讲授决策树的基本概念,分类与回归树的原理,决策树的表示能力,决策树的训练算法,寻找最佳分裂的原理,叶子节点值的标记,属性缺失与替 代分裂,决策树的剪枝算法,决策树应用。
非常直观和易于理解的机器学习算法,最符合人的直观思维,因为生活中很多时候做决策就是用这种树状结构做决定的。
大纲:
基本概念
分类与回归树
训练算法
寻找最佳分裂
属性缺失与替代分裂
过拟合与剪枝
实验环节
实际应用
基本概念:
①树是一种分层的数据结构,家谱、书的目录就是一棵树的结构。
②树是一个递归的结构,树的每个子节点,以它为根同样是一棵树,所以说树里边的很多算法是用递归来实现的。
有一种特殊的树叫二叉树,每个节点最多只有两个孩子节点,左子节点和右子节点,编程的时候很容易实现,树在编程实现的时候是用指针来实现的,非二叉树预留多少空间存储子节点的指针不好确定,所以编程的时候用的一般是二叉树。
非叶子节点叫做判定节点,叶子节点是决策结果。决策树可以用来做分类,也可以用来做回归。
比如医生看病可能也是用一棵决策树来判定的,这棵判定树的规则是他学习的时候和很多年经验的总结,它的特征向量就是一些体检的指标,如体温、白细胞数量、红细胞数量等等。
整个机器学习和模式识别里边特征分两种类型,一是类别型特征,是不能比较大小的,如是否有房产证,二是数值型特征,是可以比较大小的,如收入多少。
决策树整个判定过程是从根节点开始,依次拿一个特征进行比较,日常生活中这种判定规则是人工总结出来的,决策树是一种机器学习算法,和这个人工的决策有本质的不同,虽然也是判定树,它是通过训练得到的,给定一组样本((x1,y1),(x2,y2),...),可以自动学习出一套规则来做预测,内部节点画为矩形叶子节点画成椭圆形。
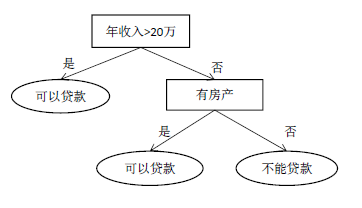
决策树是一种基于规则的方法,用一组嵌套的规则进行预测,在决策节点处,根据判断结果进入一个分支,反复执行这种操作直到到达叶子节点,得到预测结果。这些规则通过训练得到,而不是人工制定的。
决策节点:在这些节点处需要进行判断以决定进入哪个分支,如用一个特征和设定的阈值进行比较。决策节点一定有两个子节点,是内部节点。
叶子节点:表示最终的决策结果,没有子节点。对于分类问题,叶子节点中存储的是类别标签。
分类与回归树:
决策树是一个分层结构,可以为每个节点赋予一个层次数。根节点的层次数为0,子节点的层次数为父节点层次数加1。树的深度定义为所有节点的最大层次数,层次数也表示需要比较的次数。
典型的决策树有ID3,C4.5,CART(Classification and Regression Tree,分类与回归树)等,它们的区别在于树的结构(二叉树还是多叉树)与构造算法(树的训练算法),树训练好之后,预测算法都是一样的,即从根节点到叶子节点判定出结果。
CART分类与回归树是一种二叉树,既支持分类问题,也可用于回归问题。ID3、C4.5是很老的机器学习算法了。
分类树的映射函数是多维空间的分段线性划分,即用平行于各坐标轴的超平面对空间进行切分: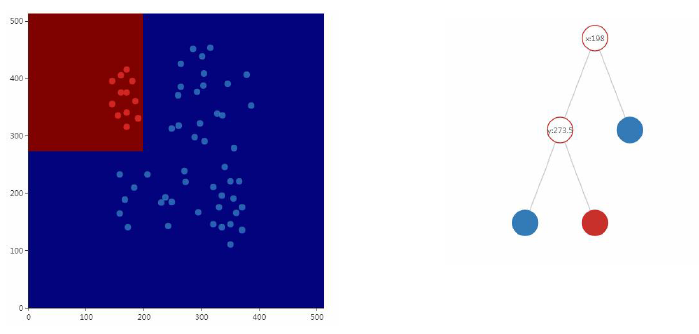
回归树的映射函数是分段常数函数(比分段函数简单,是分段常数函数,某个区间内取某个常数值),决策树是分段线性函数而不是线性函数,它具有非线性建模的能力。
只要划分的足够细,分段常数函数可以逼近闭区间上任意函数到任意指定精度,因此决策树在理论上可以对任意复杂度的数据进行拟合。如把空间分的非常细,就像微积分中的积分一样,在一个小区间内用一个常数值代替,也就是用阶梯函数代替任意一个连续函数都可以达到指定的精度,只要划分的足够细就可以了,即决策树在理论上可以对任意复杂度的数据进行拟合。理论上很美好,实现起来不尽人意,会面临维数灾难,空间维数很高的时候分的很细的话后边会过拟合、泛化性能会急剧下降,虽然理论上可行,但实际运行的时候精度并不高。
对于分类问题,只要同一地方不存在两个样本,决策树足够深的话,反复划分的话它能够把所有的训练样本集正确的分类。对于分类问题,如果决策树深度够大,它可以将训练样本集的所有样本正确分类。
训练算法:
预测算法:从根节点开始,反复用树节点里边存储的规则判定,决定进入左子树还是右子树,直到到达叶子节点得到预测结果。核心问题是这个树怎么建立起来的?是通过训练得到的,训练的依据是(对于有监督的机器学习算法,通用的依据是让它在训练集上的误差最小化),也就是说,让决策树对训练样本都尽可能正确的分类,那么这个树就是好的树。
决策树的训练取决于哪些问题:树是递归结构,所以树是递归的建立起来的。首先根节点是怎么建立的,用所有样本训练根节点,找到一个分裂规则(训练的时候叫做分裂规则,预测的时候叫判定规则),把样本集一分为二,然后用第一个子集训练左边的决策树,第二个子集训练右边的决策树,这样就可以把树创建出来了,这个一个递归的结构。
有几个问题:
①每个决策节点上应该选择哪个分量做判定?这个判定会将训练样本集一分为二,然后用这两个子集构造左右子树。
②判定的规则是什么?即满足什么条件时进入左子树分支。对数值型变量要寻找一个分裂阈值进行判断,小于该阈值进入左子树,否则进入右子树。对于类别型变量则需要为它确定一个子集划分,将特征的取值集合划分成两个不相交的子集,如果特征的值属于第一个子集则进入左子树,否则进入右子树。
③何时停止分裂,把节点设置为叶子节点?对于分类问题,当节点的样本都属于同一类型时停止;对于回归问题,如果这个节点它的训练样本都取同一个值的话,就用这个值代替所有的样本,没有误差,停止分裂。但这样可能会导致树的节点过多、深度过大,产生过拟合问题。为了防止过拟合,一种方法是当节点中的样本数小于一个阀值时停止分裂,另一种是当树达到指定的深度就不让它生长了。
④如何为每个叶节点赋予类别标签或者回归值?即到达叶子节点时样本被分为哪一类或者赋予一个什么实数值。
总共就几个问题,一是递归分裂,核心是怎么寻找一个最佳的分裂出来,就是在训练样本集上通过一次划分之后让创建出来的树对样本集尽可能的分类会回归。二是什么时候停止分裂。三是叶子节点值设置为多少合适。总共叶子节点、内部节点两种情况,以树的深度和整体其他一些控制,这就构成了决策树训练算法的核心。
递归分裂过程
1.用样本集建立根节点,找到一个判定规则,将样本集D分裂成D1和D2两部分,同时为根节点设置判定规则
2.用样本集D1递归建立左子树
3.用样本集D2递归建立右子树
4.如果不能再进行分裂,则把节点标记为叶子节点,同时为它赋值,训练过程在这一步就终止了,退回去再训练其他节点
寻找最佳分裂: