唯独马超没有。
针对这样一种特殊情况,我们写一个异常捕获:
for data in data_list:
heroName = data['cname'] #英雄名称
heroId = data['ename'] #英雄的id值
try:
heroSkinList = data['skin_name'].split('|') #英雄的所有皮肤名称
except Exception as e:
print(e)
print(heroName,heroId,heroSkinList)
打印的结果:

发现到了最后,就只有马超这个英雄单独没有skin_name,其他英雄都是正常的。
我们不妨手动为我们的马超添加skin_name,为了爬取得尽量全一点 也是拼了。
打开官网瞅一瞅:

好的,照抄过来:
try:
heroSkinList = data['skin_name'].split('|') #英雄的所有皮肤名称
except Exception as e:
#print(e)
# 手动为我们的马超添加skin_name
heroSkinList = ['冷晖之枪','幸存者'] # 注意原皮肤在前
然后,通过一个for循环,获取所有图片的url:
# 构建皮肤数量的循环
for skin in range(1,len(heroSkinList) + 1):
# http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/英雄的id值/英雄的id值-bigskin-皮肤编号.jpg
img_url = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/'+str(heroId)+'/'+str(heroId)+'-bigskin-'+str(skin)+'.jpg'
print(img_url)

接下来,我们进行图片的下载:
#请求图片数据,因为它是一个二进制数据,所以我们需要调用content获取
img_data = requests.get(url=img_url,headers=headers).content
#保存数据
path = '王者荣耀'
if not os.path.exists(path):
os.mkdir(path)
with open('王者荣耀\\'+heroName+"-"+heroSkinList[skin-1]+".jpg",mode='wb') as f:
print("正在下载皮肤:",heroName+"-"+heroSkinList[skin-1])
f.write(img_data)
f.close()
案例源码
import requests
import pprint
import os
# 1. 分析目标网页,确定爬取的url路径
base_url = 'https://pvp.qq.com/web201605/js/herolist.json'
# herders请求字段,为的是模拟用户的请求
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
# user-agent是用户身份的标识,它包含浏览器的名称,版本,操作系统信息,浏览器内核信息
# user-agent是最常见、最起码的反爬字段,可以很好地把我们的代码伪装成浏览器用户
}
# 2. 发送请求 --- requests 模拟浏览器发送请求,获取响应数据
response = requests.get(url=base_url,headers=headers)
data_list = response.json()
#pprint.pprint(data_list)
# 3. 解析数据 --- json模块:把json字符串转化成python可交互数据类型
for data in data_list:
heroName = data['cname'] #英雄名称
heroId = data['ename'] #英雄的id值
try:
heroSkinList = data['skin_name'].split('|') #英雄的所有皮肤名称
except Exception as e:
#print(e)
# 手动为我们的马超添加skin_name
heroSkinList = ['冷晖之枪','幸存者'] # 注意原皮肤在前
print(heroName,heroId,heroSkinList)
# 构建皮肤数量的循环
for skin in range(1,len(heroSkinList) + 1):
# http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/英雄的id值/英雄的id值-bigskin-皮肤编号.jpg
img_url = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/'+str(heroId)+'/'+str(heroId)+'-bigskin-'+str(skin)+'.jpg'
#print(img_url)
#请求图片数据,因为它是一个二进制数据,所以我们需要调用content获取
img_data = requests.get(url=img_url,headers=headers).content
# 4. 保存数据 --- 保存在目标文件夹中
path = '王者荣耀'
if not os.path.exists(path):
os.mkdir(path)
with open('王者荣耀\\'+heroName+"-"+heroSkinList[skin-1]+".jpg",mode='wb') as f:
print("正在下载皮肤:",heroName+"-"+heroSkinList[skin-1])
f.write(img_data)
f.close()
附图

总结
上次使用 java爬取了388张图片,而使用python仅仅爬取到了344张图片,原因是数据包hellolist.json中没有某些皮肤的信息,例如娜可露露-晚萤和不知火舞-魅语。
而Java是在页面的dom元素上算出英雄皮肤的数量,没有通过数据包的方式,因此它包含了这些新出的皮肤。
但使用Java爬取的图片也是不全的,例如就没有马超和西施的图片,而使用python爬取的就有。