前两天看到同学用python爬下来LOL的皮肤图片,感觉挺有趣的,我也想试试,于是决定来爬一爬王者荣耀的英雄和皮肤图片。
首先,我们找到王者的官网http://pvp.qq.com/web201605/herolist.shtml,我们可以在里面找到王者所有的英雄。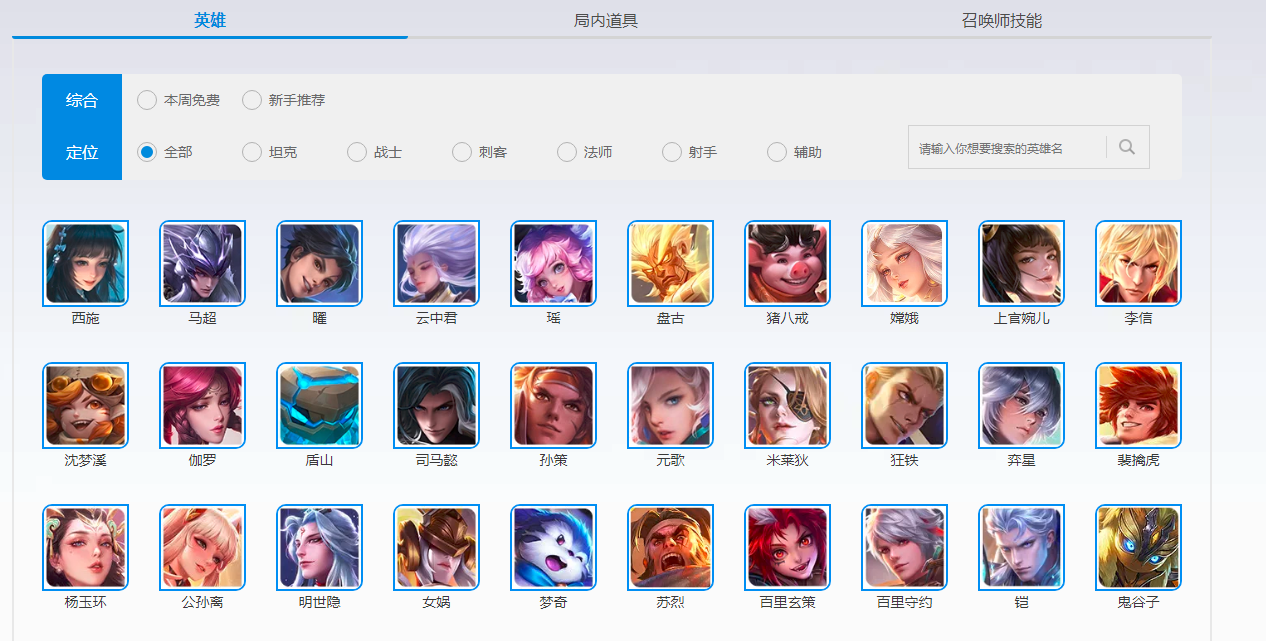
然后,简单的分析一下结构,看看是否有反爬机制。

之后,在上网查阅资料后,发现所有的英雄编号,名字和皮肤都存放在一个叫herolist.json的文件中,但是我打开这个文件却是一堆意义不明的符号,不过这并不影响我们继续。

接下来我们点击进入英雄的详情页面,发现皮肤的地址都是相同格式的
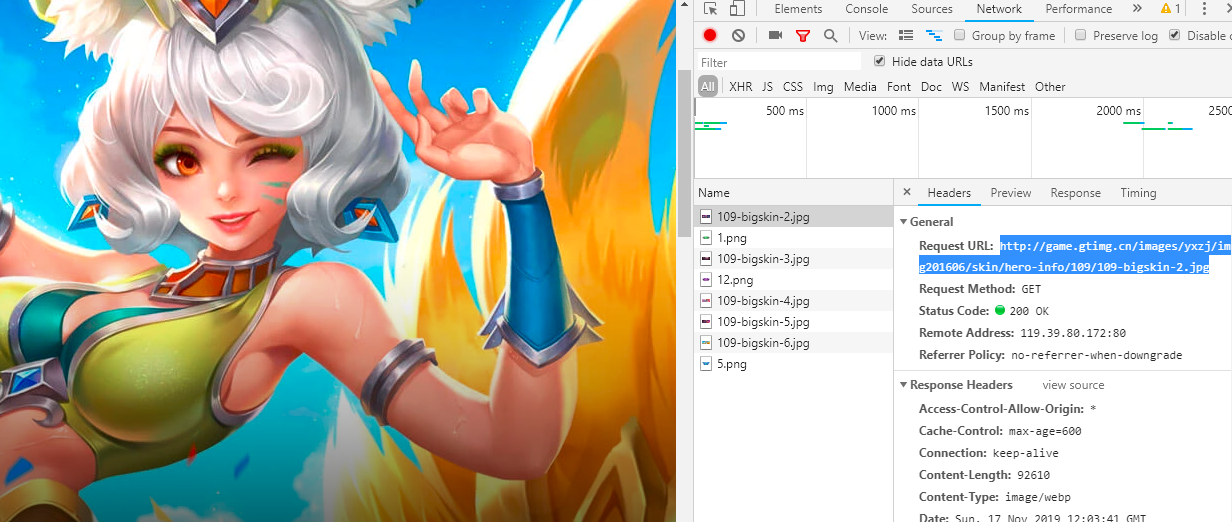
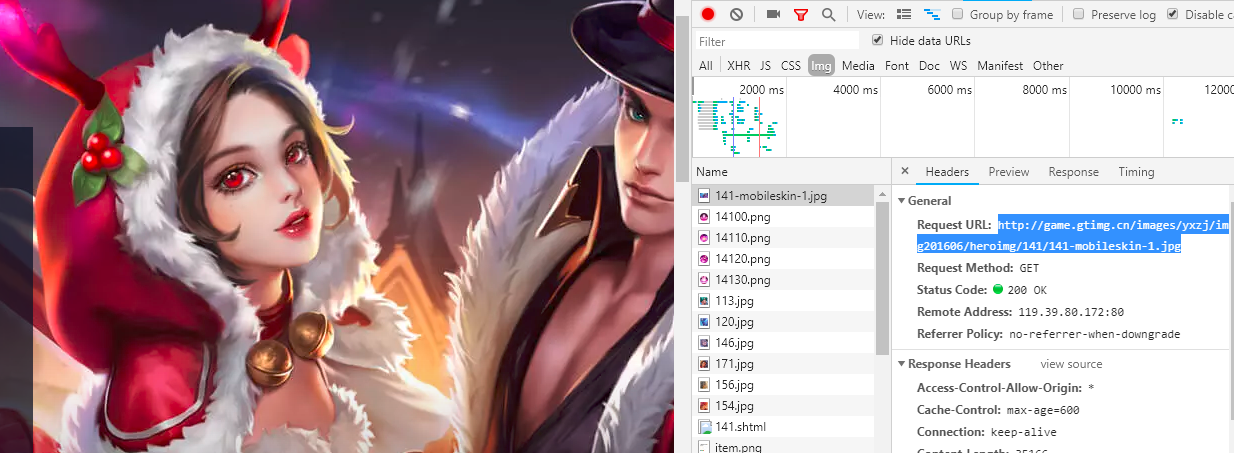
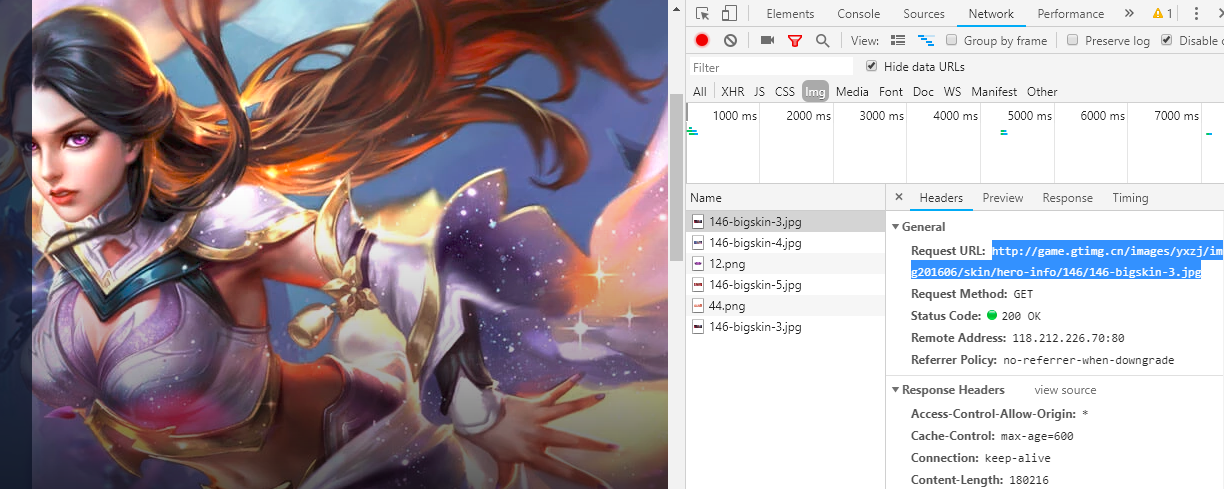
我们不难发现其中的规律,那么接下来我们就要开始写代码了。
完整代码如下:
import requests
import json
import os
import time
start = time.time()
url = requests.get('http://pvp.qq.com/web201605/js/herolist.json').content
jsonFile = json.loads(url) # 提取json
x = 0 # 计数器,记录下载了多少张图片
# 创建目录
hero_dir = 'D:\wzry\wzry'
if not os.path.exists(hero_dir):
os.mkdir(hero_dir)
try: #使用一个简单的异常处理,防止代码在运行时出现错误
for m in range(len(jsonFile) - 1):
ename = jsonFile[m]['ename'] # 编号
cname = jsonFile[m]['cname'] # 英雄名字
skinName = jsonFile[m]['skin_name'].split('|')
skinNumber = len(skinName)
# 下载图片,构造图片网址
for bigskin in range(1, skinNumber + 1):
urlPicture = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' + str(ename) + '/' + str(
ename) + '-bigskin-' + str(bigskin) + '.jpg'
picture = requests.get(urlPicture).content # 获取图片的二进制信息
with open(hero_dir + cname + "-" + skinName[bigskin - 1] + '.jpg', 'wb') as f: # 保存图片
f.write(picture)
x = x + 1
print("正在下载第" + str(x) + "张图片")
except Exception:
print()
else:
print()
下面是我的运行结果