目录
- KNN原理
- 某些API解释
- KNN实现
- 作业问题记录
- 行业运用
- 算法改进
- 参考文献
一、KNN原理
KNN是一种投票机制,依赖少数服从多数的原则,根据最近样本的标签进行分类的方法,属于局部近似。
优点:
1.简单(原因在于几乎不存在训练,测试时直接计算);
2.适用于样本无法一次性拿到的情况;
3.KNN是根据周围邻近样本的标签进行分类的,所以适合于样本类别交叉或重叠较多的情况;
缺点:
1.测试时间太长,需要计算所有样本与测试样本的距离,因此需要提前去除对分类结果影响不大的样本;
2.不存在概率评分,仅根据样本标签判别;
3.当不同类别的样本数目差异较大时,数目较大的那一类别对KNN判别结果影响较大,因此可能产生误判;
4.无法解决高维问题
二 .某些API解释
1. plt.rcParams
作用:设置matplotlib的配置参数
例子:
%matplotlib inline
plt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'2. auto_reload
作用:在调试的过程中,如果代码发生更新,实现ipython中引用的模块也能自动更新。
例子:
%load_ext autoreload
%autoreload 2详情:
3. np.flatnonzero()
作用:矩阵扁平化后返回非零元素的位置
例子:
import numpy as np
x = np.arange(-2,3)
print x
y = np.flatnonzero(x)
print y结果:
[-2 -1 0 1 2]
[0 1 3 4]
np.flatnonzero(y_train == y)
作用:找出标签中y类的位置
例子:
z = np.flatnonzero(x == -1)
print z结果:
[1]4. np.random.choice
原型:numpy.random.choice(a, size=None, replace=True, p=None)作用:随机选取a中的值
详解:
| 参数 | 参数意义 |
|---|---|
| a | 为一维数组或者int数据; |
| size | 为生成的数组维度; |
| replace | 是否原地替换; |
| p | 为样本出现的概率; |
例子:
print(np.random.choice(7,4)) #[0 6 4 6]解释:在0-7之间随机选取4个数。等同于np.random.randint(0,7,4)
print(np.random.choice(7,4,p=[0,0.1,0.3,0.2,0,0.2,0.2])) 解释:p中的值对应a中每个值的概率。
5.reshape中-1
作用:自动计算数组列数或行数
# Reshape the image data into rows
X_train = np.reshape(X_train, (X_train.shape[0], -1))
X_test = np.reshape(X_test, (X_test.shape[0], -1))
print(X_train.shape, X_test.shape)输出:
(5000, 3072) (500, 3072)
6. np.linalg.norm
原型:
x_norm=np.linalg.norm(x, ord=None, axis=None, keepdims=False)作用:求范数(详见参考连接)
例子:
difference = np.linalg.norm(dists - dists_two, ord='fro')
print('Difference was: %f' % (difference, ))
if difference < 0.001:
print('Good! The distance matrices are the same')
else:
print('Uh-oh! The distance matrices are different')输出:
Difference was: 0.000000
Good! The distance matrices are the same
说明:为了保证向量化的代码运行正确,将运行结果与之前的结果对比。对比两个矩阵是否相等有很多方法,其中较简单的一种就是使用Frobenius范数。其表示的是两个矩阵所有元素的差值的均方根。或者将两个矩阵reshape成向量后,计算其欧式距离。
7. *args, **kwargs
*args表示任何多个无名参数,它是一个tuple
**kwargs表示关键字参数,它是一个dict
例子:
def foo(*args,**kwargs):
print('args=',args)
print('kwargs=',kwargs)
print('************')
foo(1,2,3)
foo(a=1,b=2,c=3)
foo(1,2,a=3)输出:
args= (1, 2, 3)
kwargs= {}
************
args= ()
kwargs= {'a': 1, 'c': 3, 'b': 2}
************
args= (1, 2)
kwargs= {'a': 3}
************
例子:
# Let's compare how fast the implementations are
def time_function(f, *args):
"""
Call a function f with args and return the time (in seconds) that it took to execute.
"""
import time
tic = time.time()
f(*args)
toc = time.time()
return toc - tic
two_loop_time = time_function(classifier.compute_distances_two_loops, X_test)
print('Two loop version took %f seconds' % two_loop_time)8. np.vstack() / np.hstack()
作用:
np.vstack(): 沿着竖直方向将矩阵堆叠起来
np.hstack(): 沿着水平方向将数组堆叠起来
9. np.argsort(dist[i])
作用:将dist[i]中的元素从小到大排列,提取其对应的index(索引),然后输出。
10. np.bincount
作用:统计次数
numpy.bincount(x, weights=None, minlength=None)举例:
y_pred[i] = np.argmax(np.bincount(closest_y))解释:统计closest_y中每一项标签出现的次数,再输出最大次数的closest_y标签。
三.KNN原理
1. compute_distances_two_loops
原理:双循环就是分别计算每个训练数据和每个测试数据之间的距离,第一层循环是对所有测试数据的循环,第二层循环是对所有训练数据的循环,使用np.linalg.norm()函数。

def compute_distances_two_loops(self, X):
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in range(num_test):
for j in range(num_train):
#####################################################################
# TODO: #
# Compute the l2 distance between the ith test point and the jth #
# training point, and store the result in dists[i, j]. You should #
# not use a loop over dimension. #
#####################################################################
dists[i,j] = np.sqrt(np.dot(X[i] - self.X_train[j],X[i] - self.X_train[j]))
#dists[i,j] = np.linalg.norm(X[i] - self.X_train[j])
#####################################################################
# END OF YOUR CODE #
#####################################################################
return dists2. compute_distances_one_loop
原理:单次循环是将每个测试数据通过一次计算就得到和所有训练数据的距离,其利用了broadcast原理。注意参数axis的设置,axis=1是行相减。

def compute_distances_one_loop(self, X):
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in range(num_test):
#######################################################################
# TODO: #
# Compute the l2 distance between the ith test point and all training #
# points, and store the result in dists[i, :]. #
#######################################################################
dists[i,:] = np.linalg.norm(X[i,:] - self.X_train[:], axis = 1)
#######################################################################
# END OF YOUR CODE #
#######################################################################
return dists
3. compute_distances_no_loops
原理:假设测试集是P(m*d),训练集是C(n*d),其中m是测试数据数量,n是训练数据数量,d是维度。计算两者公式如下:
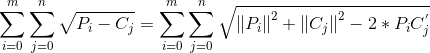
其中,P的形状为m*1,C的形状为1*n。
def compute_distances_no_loops(self, X):
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
#########################################################################
# TODO: #
# Compute the l2 distance between all test points and all training #
# points without using any explicit loops, and store the result in #
# dists. #
# #
# You should implement this function using only basic array operations; #
# in particular you should not use functions from scipy. #
# #
# HINT: Try to formulate the l2 distance using matrix multiplication #
# and two broadcast sums. #
#########################################################################
dists += np.sum(np.multiply(X, X), axis = 1, keepdims = True).reshape(num_test, 1)
dists += np.sum(np.multiply(self.X_train, self.X_train), axis = 1, keepdims = True).reshape(1, num_train)
dists += -2 * np.dot(X, self.X_train.T)
dists = np.sqrt(dists)
#########################################################################
# END OF YOUR CODE #
#########################################################################
return dists4. 交叉验证
for k in k_choices:
accuracies = []
for fold in xrange(num_folds):
#X_v = X_train_folds[j]
#y_v = y_train_folds[j]
#X_tr = np.vstack(X_train_folds[0:j] + X_train_folds[j+1:])
#y_tr = np.hstack(y_train_folds[0:j] + y_train_folds[j+1:])
X_tr = X_train_folds[:]
y_tr = y_train_folds[:]
X_v = X_tr.pop(fold)
y_v = y_tr.pop(fold)
X_tr = np.array([y for x in X_tr for y in x])
y_tr = np.array([y for x in y_tr for y in x])
classifier.train(X_tr, y_tr)
dists = classifier.compute_distances_no_loops(X_v)
y_test_pred = classifier.predict_labels(dists, k)
num_correct = np.sum(y_test_pred == y_v)
accuracies.append(float(num_correct) * num_folds / num_training)
k_to_accuracies[k] = accuracies该部分代码解释:
import numpy as np
num_folds = 3
X_train =[1,2,3,4,5,6,7,8,9]
y_train = [10,20,30,40,50,60,70,80,90]
X_train_folds = np.array_split(X_train, num_folds)
y_train_folds = np.array_split(y_train, num_folds)
print(X_train_folds)
print(y_train_folds)
print ('******************')
for fold in xrange(num_folds):
X_tr = X_train_folds[:]
y_tr = y_train_folds[:]
X_v = X_tr.pop(fold)
y_v = y_tr.pop(fold)
X_tr = np.array([y for x in X_tr for y in x]) #将剩余部分组合成一个数组
y_tr = np.array([y for x in y_tr for y in x])
print(X_tr,y_tr)
print(X_v,y_v)
print ('***')结果:
[array([1, 2, 3]), array([4, 5, 6]), array([7, 8, 9])] [array([10, 20, 30]), array([40, 50, 60]), array([70, 80, 90])] ****************** (array([4, 5, 6, 7, 8, 9]), array([40, 50, 60, 70, 80, 90])) (array([1, 2, 3]), array([10, 20, 30])) *** (array([1, 2, 3, 7, 8, 9]), array([10, 20, 30, 70, 80, 90])) (array([4, 5, 6]), array([40, 50, 60])) *** (array([1, 2, 3, 4, 5, 6]), array([10, 20, 30, 40, 50, 60])) (array([7, 8, 9]), array([70, 80, 90])) ***
四.作业问题记录
1.
Inline Question #1: Notice the structured patterns in the distance matrix, where some rows or columns are visible brighter. (Note that with the default color scheme black indicates low distances while white indicates high distances.)
- What in the data is the cause behind the distinctly bright rows?
- What causes the columns?

Answer: 某些行颜色偏浅,说明该测试样本和所有训练样本的差异较大,该测试样本可能明显过亮或过暗或有色差,或者训练数据可能有坏点。 某些列颜色偏浅,说明所有测试样本和该训练样本的差异较大,该训练样本可能明显过亮或过暗或有色差。
2.
Inline Question 2 We can also other distance metrics such as L1 distance. The performance of a Nearest Neighbor classifier that uses L1 distance will not change if (Select all that apply.):
- The data is preprocessed by subtracting the mean.
- The data is preprocessed by subtracting the mean and dividing by the standard deviation.
- The coordinate axes for the data are rotated.
- None of the above.
Your Answer:1,2
Your explanation:1和2对坐标值的变换都是线性的,如果变换前(x+y+z+...)最小,则变换后(kx+ky+kz+...)也是最小,因此使用L1距离结果不会改变。3是坐标轴旋转,L1距离会变化,L2距离不会。L2距离是[x1,y1]=[[cosβ,sinβ],[-sinβ cosβ]][x,y]T ,即x1=xcosβ+ysinβ,y1=-xsinβ+ycosβ,L2距离不变。L1各向量有具体含义,L2没有。在面对两个向量之间的差异时,L2比L1更加不能容忍这些差异。相对于1个巨大差异,L2距离更倾向于多个中等程度的差异。
3.
Inline Question 3 Which of the following statements about kk-Nearest Neighbor (kk-NN) are true in a classification setting, and for all kk? Select all that apply.
- The training error of a 1-NN will always be better than that of 5-NN.
- The test error of a 1-NN will always be better than that of a 5-NN.
- The decision boundary of the k-NN classifier is linear.
- The time needed to classify a test example with the k-NN classifier grows with the size of the training set.
- None of the above.
Your Answer: Statements 1,4 are true
Your explanation:
Inline Question 3 Which of the following statements about kk-Nearest Neighbor (kk-NN) are true in a classification setting, and for all kk? Select all that apply.
- The training error of a 1-NN will always be better than that of 5-NN.
- The test error of a 1-NN will always be better than that of a 5-NN.
- The decision boundary of the k-NN classifier is linear.
- The time needed to classify a test example with the k-NN classifier grows with the size of the training set.
- None of the above.
Your Answer: Statements 1,4 are true
Your explanation:
1: 当k=1时表示只有最近的点做判断的依据,因此训练没有误差,k=5的时候,根据vote的规则不同,会有不一样的训练误差。
2: k越小,如果某些数据存在噪声,过拟合,则泛化能力就差,因此k=1不一定优于k=5;
3: 首先,Knn不是线性分类器,因为输入和输出没有线性关系,其次,knn的分界面是由很多小的线性空间组成,分界面局部是线性的;
4: 搜索的量增大。
4. 结果讨论
Two loop version took 24.132196 seconds
One loop version took 45.021950 seconds
No loop version took 0.465832 seconds原因:
一次循环是每次开内存空间导致时间比二次循环长。具体来说,一层循环会做很多broadcast,该机制开辟空间的耗时很高,因此是该结果。
五、行业运用
待补充
六、算法改进
待补充
参考文献: