第一次在CSDN上写博客,望大家多多关照。
代码部分主要分为四大块
“”"
这是要用到的库。
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配
import urllib.request
import urllib.error # 指定URL,获取网络数据
import xlwt # 进行excel操作
import sqlite3 # 进行SQLite数据库操作
import json # json类型解码
import requests
import os
1.爬取网页
def ask_url(url):
"""
访问URL
:return:data
"""
# 伪装chrome的请求头
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
}
req = urllib.request.Request(url=url, headers=header)
html = ""
try:
response = urllib.request.urlopen(req)
html = response.read().decode()
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
2.解析数据
刚开始在用正则表达式匹配的英雄的中文名,打印出来的始终是一串bytes类型数据,不能直接显示中文,后来发现匹配到的bytes数据前有一个空数据,打印不显示出来。现在暂时想到的只是将第一个数据剔除,然后剩下的转成16进制,一个个去chr()它。如果有更好的想法,欢迎留言评论。
# 正则表达式匹配查找所有英雄id
find_hero_id = re.compile(r'{"heroId":"(\d*)",') # 英雄id
find_name = re.compile(r'"name":"(.*)","alias') # 英雄名字
find_title = re.compile(r'"title":"(.*)","roles') # title
find_alias = re.compile(r'"alias":"(.*)","title') # 英雄别名
find_roles = re.compile(r'"roles":(.*),"shortBio') # roles
find_skin_id = re.compile(r'"skinId":"(\d*)",') # 皮肤id
find_chromas_BelongId = re.compile(r'"chromasBelongId":"(\d*)",')
def get_data(base_url):
"""
获得数据并解析
:return:
"""
data_list = []
list_url = "https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js"
hero_list = ask_url(list_url)
# 解析网页获取英雄id
js = json.dumps(hero_list, sort_keys=True, ensure_ascii=False, indent=3)
js = json.loads(js, encoding="utf-8")
# print(js)
hero_id = re.findall(find_hero_id, js)
# print(hero_id)
# for i in range(100, 101):
for i in range(len(hero_id)):
data = []
data.append(hero_id[i]) # 添加英雄id
url = base_url + hero_id[i] + ".js"
html = ask_url(url)
# 英雄名字
name = re.findall(find_name, html)[0]
# strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
# split() 方法可以实现将一个字符串按照指定的分隔符切分成多个子串,这些子串会被保存到列表中(不包含分隔符),作为方法的返回值反馈回来
# print(name.strip().split(r'\u'))
# print(name.encode('unicode_escape').decode('utf8'))
temp_name = name.split(r'\u')[1:]
# print(''.join([chr(int(s, 16))for s in temp_name]))
hero_name = ''.join([chr(int(s, 16))for s in temp_name])
data.append(hero_name) # 添加英雄名字
# print(hero_name)
# 英雄title
title = re.findall(find_title, html)[0]
temp_title = title.split(r'\u')[1:]
hero_title = ''.join([chr(int(s, 16))for s in temp_title])
data.append(hero_title)
# print(hero_title)
# 英雄alias
alias = re.findall(find_alias, html)[0]
data.append(alias)
# print(alias)
# 英雄作用
roles = re.findall(find_roles, html)[0]
data.append(roles)
# print(roles)
# 皮肤id
skin_id = re.findall(find_skin_id, html)
chromas_belongid = re.findall(find_chromas_BelongId, html)
for n in range(len(chromas_belongid)):
if chromas_belongid[n] == '0':
base_skin_url = 'https://game.gtimg.cn/images/lol/act/img/skin/big'
skin_url = base_skin_url + skin_id[n] + '.jpg'
data.append(skin_url)
# print(skin_url)
# print(chromas_belongid)
# print(skin_id)
# print(data)
# print(html)
data_list.append(data)
return data_list
3.保存数据
将获取的数据保存成excel格式。这里要用到xlwt库。
数据只获取这些,如果还要获取一些英雄属性(红条,蓝条之类的)可以用正则表达式去匹配他们。
def save_data(data_list, save_path):
"""
保存数据
:return:
"""
# 创建workbook对象
workbook = xlwt.Workbook(encoding='utf-8', style_compression=0)
sheet = workbook.add_sheet('LOL英雄资料', cell_overwrite_ok=True) # 创建工作表
col = ('英雄ID', '英雄名', '别名', '英文名', '作用', '皮肤链接')
for i in range(len(col)):
sheet.write(0, i, col[i])
for m in range(len(data_list)):
print("写入第%d条" % m)
data = data_list[m]
for n in range(len(data)):
sheet.write(m + 1, n, data[n])
workbook.save(save_path)
4.下载图片
这个函数是下载所有的英雄皮肤,每个英雄一个文件夹。
def save_image(data_list):
"""
保存英雄皮肤图片
:return:
"""
save_path = '.\\英雄皮肤'
for i in range(len(data_list)):
data =data_list[i]
print('下载第%d个英雄的图片' % (i + 1))
save_path_temp = save_path + '\\' + data[2]
for j in range(5, len(data)):
r = requests.get(data[j])
# 保存路径是否存在,若不存在则创建文件夹
try:
os.mkdir(save_path_temp)
except Exception as e:
print(e)
save_path_temp_image = save_path_temp + '\\image' + str(j) + '.jpg'
# 下载图片并保存
with open(save_path_temp_image, 'wb') as f:
f.write(r.content)
f.close()
运行程序,下载的皮肤图片。
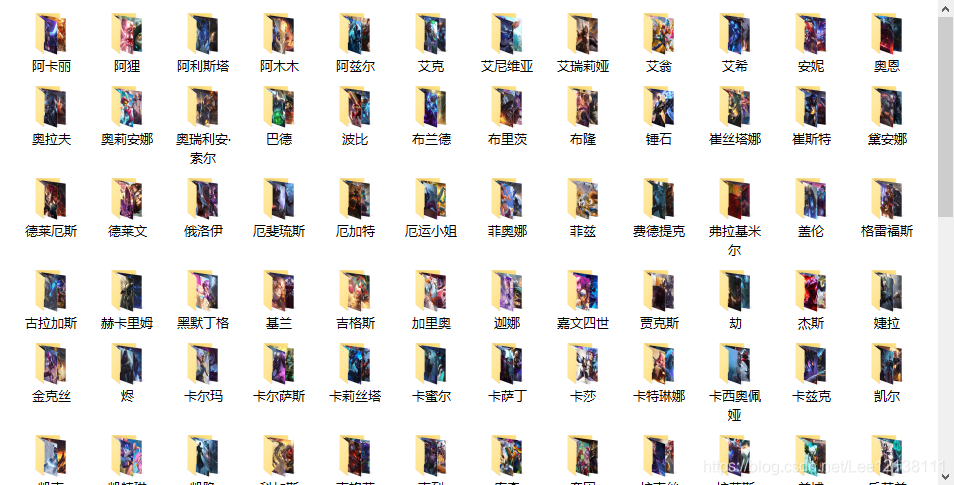
完整的程序正在审核,稍后会给链接。
“”"