决策树
决策树
决策树是一类常见的机器学习方法,是基于树结构来进行决策的。一般的,一棵决策树包含一个根结点、若干个内部结点和若干个叶结点;叶结点对应于决策结果,其他每个结点则对应于一个属性测试;每个结点包含的样本集合根据属性测试的结果被划分到子节点中;根结点包含样本全集。从根结点到每个叶结点的路径对应了一个判定测试序列。决策树学习的目的是为了产生一棵泛化能力强——即处理未见示例能力强的决策树。其基本流程遵循“分而治之(divide-and-conquer)”的策略。

决策树常用于分类问题,树的根节点包含所有样本,然后根据一定标准选择最优划分属性,对样本集进行划分,得到根节点的子节点,并对每个子节点重复上述过程,直至子节点满足以下三个条件的任意一个,即将子节点设置为叶子节点:
- 当前节点包含的样本全属于同一类别,无需划分;
- 当前属性集为空,或是所有样本在所有属性上取值相同,无法划分;
- 当前节点包含的样本集合为空,不能划分
在上述第1种情况下,我们将当前节点的类别设置为所有样本相同的属性。在第2种情况中,我们将当前节点类别设置成当前节点所含样本最多的类别。在第3种情况中,将当前节点属性设置成其父节点中所含样本最多的类别。
通过上述的介绍,可以发现生成一颗决策树的关键步骤,就是节点切分这个步骤。而节点如何切分,则取决于节点中的样本要根据哪个属性(特征)进行划分,这也就是决策树生成中会遇到的第一个问题。所以我们接下来首先讨论不同算法是如何处理这个特征选取的问题的。紧接着,我们讨论剪枝的问题,我们之前讨论过,过拟合这个问题是无法避免的,因此不同的模型有不同的处理过拟合的方法,我们也讨论一下决策树在面对过拟合时常用的一些策略。接下来,就是讨论一下对于连续值与缺失值的处理,这个在模型应用中是经常会遇到的问题,所以也不能忽视。
划分选择
决策树学习的关键是第8行——如何选择最优划分属性。一般而言,随着划分过程不断进行,我们希望决策树的分支结点包含的样本尽可能属于同一类别,即结点的“纯度”越来越高。
以下将介绍几种常见的决策树划分选择指标以及使用他们的具体算法。假设当前节点的样本集合D中第k类样本所占的比例 (k=1,2,3,…,| |)。嘉定离散属性a有V个可能的取值{ , ,…, },若使用a来对样本集合D进行划分,则会产生V个分支节点,其中第v个分支节点包含了D中所有在属性a上取值为 的样本,记为 。

剪枝
过拟合产生的原因
在决策树学习的过程中,为了尽可能正确分类训练样本,节点划分过程将不断重复,有时会造成决策树分支过多,这时就可能因训练样本学的“太好”了,以至于把训练集自身的一些特点当做所有数据都具有的一般性质而导致过拟合。
常用剪枝方法
| 方法名称 | 策略 | 优点 | 缺点 |
|---|---|---|---|
| 预剪枝 | 在决策树生成的过程中,对每个节点在划分前先进行估计,若当前节点的划分不能带来决策树泛化性能提升,则停止划分并将当前节点标记为叶节点 | 1. 降低过拟合风险;2. 显著减少了决策树的训练时间开销和测试时间开销。 | 基于“贪心”本质禁止这些分支展开,给预剪枝决策树带来了欠拟合的风险 |
| 后剪枝 | 先从训练集生成一棵完整的决策树,然后自底向上地对非叶节点进行考察,若将该节点对应的子树替换为叶节点能带来决策树泛化能力提升,则将该子树替换为叶节点 | 1. 欠拟合风险小;2. 泛化能力一般优于预剪枝决策树。 | 训练时间开销比未剪枝决策树和预剪枝决策树都要大很多 |
预剪枝的策略十分明确,但后剪枝的策略则比较多样性,如何去确定将非叶节点的子树替换成叶节点后泛化能力是否提升,以怎样的顺序去遍历非叶节点等不同的策略都可能产生不同的决策树。
连续值与缺失值处理
连续值处理
对于离散属性而言,每个属性的可能取值数量是固定的,以该属性划分样本集合能产生的分支的数量也是确定且有限的。但是实际应用中,我们更多碰到的是连续属性,即样本在该属性上的值是一个实数,此时我们根据该属性进行划分的分支数不像离散属性一样是有限的,因此我们要采取其他策略来应对连续属性。
给定样本集D和连续属性a,假定a在D上出现了n个不同的取值,将这些值从小到大进行排序,记为{ , , ,…, }。我们考虑根据该属性值可以将样本集合划分成n-1个子样本集合,而这n-1个划分的划分点则是 ,这个划分点也称位跳跃点。根据某个跳跃点t,我们可以将样本在属性a上取值小于跳跃点的划分到 ,大于等于跳跃点的样本划分到 ,则每个跳跃点都只会产生两个子分支。
除了以上差别以外,连续属性和离散属性还存在一点不一样,即若当前节点划分属性为连续属性,该属性还可作为其后代节点的划分属性。举个例子,加入样本有离散属性a,连续属性b,那么如果根节点根据属性a进行划分了,根节点的所有子孙节点都不再考虑根据a进行划分。但如果根节点根据属性b进行划分了,那么根节点的子孙节点在选择划分时仍然可以考虑属性b。
缺失值处理
现实任务中中常会遇到不完整样本,即样本的某些属性值确实。面对这样的数据集,如果我们直接抛弃掉所有存在缺失值的样本的话,对数据信息而言是极大的浪费。因此,我们需要考虑如何处理这些存在缺失值的样本。在考虑这个问题时,我们主要思考如何解决以下两个问题:
- 如何在属性值确实的情况下进行划分属性选择?
- 给定划分属性,若样本在该属性上的值确实,如何对样本进行划分?
给定训练集D和属性a,令 表示D中在属性a上没有缺失值得样本子集。对问题1,显然我们仅可根据 来判断属性a的优劣。假定我们为每个样本x赋予一个权重 ,并定义
基于上述定义,我们可以将信息增益的公式推广为
其中
。
对于问题2,如果样本x在划分属性a上的取值已知,则将x划入与其取值对应的子节点,且样本权值在子节点中保持为
。若样本在划分属性a上的取值未知,则将x同时划入所有子节点,且样本权值在于属性值
对应的子节点中调整为
。直观的看,就是让同一个样本以不同的概率划入到不同的子节点中。
p.s. 所有样本所有属性的权重
的初始值都设为1
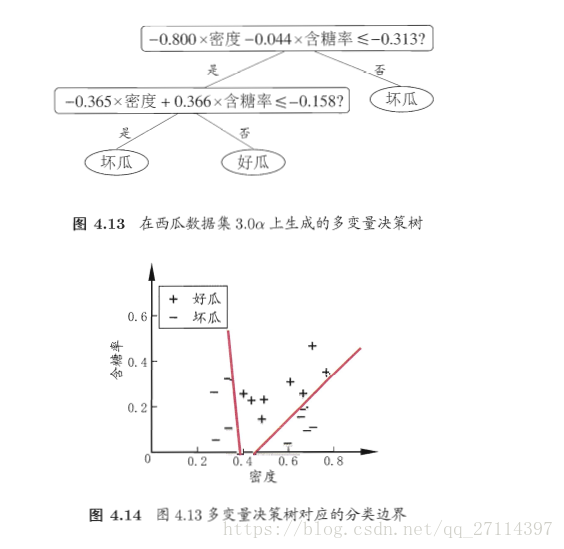
多变量决策树
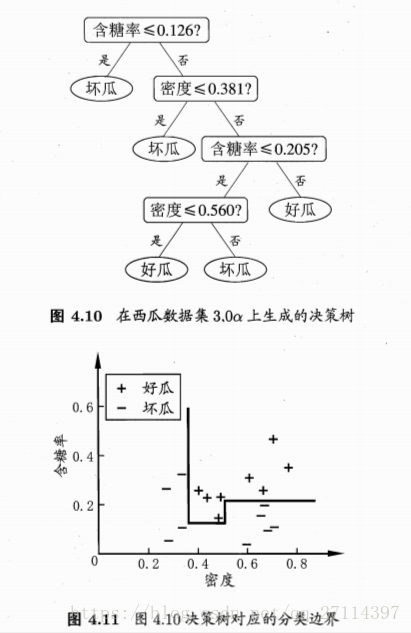
若把每个属性视为坐标空间中的一个坐标轴,则 d 个属性描述的样本就对应了 d 维空间中的一个点,对样本分类则意味着在这个坐标空间中寻找不同样本之间的分类边界。
决策树所形成的分类边界有一个明显的特点:轴平行(axis-paraller),即它的分类边界由若干个坐标轴平行的分段组成。
例如:
类器。

ID3 决策树
ID3 决策树实现
- 导入需要用到的python库
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
- 导入数据集
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values
y = dataset.iloc[:, 4].values
- 将数据集拆分为训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
- 特征缩放
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
- 对测试集进行决策树分类拟合
from sklearn.tree import DecisionTreeClassifier
classifier = DecisionTreeClassifier(criterion = 'entropy', random_state = 0)
classifier.fit(X_train, y_train)
- 预测测试集的结果
y_pred = classifier.predict(X_test)
- 制作混淆矩阵
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
- 将训练集结果进行可视化
from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Decision Tree Classification (Training set)')
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
plt.legend()
plt.show()
- 将测试集结果进行可视化
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Decision Tree Classification (Test set)')
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
plt.legend()
plt.show()