1、什么是逻辑回归;
2、逻辑回归的流程及推导;
3、逻辑回归的多分类
4、逻辑回归VS线性回归
5、逻辑回归 VS SVM
1、什么使逻辑回归;
名为回归,实际是分类,通过计算$P(y=0|x;\theta )$的大小来预测分类类别,预测的是类别0,1,而不是概率,但计算的是概率;$0\leq P(y=0|x;\theta )\leq 1$,是个概率值,本身并没有非0即1的概念;
二项逻辑回归:x是输入,y是输出;
$P(y=0|x)=\frac{1}{1+e^{-z}}$
$P(y=0|x)=\frac{1}{1+e^{-(\omega x+b)}}$

$P(y=1|x;\theta )+P(y=0|x;\theta )=1$
$z=\omega x+b$
$\frac{\partial z}{\partial w}=x$
$\frac{\partial z}{\partial b}=1$
logistic :对数几率函数
几率:发生的概率p/不发生的概率1-p$\frac{p}{1-p}$
对数几率:$logit(p)=\log \frac{p}{1-p}=\omega x$
$\omega x+b=0$即决策边界;
当p>1-p时,$ \frac{p}{1-p}>1$,$\log \frac{p}{1-p}>0$,即$\omega x>0$;
当p<1-p时,$ \frac{p}{1-p}<1$,$\log \frac{p}{1-p}<0$,即$\omega x<0$;
$z=\omega x+b$
当$z\geq 0$时,$g(z)\geq 0.5$,$y=1$
当$z< 0$时,$g(z)< 0.5$,$y=0$
2、逻辑回归的流程及推导;
模型参数估计:(用似然函数估计模型参数)
损失函数:$\prod_{i=1}^{N}p^{y_{i}}(1-p)^{1-y_{i}}$(此形式被称为交叉熵损失)
写对数似然函数,求其最大值;
梯度下降法,求w;
带入P(y=k|x;\theta )进行分类;
推导:
似然函数:$L=p^{y_{i}}(1-p)^{1-y_{i}}$
对数似然函数:$L=p{y_{i}}+(1-p)({1-y_{i}})$
从求对数似然函数的最大值,转换成求最小值:
$L=-(p{y_{i}}+(1-p)({1-y_{i}}))$
通过梯度下降法来求:
$\frac{\partial L}{\partial p}=-\frac{y_{i}}{p}+\frac{1-y_{i}}{1-p}$
$p=\frac{1}{1+e^{-z}}$
$\frac{\partial p}{\partial z}=\frac{e^{-z}}{(1+e^{-z})^{2}}=p(1-p)$
$\frac{\partial z}{\partial w}=x$
$\frac{\partial z}{\partial b}=1$
$dw=(p-y_{i})x$
$db=(p-y_{i})$
3、逻辑回归的多分类
方法一:相当于做N个两分类:
1VS23,$h_{\theta }^{1}(x)$
2VS13,$h_{\theta }^{2}(x)$
3VS12;$h_{\theta }^{3}(x)$
求最大的$h_{\theta }^{i}(x)$对应的类别;
方法二:把sigmoid函数换成softmax
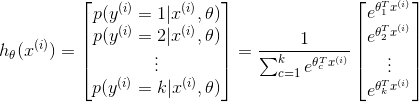
这时候,softmax回归算法的代价函数如下所示(其中):
很明显,上述公式是logistic回归损失函数的推广。
我们可以把logistic回归的损失函数改为如下形式:
然后再用梯度下降法求就可以了。
4、逻辑回归VS线性回归
线性回归:
$f(x_{i})=\omega x_{i}+b$,使得$y_{i}\approx f(x_{i})$
最小二乘法求参数
线性回归一般用平方差误差函数(源于极大似然估计),
但对于逻辑回归它是非凸函数,只有局部最优解;
逻辑回归代价函数用交叉熵(源于极大似然估计),原因:凸函数,有全局最优解;
不同点:
1、逻辑回归分类,线性回归是回归;
2、逻辑回归因变量是离散的,线性回归因变量是连续的;
逻辑回归并不是线性回归加激活函数
$h_{\theta }(x)=g(\theta _{0}+\theta _{1}x_{1}+\theta _{2}x_{2}+\theta _{3}x_{1}^{2}+\theta _{3}x_{2}^{2})$
通过在特征中使用多项式,可以得到更多更复杂的边界,而不只是线性划分;
决策边界不是训练集的属性,而是假设本身$h_{\theta }(x)$及其参数的属性;
非线性模型,但本质是线性分类模型;
线性回归上添加sigmoid映射,估计$P(y=1|x)$的概率来分类;
$\omega x+b=0$为决策边界,分为实现线性的;
例如:
$\theta _{0}+\theta _{1}x_{1}+\theta _{2}x_{2}=0$
$\theta _{0}+\theta _{1}x_{1}^{2}+\theta _{2}\sqrt{x_{2}}=0$
看似不是线性的,但只是对变量做了变化;
如$t_{1}=x_{1}^{2},t_{2}=\sqrt{x_{2}}$
$\theta _{0}+\theta _{1}t_{1}+\theta _{2}t_{2}=0$
5、逻辑回归 VS SVM
$$g(z)=\frac{1}{1+e^{-z}}$$
$$P(y=0|x;\theta )=\frac{1}{1+e^{-(wx+b)}}$$
$h(x)=$对于输入x,预测结果为1的概率(参数为$\theta$时)$=P(y=1|x;\theta )$
LR也可以像SVM一样,用kernel进行变量转换,解决分线性问题;
但LR易过拟合,因为LR的VC维随变量线性增长;
SVM不易过拟合,因为SVM的VC维随变量对数级增长;