KNN算法
一、KNN算法介绍
KNN算法全称是K Nearest Neighbors ,KNN原理就是当预测一个值属于什么分类,根据它最近的K个分类是什么进行预测它属于什么类别。
重点有两个: K 的确定和距离的计算
距离的计算:欧式距离
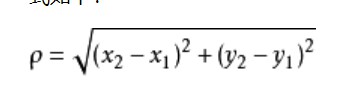
K值的计算:通过交叉验证(将样本数据按照一定的比例拆分成训练用的数据和验证用的数据),从中选取一个较小的K值开始,不断增加K的值,然后计算验证集合方差,最终找到一个比较适合的K值
二、KNN的优缺点
优点:
- 简单易用,相比其他算法,KNN的算法比较简单明了。
- 模型训练较快
- 预测效果好
- 对异常值不敏感
缺点:
对内存要求高,要训练所有的数据
- 预测阶段比较慢
对不相关的功能或者数据规模敏感
三、KNN算法代码实现
3.1. KNN算法主要参数
def KNeighborsClassifier(n_neighbors =5,
weights='uniform',
algorithm ='',
leaf_size = '30',
p=2,
metric = 'minkowski',
metric_params = None,
n_jobs = None
)
'''
- n_neighbors: 这个值就是指Knn中的"K"了,通过调整K值,会有不同的效果
- weights: 权重,最普遍的KNN算法无论距离如何,权重都一样的,但是有时候我们想让距离他更近的点更加重要,这个时候就需要调用weight参数,
这个参数有三个选项: 'uniform':不管远近权重都一样;‘distance':距离目标越近权重越高;自定义函数:自定义一个函数,根据输入坐标值返回权重
- algorithm:在sklearn中,要构建knn模型有三种构建方式:1.暴力法:直接计算距离存储比;2.使用kd树构建knn模型;3:使用球状树构建;4 auto自动
选择 'brute':蛮力实现 ;"kd_tree":kd实现KNN;'ball_tree':球状树实现KNN ; 'auto':默认参数,自动选择合适的方法构建模型
- leaf_size:如果选择蛮力实现,这个值是可以忽略的,当使用kd树,他是控制叶子的阈值,默认为30,但是如果数据增多这个参数需要增大,否则速度过慢,
容易过拟合。
- p: 和metric结合使用,当metric参数是minkowski的时候, p=1为曼哈段,p=2是欧式距离,默认为p=2
- metric: 指定距离的度量方法,一般用欧式距离
'euclidean':欧式距离
'manhattan':曼哈顿距离
'chebyshev':切比雪夫距离
'minkowski':闵可夫斯基距离,默认参数
- n_jobs:指定多少个cpu3.2. KNN算法在鸢尾花数据集上的实现
- 导入数据
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
iris = load_iris()
x = iris.data
y = iris.target- 调参
# 调整K值
k_range = range(1, 31)
score = []
# 循环,查看误差效果
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
# cv 参数决定数据集划分比例,这里是按照5:1划分训练集和测试集
scores = cross_val_score(knn, x, y, cv=6, scoring='accuracy')
score.append(scores.mean())
# 画学习曲线
plt.plot(k_range, score)
plt.xlabel('value of K for KNN')
plt.ylabel('score')
plt.show()
# 可以发现k =11时,效果最好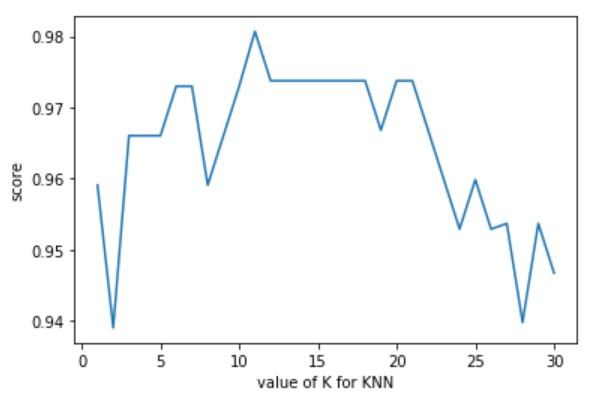
# 调整weights参数
# weights参数
score1 = []
for k in ['uniform', 'distance']:
knn = KNeighborsClassifier(n_neighbors=11,
weights= k)
scores = cross_val_score(knn, x, y, cv=6, scoring='accuracy')
score1.append(scores.mean())
print(score1)
# 选取weights = uniform参数[0.98070987654321, 0.9799382716049383]
- 建模
# 建模
knn = KNeighborsClassifier(n_neighbors=11, weights='uniform')
clf = knn.fit(x, y)
score = cross_val_score(clf, x, y, cv=10).mean()
score