版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u011798443/article/details/80988549
1.分析王者荣耀网站
进入游戏资料里的英雄资料:
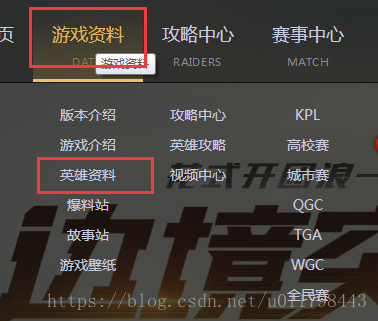
F12进入开发者模式,分析网站,知道网站是异步加载,通过herolist.json来存放所有英雄的信息。

2.贴代码:
import requests
import re
import os
url = 'http://pvp.qq.com/web201605/js/herolist.json'
html = requests.get(url)
html_json = html.json() #转化为json格式
# print(html_json)
#提取名称和数字
hero_name = list(map(lambda x:x['cname'],html_json)) #名字
hero_num = list(map(lambda x:x['ename'],html_json)) #数字
def rongyao() : #用于下载和保存图片
i = 0
for v in hero_num:
os.mkdir('E:\\新建文件夹\\' + hero_name[i]) #创建文件夹
os.chdir('E:\\新建文件夹\\' + hero_name[i]) #打开文件夹
i += 1
for u in range(12):
onehero_links='http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/'+str(v)+'/'+str(v)+'-bigskin-'+str(u)+'.jpg' #图片地址
link = requests.get(onehero_links) #得到链接,并请求链接
if link.status_code == 200 :
img = re.split('-',onehero_links) #截取字符串
open(img[-1],'wb').write(link.content)
rongyao()
3.结果: