编码前准备:
下载好 jsoup.jar包,或者,maven工程导入如下依赖:
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
我们可以先看看maven中对于jsoup的介绍:
jsoup is a Java library for working with real-world HTML. It provides a very convenient API for extracting and manipulating data, using the best of DOM, CSS, and jquery-like methods. jsoup implements the WHATWG HTML5 specification, and parses HTML to the same DOM as modern browsers do.
jsoup是一个用于处理实际HTML的Java库。它提供了一个非常方便的API,可以使用DOM、CSS和类似于jquery的方法来提取和操作数据。jsoup实现了WHATWG HTML5规范,并将HTML解析为与现代浏览器相同的DOM。
好的,我们开始做爬虫前准备:
首先,打开,打开王者荣耀官网:https://pvp.qq.com/
点击英雄资料:
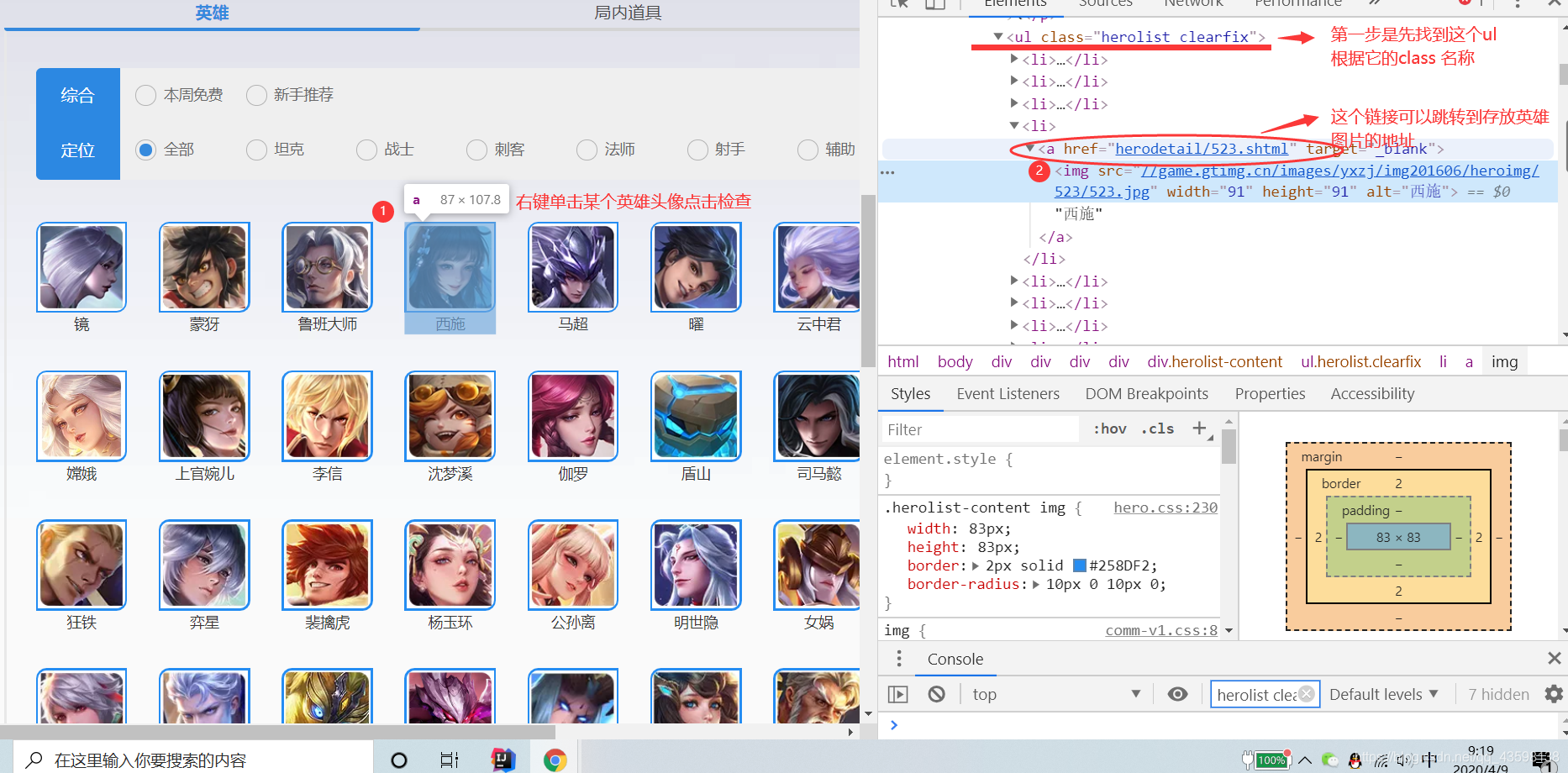
我们要爬取的照片其实存放在a标签中那个href属性中,点击进入:
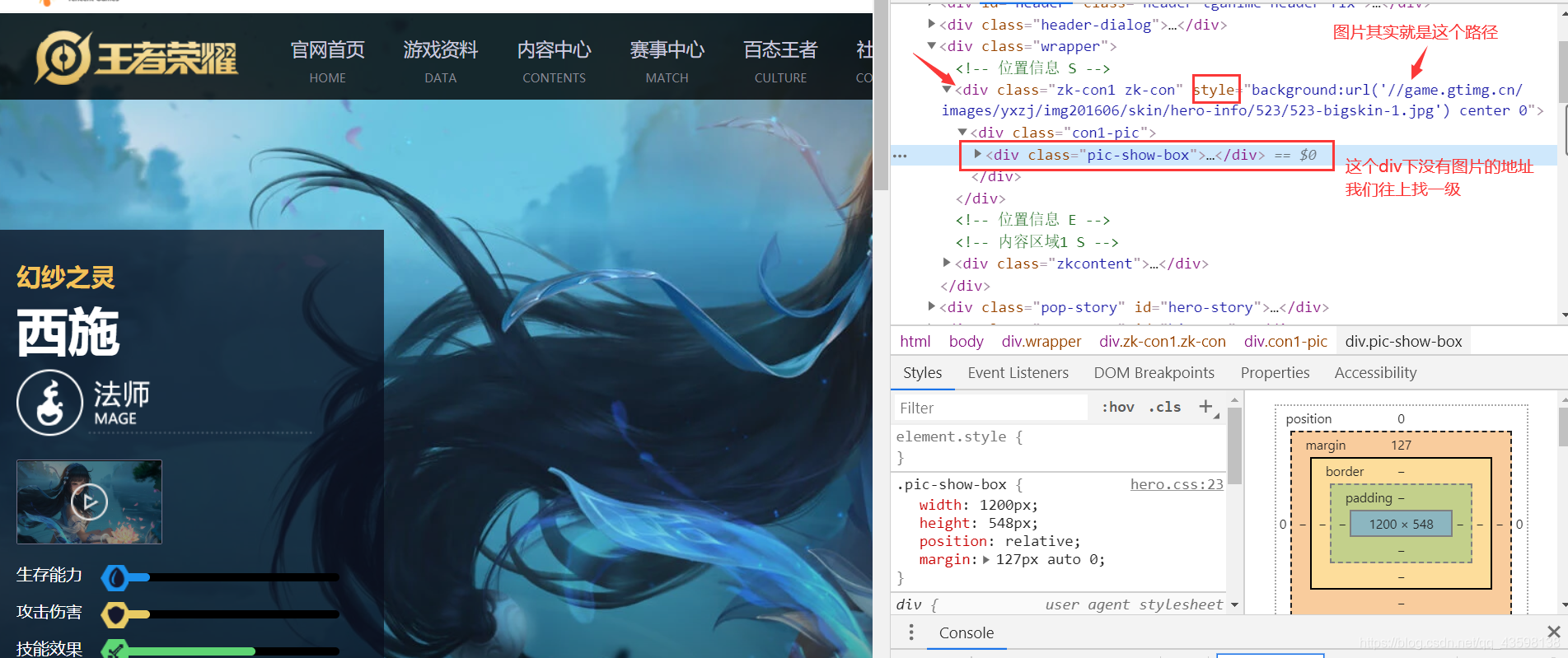
其实这个图片隐藏在它的父辈div中的style属性中,而不是在img标签中包裹的。
好,我们开始爬取照片:
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
public class ReptileHonorOfKingImgs {
public static void main(String[] args) throws IOException {
long t1 = System.currentTimeMillis();
//1.与我们要爬取数据的页面建立连接
Connection connection = Jsoup.connect("https://pvp.qq.com/web201605/herolist.shtml");
long t2 = System.currentTimeMillis();
System.out.println("创建连接的时间:"+(t2-t1)+"毫秒");
//2.通过connection对象获取该网址中的HTML内容---文字、String、标签。Document它们全是文档对象模型
Document document = connection.get();
long t3 = System.currentTimeMillis();
System.out.println("读取document信息所用时间:"+(t3-t2)+"毫秒");
//找到第一个class为herolist clearfix的文档对象
Element elementUL = document.selectFirst("[class=herolist clearfix]");
//通过ul标签找到它下面所有的li子标签,根据标签名查
Elements elementsLis = elementUL.select("li");
int size = 0;//size仅仅用来记录总共下载的图片个数,与循环结束条件无关
//巡官遍历获取到的整个elementsLis集合
for(Element elementLi : elementsLis){
//选中li标签中的a标签
Element elementA = elementLi.selectFirst("a");
//获取a标签中的href属性值--->指向另一个地址,那里包含了我们要爬取的高清大图
String href = elementA.attr("href");//获取标签中的属性值(它这里采用的是相对路径的写法)
//获取a标签中的文字---留着作为我们图片的名字
String imgName = elementA.text();//获取a标签中的text文本值
//利用href抓取的相对路径,做一个字符串拼接,拼接成完整路径
String netPath = "https://pvp.qq.com/web201605/"+href;
//根据新拼接的path,创建一个新的链接,因为这个新的链接才有我们的要获取的图片
Connection newConnection = Jsoup.connect(netPath);
//通过新连接获取到一个新的document对象
Document newDocument = newConnection.get();
//找寻大图片所在的位置---div组件 class="zk-con1 zk-con"
Element div = newDocument.selectFirst("[class=zk-con1 zk-con]");
//获取div中style属性值
String divStyle = div.attr("style");
String backgroundUrl = divStyle.substring(divStyle.indexOf("'")+1,divStyle.lastIndexOf("'"));
//------分割线-------
//3.拿到这个图片的地址后,接下来就是利用 I/O 进行下载了
System.out.println("下载:<<"+imgName+">>,图片路径:-->"+backgroundUrl);
//根据图片的绝对路径,我们创建一个URL对象
URL url = new URL("https:"+backgroundUrl);
//根据这个url地址,创建一个输入流
InputStream inputStream = url.openStream();
//通过这个输入流,我们可以获取到文件的字节信息
//读取文件的字节信息,可将图片保存到本地
//需要一个本地的文件输出流,将刚才的inputStream读取到的字节信息,写在本地,首先需要我们在E盘下手动创建img文件夹
FileOutputStream fileOutputStream = new FileOutputStream("E://img//"+imgName+".jpg");
//需要创建一个byte数组
byte[] b = new byte[1024];
//读取到的数据临时存放在b字节数组内
int count = inputStream.read(b);//count 指的是读取的有效字节个数
while (count!=-1){
fileOutputStream.write(b,0,count);//一个字节一个字节得往里写,直到count==-1
//清空流管道
fileOutputStream.flush();
//再读取下一次
count = inputStream.read(b);//重新计算count的值
}
fileOutputStream.close();
inputStream.close();
size++;
}
long t4 = System.currentTimeMillis();
double time = (double) (t4-t1)/1000;
System.out.println("恭喜您已完成全部下载,共耗时:"+time+"秒,下载图片"+size+"张");
}
}
注释多多,即使小白也能看懂。
爬取全皮肤图片,可以看:Java爬取王者荣耀全英雄全皮肤图片
